



 本文详细介绍爬虫技术的应用,包括可爬取的数据类型如文本、图片、视频等,数据解析方法如JSON、正则表达式、BeautifulSoup等,以及数据保存方式。同时探讨了网页动态加载对抓取的影响及解决方案。
本文详细介绍爬虫技术的应用,包括可爬取的数据类型如文本、图片、视频等,数据解析方法如JSON、正则表达式、BeautifulSoup等,以及数据保存方式。同时探讨了网页动态加载对抓取的影响及解决方案。
能爬取什么样的数据
网页文本:如HTML文档,Json格式化文本等
图片: 获取到的是二进制文件,保存为图片格式
视频: 同样是二进制文件
其他: 只要请求到的,都可以获取
如何解析数据
- 直接处理
- Json解析
- 正则表达式处理
- BeautifulSoup解析处理
- PyQuery解析处理
- XPath解析处理
抓取的页面数据和浏览器里看到的不一样的问题
因为很多网站中的数据都是通过js,ajax动态加载的,所以直接通过get请求获取的页面和浏览器显示的不同。
如何解决js渲染问题:
分析ajax
Selenium/webdriver
Splash
PyV8,Ghost.py
保存数据
文本: 纯文本,Json,Xml等
关系型数据库: Mysql,oracle,sql server等结构化数据库
非关系型数据库:MongoDB,Redis等key-value形式存储
urllib
官方文档:https://docs.python.org/zh-cn/3/library/urllib.html
urllib介绍
Urllib是python内置的HTTP请求库,是python提供的一个用于发起和处理http请求和响应的框架。
后期的一些框架,比如: requests、 scrapy等都是基于它
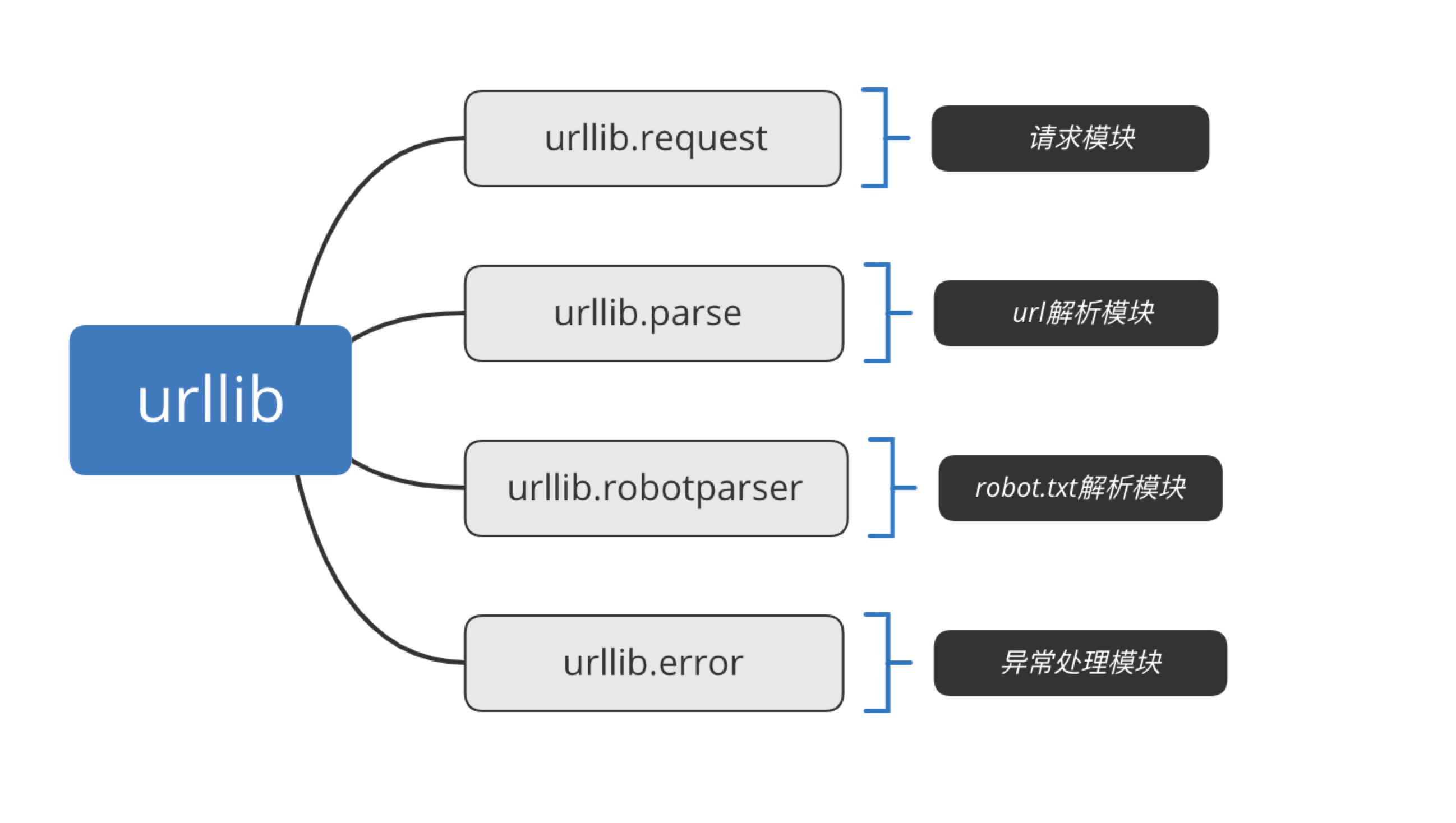
包括以下四个模块:
urllib.error 异常处理模块
urllib.request 请求模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块

















 2441
2441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









