







什么是NCCL
简介
NCCL (NVIDIA Collective Communications Library,NVIDIA 集群通信) 是 NVIDIA 专为 GPU设计用于 GPU 之间高性能通信的库。
深度学习模型规模巨大,需要将模型或数据分割到多个 GPU 上进行并行训练,NCCL 就是干这个的。它主要解决以下问题:
- 在多 GPU 训练场景下实现高效的数据交换
- 自动识别并优化 GPU 间的通信拓扑
- 提供标准化的集合通信接口
- 支持机内(单机多卡)和机间(多机多卡)通信
NCCL 的原理
以下摘自:NCCL 前言 - https://www.cnblogs.com/sys-123456/p/18655886
GPU之间通信的两种类型:机器内通信与机器间通信。
机器内通信:
一、GPU Direct Shared Memory(2010年6月引入):共享内存(QPI/UPI),比如:CPU与CPU之间的通信可以通过共享内存。GPU 之间进行数据交换时,过程:
1 GPU1 的数据将首先通过 CPU 和 PCIe 总线复制到共享内存。
2 数据将通过 CPU 和 PCIe 总线从共享内存复制到目标 GPU0。
-
数据在到达目的地之前需要被复制两次。

二、GPU Direct P2P(2011年)
有了 GPU Direct P2P 通信技术后,将数据从源 GPU 复制到同一节点中的另一个 GPU 不再需要将数据临时暂存到主机内存中。
-
如果两个 GPU 连接到同一 PCIe 总线,GPUDirect P2P 允许访问其相应的内存,而无需 CPU 参与。前者将执行相同任务所需的复制操作数量减半。

NVLink
NVLink是NVIDIA开发的一种高速互连技术,它提供了比传统PCIe更高的带宽和更低的延迟。通过NVLink,GPU之间的数据传输不再通过PCIe总线,而是直接通过NVLink连接。NVLink通过NVSwitch设备实现多GPU之间的全互联,这对于高性能计算和深度学习应用中的大规模并行处理尤为重要。通常是GPU与GPU之间的通信,也可以用于CPU与GPU之间的通信。
PCIe
通常是CPU与GPU之间的通信。
机器间通信:
一、GPU Direct Storage
在 NVIDIA GPU Direct 远程直接内存访问技术不可用的多节点环境中,在不同节点的两个 GPU 之间传输数据需要 5 次复制操作:
1 将数据从源 GPU 传输到源节点中的主机固定内存缓冲区时,发生第一个副本。
2 然后,该数据将复制到源节点的 NIC (网卡)驱动程序缓冲区。
3 在第三步中,数据通过网络传输到目标节点的 NIC 驱动程序缓冲区。
4 将数据从目标节点 NIC 的驱动程序缓冲区复制到目标节点中的主机固定内存缓冲区时,会发生第四次复制。
5 最后一步需要使用 PCIe 总线将数据复制到目标 GPU。

二、GPU Direct RDMA (2014年)
下面以InfiniBand为例:
GPU Direct RDMA 结合了 GPU 加速计算和 RDMA(Remote Direct Memory Access)技术,实现了在 GPU 和 RDMA 网络设备之间直接进行数据传输和通信的能力。它允许 GPU 直接访问 RDMA 网络设备中的数据,无需通过主机内存或 CPU 的中介。

使用 GPU Direct RDMA 两个 GPU 设备必须共享相同的上游 PCI Express root complex。

NCCL算法的实现涉及复杂的技术和优化,包括:
网络拓扑优化: 根据网络拓扑和通信模式确定GPU之间的最佳通信路径。
通信调度: 高效地调度通信任务,以最小化延迟并最大化利用网络资源。
错误处理和恢复: 实现机制来处理通信错误并确保可靠的数据传输。
代码实现和解释
实现NCCL功能通常涉及以下步骤:
通信原语: 定义用于基本操作(例如点对点传输和集体操作)的低级通信原语。
通信协议: 实现处理更高级别通信模式(例如全规约和广播)的通信协议。
硬件特定优化: 针对特定的GPU硬件和网络架构优化通信算法和数据结构。
NCCL用于实现分布式训练策略
策略简介
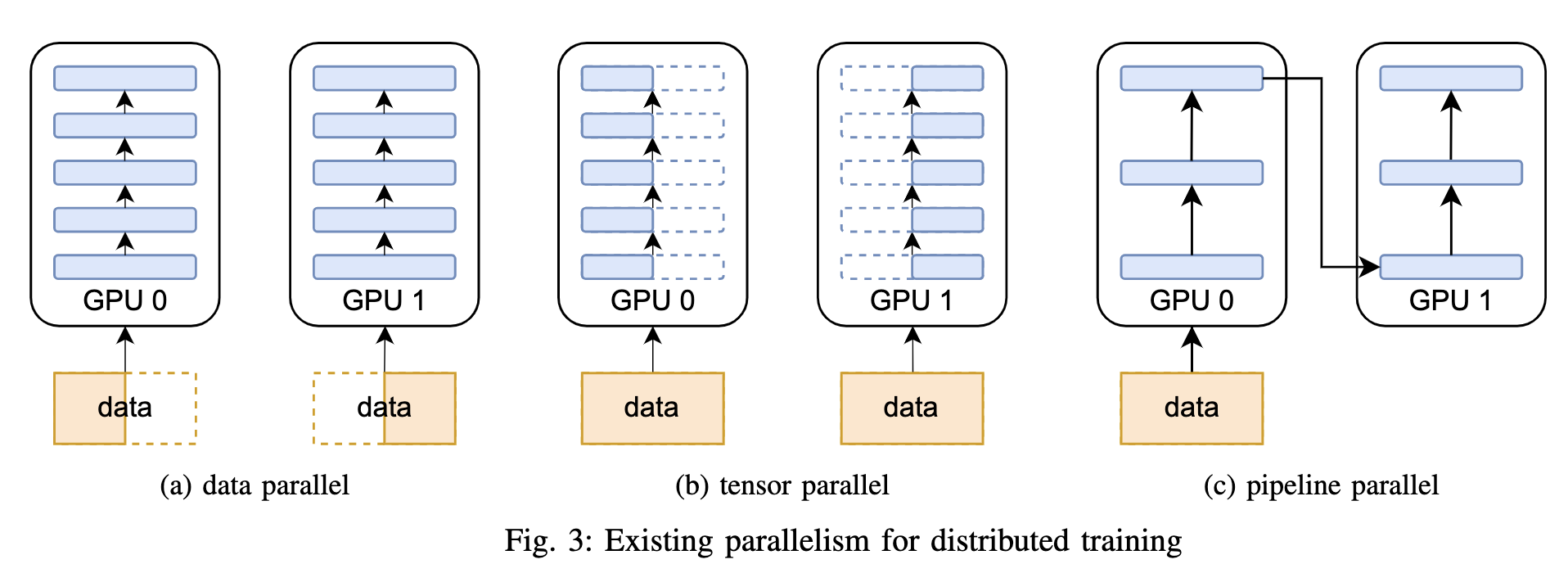
Data Parallelism(数据并行):
数据太大,拆分成子集,在不同设备上处理。通过NCCL,可以在这些设备之间高效地同步梯度或参数更新。
Model Parallelism(模型并行):
模型太大无法放入单个GPU的内存,模型拆分给不同的GPU处理。
这些GPU协同工作完成前向传播和后向传播。虽然模型并行不直接依赖于NCCL的所有功能,但NCCL可以帮助加速跨设备的必要通信。
模型并行又可分为
- tensor并行
- pipeline并行
- Sequence并行
具体见后面独立章节
Pipeline Parallelism(流水线并行):
将模型分割成多个阶段,每个阶段可以运行在一个或多个GPU上。
推荐文章:
策略详细说明
(摘自深度学习并行训练算法一锅炖: DDP, TP, PP, ZeRO - marsggbo - 博客园)
Model Parallelism(模型并行)
Pipeline Parallelism (PP)
pipeline parallelism是比较常见的模型并行算法,它是模型做层间划分,即inter-layer parallelism。以下图为例,如果模型原本有6层,你想在2个GPU之间运行pipeline,那么每个GPU只要按照先后顺序存3层模型即可。

已经有很多Pipeline相关的研究工作了,例如PipeDream,GPipe,和Chimera。它们的主要目的都是降低bubble time。这里不做过多介绍。
Tensor Parallelism (TP)
前面介绍的Pipeline Parallelism是对模型层间做划分,叫inter-layer parallelism。那么另一种方式则是对模型层内做划分,即intra-layer Parallelism,也叫Tensor Parallelism。

1D Tensor Parallelism
Megatron-LM [1] 是最早提出1D Tensor并行的工作。该工作主要是为了优化transformer训练效率,把线性层按照行或者列维度对权重进行划分。如图4所示,原本线性层为Y=W1W2X ,这里将W1按列进行划分,将W2按行进行划分。这样,每个GPU只需要存一半的权重即可,最后通过All-reduce操作来同步Y的结果。当GPU数量为N时,每个GPU只需要存1N的权重即可,只不过每层输出需要用All-reduce来补全结果之后才能继续下一层的计算。

对于土豪公司,可以使用NVLink来连接GPU(如图5a),从而提供高带宽来降低通信开销。但是土豪终归是少数的,大部分公司和个人是没法承担这昂贵的硬件费用,因此比较常见的GPU连接方式是图5b,即节点内花点钱实现NVLink连接,节点之间通过PCIe连接。

1D Tensor并行对通信速度要求较高,不过1D在每层的输入和输出都有冗余的内存开销。以图4为例,我们可以看到虽然模型权重被划分了,但是每个GPU都有重复的输入X,另外All-reduce之后每个GPU也会有重复的输出Y,所以后续一些工作尝试从这里做进一步改进,包括2D, 2.5D,和3D tensor并行。
2D Tensor Parallelism
2D Tensor Parallel [2] 基于SUMMA和Cannon矩阵相乘算法沿着两个不同的维度对 输入数据,模型权重,每层的输出 进行划分。给定N个GPU,tensor会被划分成N个chunk(使用torch.chunk),每个GPU保存一个chunk。这N个GPU呈方形网络拓扑结构,即每行每列均为√N个GPU。图6b展示了常见的4-GPU的节点划分示意图,假设tensor的维度大小是[P,Q],那么划分后每个GPU上存的chunk大小即为[P/√N,Q/√N]。至此,每个GPU都只会保存部分的输入输出以及部分的权重。虽然相比于1D Tensor并行,2D额外增加了模型权重的通信,但是需要注意的是当GPU数量很多的时候,每个GPU上分配的模型权重就会小很多,而且因为使用的All-reduce通信方式,所以2D也还是要比1D更高效的。
2.5D Tensor Parallelism
2.5D Tensor Parallel [3] 是受2.5D矩阵乘法算法 [4] 启发进一步对2D Tensor并行的优化。具体来说2.5D增加了 depth 维度。当 depth=1 时等价于2D;当 depth>1 时,
同样假设有N个GPU,其中N=S2∗D,S类似于原来2D正方形拓扑结构的边长,而D 则是新增加的维度 depth 。D可以由用户指定,S 则会自动计算出来了。所以一般来说至少需要8个GPU才能运行2.5D算法,即S=2,D=2。
3D Tensor Parallelism
3D Tensor Parallel [5] 是基于3D矩阵乘法算法 [6] 实现的。假设有 N个 GPU,tensor维度大小为[P,Q,K],那么每个chunk的大小即为 [P/3√N,Q/3√N,K/3√N]。当tensor维度小于3时,以全连接层为例,假设权重维度大小为 [P,Q] ,那么可以对第一个维度划分两次,即每个chunk的维度大小为 [P/(3√N)2,Q/3√N] 。3D Tensor并行的通信开销复杂度是 O(N1/3) ,计算和内存开销都均摊在所有GPU上。
小结
1D Tensor并行每一层的输出是不完整的,所以在传入下一层之前都需要做一次All-gather操作,从而使得每个GPU都有完整的输入,如图7a所示。
2D/2.5D/3D Tensor 并行算法因为在一开始就对输入进行了划分, 所以中间层不需要做通信,只需要在最后做一次通信即可。在扩展到大量设备(如GPU)时,通信开销可以降到很小。这3个改进的Tensor并行算法可以很好地和Pipeline并行方法兼容。

Sequential Parallelism
Tensor parallelism主要是为了解决由 model data (模型权重,梯度和优化器状态)导致的内存瓶颈,但是 non-model data也可能成为性能瓶颈。比如像AlphaFold和NAS任务中会存在很多中间特征值(也叫activations)。
以DARTS算法为例,它的模型参数量其实并不多,但是它有很多分支,所以activations会消耗大量GPU内存,这也是为什么很多NAS算法只能在CIFAR-10上搜索到合适的模型结构后,再做人工扩展,最后应用到ImageNet上做性能验证。
同样地,在使用Transformer训练语言模型时,由于Transformer层中的Self-attention机制的复杂度是O(n2),其中 n 是序列长度。换言之,长序列数据将增加中间activation内存使用量,从而限制设备的训练能力。
Sequential Parallelism (SP) [7] 就为了解决non-model data导致的性能瓶颈而提出的。下图给出了SP在Transform并行训练上的应用,具体的原理可以查看原论文。

Zero Redundancy Data Parallelism (ZeRO)
训练过程中GPU内存开销主要包含以下几个方面:
- 模型状态内存(Model State Memory):
- 梯度
- 模型参数
- 优化器状态:当使用像Adam这样的优化器时,优化器的状态会成为GPU内存开销的大头。前面介绍的DP,TP, PP算法并没有考虑这个问题。
- 激活内存(Activation Memory):在优化了模型状态内存之后,人们发现激活函数也会导致瓶颈。激活函数计算位于前向传播之中,用于支持后向传播。
- 碎片内存(Fragmented Memory):深度学习模型的低效有时是由于内存碎片所导致的。在模型之中,每个张量的生命周期不同,由于不同张量寿命的变化而会导致一些内存碎片。由于这些碎片的存在,会导致即使有足够的可用内存,也会因为缺少连续内存而使得内存分配失败。ZeRO 根据张量的不同寿命主动管理内存,防止内存碎片。
ZeRO针对模型状态的三部分都做了对应的内存改进方法:
- ZeRO1:只划分优化器状态(optimizer states, os),即Pos
- ZeRO2:划分优化器状态和梯度(gradient, g),即Pos+g
- ZeRO3:划分优化器状态和梯度和模型参数(parameters, p),即Pos+g+p
下图给出了三种方法带来的内存开销收益

不管采用三种方法的哪一种,ZeRO简单理解就是给定N个设备,然后把一堆data等分到这些设备上,每个设备只存1/N的数据量,并且每次也只负责更新这1/N的数据。
因为对数据做了划分,ZeRO在每一层都需要有通信操作。我们考虑ZeRO在某一层的具体操作:
- 在forward的时候,会首先使用all-gather让每个设备拥有该层完整的模型权重,然后计算得到输出,最后每个设备会只保留原来的权重,即把all-gather过来的权重扔掉,这样可以节省开销。
- 在backward的时候,同样会先all-gather该层的所有权重,然后计算梯度,最后也会把梯度进行划分,每个设备上只会存1/N对应的梯度数据。
注意ZeRO对数据划分方式并没有什么具体的要求,可以是随意划分,因为最后反正会用all-gather使得所有设备商都有用完整的数据;当然,也可以使用前面提到的Tensor Parallelism的划分方式,这样一来可以有效降低通信开销,进一步提高效率。
NCCL通信原语
通信元语说明见文章:通信元语和相关概念-https://blog.youkuaiyun.com/bandaoyu/article/details/146463108
NCCL通信协议
以下内容部分摘抄或参考自:https://zhuanlan.zhihu.com/p/699178659
简介
NCCL确实提供了Simple、LL和LL128这三种通信协议,以满足不同应用场景下的性能需求。以下是对这三种通信协议的简要说明:
- Simple:这是NCCL的基础通信协议,实现上相对简单,适用于不需要特别优化的通信场景。
- LL(Low Latency):低延迟协议,特别优化了小数据量传输的性能。在数据传输量较小,无法充分利用传输带宽时,LL协议通过减少同步带来的延迟来提高性能。它依赖于CUDA的8字节原子存储操作,将数据排列组合成4B Data+4B Flag的形式进行传输,对端会对Flag值进行校验,以确保数据成功传输。
- LL128:这是LL协议的一个扩展或优化版本,特别适用于NVLink环境下的通信。LL128能够以较低的延迟达到较大的带宽率,因此在带有NVLink的机器上,NCCL会默认使用该协议。与LL协议类似,LL128也使用Flag来进行数据校验,但它以128字节为单位进行原子存储操作,从而在某些情况下可能提供更好的带宽效率。
NCCL 使用 3 种不同的协议:LL、LL128 和 Simple,它们具有不同的延迟(~1us、~2us 和 ~6us)、不同的带宽(50%、95% 和 100%),以及其他影响其性能的差异。
如何选择 NCCL 协议
数据规模:
小规模数据:优先使用 Simple 协议。
大规模数据:使用 LL 或 LL128 协议。
硬件环境:
如果硬件支持 NVLink,优先使用 LL 或 LL128 协议。
如果硬件环境较简单,可以使用 Simple 协议。
性能需求:
对性能要求较高的场景,避免使用 Simple 协议。
NCCL通信选择协议规则
1 自动选择
下面是一段使用 NCCL 进行 AllReduce 操作的伪代码示例,代码中没有体现使用哪一种协议:
#include <nccl.h>
#include <cuda_runtime.h>
void allReduceWithSimpleProtocol(float* data, int count, int nGPUs) {
ncclComm_t comm;
ncclUniqueId id;
ncclGetUniqueId(&id); // 获取唯一的 NCCL ID
// 初始化 NCCL 通信器
ncclCommInitAll(&comm, nGPUs, id);
// 执行 AllReduce 操作
ncclAllReduce(data, data, count, ncclFloat, ncclSum, comm, 0);
// 销毁 NCCL 通信器
ncclCommDestroy(comm);
}这是因为:
NCCL 的设计目标是提供高效的集体通信操作,同时隐藏底层协议的复杂性。因此:
协议选择是自动的:NCCL 在运行时根据硬件(如 GPU 型号、NVLink 拓扑)和数据规模自动选择最优的协议(如 Simple、LL、LL128 等)。
API 是抽象的:NCCL 的 API(如
ncclAllReduce)并不直接暴露协议的选择,开发者只需调用 API,NCCL 会自动处理底层细节。
2 强制选择
例如,如何强制使用 Simple 协议?
可以通过设置环境变量来强制 NCCL 使用某种协议,如 Simple 协议。以下是如何操作的步骤:
设置环境变量
export NCCL_PROTO=Simple
验证协议
设置以下环境变量来查看 NCCL 实际使用的协议:
export NCCL_DEBUG=INFO运行程序时,NCCL 会输出调试信息,包括使用的协议。
验证例子
以下是一个完整的示例,展示如何强制使用 Simple 协议并验证协议选择:
#include <nccl.h>
#include <cuda_runtime.h>
#include <iostream>
int main() {
// 初始化 CUDA
cudaSetDevice(0);
// 分配数据
int count = 1024;
float* data;
cudaMalloc(&data, count * sizeof(float));
// 初始化 NCCL
ncclComm_t comm;
ncclUniqueId id;
ncclGetUniqueId(&id); // 获取唯一的 NCCL ID
ncclCommInitAll(&comm, 1, &id); // 初始化通信器(单 GPU)
// 执行 AllReduce 操作
ncclAllReduce(data, data, count, ncclFloat, ncclSum, comm, 0);
// 销毁 NCCL 通信器
ncclCommDestroy(comm);
// 释放 CUDA 内存
cudaFree(data);
std::cout << "NCCL AllReduce completed!" << std::endl;
return 0;
}在运行程序之前,设置环境变量:
export NCCL_PROTO=Simple
export NCCL_DEBUG=INFO
./your_program
输出:
NCCL INFO Connected all rings
NCCL INFO Using network Simple
NCCL INFO AllReduce: opSum, datatypeFloat, count=1024, protocol=SimpleSimple协议
1 介绍
1. Simple 协议的作用
Simple 协议是 NCCL 中最基础的通信协议,主要用于以下场景:
-
小规模数据传输:当数据量较小时,Simple 协议可以提供低开销的通信。
-
调试和测试:由于其实现简单,Simple 协议常用于调试和测试 NCCL 的基本功能。
2. Simple 协议的特点
-
实现简单:Simple 协议的实现逻辑较为直接,适合处理简单的通信任务。
-
低开销:由于协议逻辑简单,通信开销较低,适合小规模数据传输。
-
通用性:Simple 协议不依赖于特定的硬件优化,可以在各种硬件环境下运行。
3. Simple 协议的工作方式
Simple 协议的核心思想是通过 点对点通信 实现集体通信操作。以下是其工作流程:
-
数据分块:
-
将需要传输的数据分成多个小块(chunks)。
-
-
点对点传输:
-
每个 GPU 将数据块发送给目标 GPU,同时接收来自其他 GPU 的数据块。
-
-
数据聚合:
-
在接收端,将来自不同 GPU 的数据块聚合起来,完成集体通信操作(如 AllReduce、Broadcast 等)。
-
2 Simple 协议的基本格式
Simple 协议的格式可以理解为一种基于 消息分块 和 点对点通信 的简单数据传输机制。以下是其可能的格式和工作流程:
1. 消息分块
-
数据被划分为多个固定大小的块(chunks)。
-
每个块的大小通常与硬件特性(如 GPU 的显存带宽)相匹配,以优化传输效率。
2. 消息头(Header)
每个数据块可能包含一个消息头,用于描述数据的元信息。消息头的格式可能包括以下字段:
消息类型:标识通信操作的类型(如 AllReduce、Broadcast 等)。
数据块编号:标识当前数据块在整体数据中的位置。
数据块大小:标识当前数据块的大小。
目标 GPU ID:标识数据块的目标 GPU。
3. 数据块(Payload)
-
数据块是实际传输的数据部分。
-
数据块的大小通常是固定的,以简化传输逻辑。
4. 点对点传输
-
每个 GPU 将数据块发送给目标 GPU,同时接收来自其他 GPU 的数据块。
-
数据传输可能通过 PCIe 或 NVLink 进行,具体取决于硬件环境。
2 Simple 协议的示例
协议选择,NCCL 根据环境情况自动选择或用户通过设置环境变量指定使用Simple 协议。详情见本文《NCCL通信选择协议规则》的相关说明。
Simple 协议的工作流程
以下是一个典型的工作流程:
初始化:
NCCL 初始化通信器(ncclCommInitAll),确定参与通信的 GPU 和拓扑结构。
数据分块:
将需要传输的数据划分为多个固定大小的块。
消息头生成:
为每个数据块生成消息头,包含元信息(如目标 GPU ID、数据块编号等)。
数据传输:
每个 GPU 将数据块发送给目标 GPU,同时接收来自其他 GPU 的数据块。
数据聚合:
在接收端,将来自不同 GPU 的数据块聚合起来,完成集体通信操作(如 AllReduce、Broadcast 等)。
Simple 协议的伪代码示例
以下是一个简化的伪代码示例,展示 Simple 协议的可能实现:
struct SimpleProtocolHeader {
int messageType; // 消息类型(如 AllReduce、Broadcast)
int chunkId; // 数据块编号
int chunkSize; // 数据块大小
int targetGpuId; // 目标 GPU ID
};
void simpleProtocolSend(void* data, int size, int targetGpuId) {
int chunkSize = 1024; // 假设每个数据块大小为 1024 字节
int numChunks = (size + chunkSize - 1) / chunkSize;
for (int i = 0; i < numChunks; i++) {
// 生成消息头
SimpleProtocolHeader header;
header.messageType = ALLREDUCE;
header.chunkId = i;
header.chunkSize = chunkSize;
header.targetGpuId = targetGpuId;
// 发送消息头和数据块
sendHeaderAndData(&header, data + i * chunkSize, chunkSize);
}
}
void simpleProtocolReceive(void* buffer, int size) {
int chunkSize = 1024; // 假设每个数据块大小为 1024 字节
int numChunks = (size + chunkSize - 1) / chunkSize;
for (int i = 0; i < numChunks; i++) {
// 接收消息头和数据块
SimpleProtocolHeader header;
void* chunkData = receiveHeaderAndData(&header);
// 将数据块写入缓冲区
memcpy(buffer + header.chunkId * chunkSize, chunkData, header.chunkSize);
}
}LL协议(Low Latency)
1 介绍
LL 协议(Low Latency) 的出现是为了解决多 GPU 和多节点通信中的 延迟问题。
以往NCCL为了保证同步,会引入 memory fence,这就导致延迟比较大。而在小数据量下,往往打不满传输带宽,此时优化点在于同步带来的延迟。
LL协议依赖前提是 CUDA 的memory 8Bytes大小的操作是atomic的,因此通信时会将数据排列组合成 4B Data + 4B Flag 进行传输。
而对端则会对Flag值进行校验,当达到预期值后,代表4B Data已经成功传输过来,便可进行下一步的操作。
一些相关代码实现在 prims_ll.h
存储数据的代码为:
__device__ void storeLL(union ncclLLFifoLine* dst, uint64_t val, uint32_t flag) {
asm volatile("st.volatile.global.v4.u32 [%0], {%1,%2,%3,%4};" :: "l"(&dst->i4), "r"((uint32_t)val), "r"(flag), "r"((uint32_t)(val >> 32)), "r"(flag));
}读取远端数据的代码为:
__device__ uint64_t readLL(int offset, int i) {
union ncclLLFifoLine* src = recvPtr(i) + offset;
uint32_t flag = recvFlag(i);
uint32_t data1, flag1, data2, flag2;
int spins = 0;
do {
asm("ld.volatile.global.v4.u32 {%0,%1,%2,%3}, [%4];" : "=r"(data1), "=r"(flag1), "=r"(data2), "=r"(flag2) : "l"(&src->i4));
if (checkAbort(spins, 0)) break;
} while ((flag1 != flag) || (flag2 != flag));
uint64_t val64 = data1 + (((uint64_t)data2) << 32);
return val64;
}
- 使用volatile关键字来保证相关内存操作不会被编译器优化重排
- CUDA支持向量化加载128bit数据,因此用的是 u32x4 指令
- 存储的时候,按照 DATA1 | FLAG1 | DATA2 | FLAG2 形式重排组合进128bit寄存器里
- 读取的时候,当flag1 和 flag2 为预期值后,将data1 和 data2 组合到一起,得到真正的数据
因为 Flag 占了整个数据包的一半,因此有效带宽是 50%,LL协议也因为这个不适用大数据量的传输。

如何选择LL协议
协议选择,NCCL 根据环境情况自动选择或用户通过设置环境变量指定使用LL 协议。详情见本文《NCCL通信选择协议规则》的相关说明。
LL128协议(Low Latency128)
1 介绍
LL128 协议(Low Latency 128) 的出现是为了进一步优化大规模数据传输的通信效率,它是 LL 协议(Low Latency) 的扩展,旨在解决 LL 协议在大规模数据传输中的局限性。(ll效带宽是 50%,ll128是93.75%)
该协议与LL特别像,但是又依赖于一些特殊硬件(NVLink)实现。
在NVLink下,memory operation 是以 128B 的粒度顺序可见的。考虑每个thread依旧是用128bit(16B)传输,那么128B这个粒度只需要每8个thread为一组,并且让最后一个thread承担flag校验的任务即可。
计算下来可以得到有效数据为:16B * 7 + 8B = 120B
Flag校验位为:8B
有效带宽为:120B / 128B = 93.75%
LL128能够以较低的延迟达到较大的带宽率,NCCL会在带有NVLink的机器上默认使用该Protocol

相关代码位于 prims_ll128.h 头文件内
在类初始化的时候,会以每8个thread的最后一个thread作为FlagThread,只有该thread进行Flag位校验:
bool flagThread;
flagThread((tid%8)==7)加载数据到寄存器代码为:
template<int WordPerThread>
__device__ __forceinline__ void loadRegsBegin(uint64_t(®s)[WordPerThread], T const *src, int eltN) {
constexpr int EltPer16B = 16/sizeof(T);
if(reinterpret_cast<uintptr_t>(src)%16 == 0) {
/* We are aligned to 16 bytes, so load directly to registers no shmem.
* Flag threads load half as much data which gets shuffled to the even
* registers during Finish. The point of splitting into two phases is to
* defer that shuffle, which incurs a dependency stall, until after other
* memops are launched by the caller.
*/
#pragma unroll
for(int g=0; g < WordPerThread/2; g++) {
int ix = g*WARP_SIZE - 4*(g/2) + wid - (g%2)*(wid/8);
if(!flagThread || g%2==0) {
if(ix*EltPer16B < eltN)
load128((uint64_t*)(src + ix*EltPer16B), regs[2*g+0], regs[2*g+1]);
}
}
}这里的ix为:0,32,60,92。对相邻的ix做差可得到 32, 28, 32。考虑到这是以Warp为单位操作,可得第一次加载32个线程都参与,第二次加载只有4*(8-1)个线程参与,同理推第三次/第四次加载。
每个thread有 uint64_t regs[8] 寄存器,主要区别就在于flagThread加载逻辑,第一次加载满,第二次不加载,第三次加载满,第四次不加载,那么整个寄存器情况为:

在 recvReduceSendCopy 方法里,会调用一次 loadRegsFinish 完成整个寄存器加载:
template<int WordPerThread>
__device__ __forceinline__ void loadRegsFinish(uint64_t(®s)[WordPerThread]) {
// Move data out of flag registers into the vacant registers.
#pragma unroll
for (int g=1; g < WordPerThread/2; g+=2) {
if (flagThread) regs[2*g] = regs[2*g-1];
}
}其实就是交换了下,regs[2]/[1], regs[6]/[5], 得到:

作者在解释这里操作原因是为了避免shuffle数据依赖导致的stall
The point of splitting into two phases is to
defer that shuffle, which incurs a dependency stall, until after other
memops are launched by the caller.发送时候再填充Flag:
store128(ptr+u*WARP_SIZE, v[u], flagThread ? flag : v[u+1]);读取远端数据:
if (RECV) {
uint64_t* ptr = recvPtr(0)+ll128Offset;
uint64_t flag = recvFlag(0);
bool needReload;
int spins = 0;
do {
needReload = false;
#pragma unroll
for (int u=0; u<ELEMS_PER_THREAD; u+=2) {
load128(ptr+u*WARP_SIZE, vr[u], vr[u+1]);
needReload |= flagThread && (vr[u+1] != flag);
}
needReload &= (0 == checkAbort(spins, 0, 0));
} while (__any_sync(WARP_MASK, needReload));
#pragma unroll
for (int u=0; u<ELEMS_PER_THREAD; u+=2)
load128(ptr+u*WARP_SIZE, vr[u], vr[u+1]);
}- 一次性加载128bit,needReload配合while循环看flagThread里的flag是否为预期值,如果是则校验通过
存储寄存器的时候,我们需要把flagThread的寄存器再反shuffle回来:
template<int WordPerThread>
__device__ __forceinline__ void storeRegs(T *dst, uint64_t(®s)[WordPerThread], int eltN) {
constexpr int EltPer16B = 16/sizeof(T);
// Reverse Finish() register permuatation.
#pragma unroll
for (int g=1; g < WordPerThread/2; g+=2) {
if (flagThread) regs[2*g-1] = regs[2*g];
}
// ...Reference: What is LL128 Protocol?
如何选择LL128协议
协议选择,NCCL 根据环境情况自动选择或用户通过设置环境变量指定使用LL128 协议。详情见本文《NCCL通信选择协议规则》的相关说明。
LL 和 LL128 协议的对比
| 特性 | LL 协议 | LL128 协议 |
|---|---|---|
| 数据块大小 | 较小(通常为 128 字节) | 较大(通常为 128 字节的倍数,如 128 * N) |
| 延迟 | 低 | 较低 |
| 带宽利用率 | 较高 | 极高 |
| 适用数据规模 | 中等规模(几百 KB 到几 MB) | 大规模(几 MB 到几百 MB) |
| 硬件优化 | 优化 NVLink 和 PCIe 的低延迟特性 | 优化 NVLink 和 PCIe 的高带宽特性 |
| 适用场景 | 单节点多 GPU、中等规模数据传输 | 多节点 GPU 集群、大规模数据传输 |
为什么 LL128 协议的数据块较大?
LL128 协议是 LL 协议的扩展,其核心思想是通过增加数据块大小来减少通信开销,从而提高带宽利用率。具体来说:
-
减少通信次数:较大的数据块意味着每次传输的数据量增加,从而减少通信次数,降低通信开销。
-
提高带宽利用率:大数据块能够更好地利用 NVLink 和 PCIe 的高带宽特性,最大化传输效率。
常见 NIVIDA 指令
摘自:https://zhuanlan.zhihu.com/p/6160835906
这里参考了 WeLearnNLP 的指南。
nvidia-smi topo -m
最典型的当然有 nvidia-smi 和 nvidia-smi topo -m。前者都非常熟悉了,这里我对比下两台集群的 nvidia-smi topo -m 的输出:
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X SYS SYS SYS SYS SYS SYS SYS 0-15,32-47 0 N/A
GPU1 SYS X SYS SYS SYS SYS SYS SYS 0-15,32-47 0 N/A
GPU2 SYS SYS X SYS SYS SYS SYS SYS 0-15,32-47 0 N/A
GPU3 SYS SYS SYS X SYS SYS SYS SYS 0-15,32-47 0 N/A
GPU4 SYS SYS SYS SYS X SYS SYS SYS 16-31,48-63 1 N/A
GPU5 SYS SYS SYS SYS SYS X SYS SYS 16-31,48-63 1 N/A
GPU6 SYS SYS SYS SYS SYS SYS X SYS 16-31,48-63 1 N/A
GPU7 SYS SYS SYS SYS SYS SYS SYS X 16-31,48-63 1 N/A
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X NV18 NV18 NV18 NV18 NV18 NV18 NV18 0-47,96-143 0 N/A
GPU1 NV18 X NV18 NV18 NV18 NV18 NV18 NV18 0-47,96-143 0 N/A
GPU2 NV18 NV18 X NV18 NV18 NV18 NV18 NV18 0-47,96-143 0 N/A
GPU3 NV18 NV18 NV18 X NV18 NV18 NV18 NV18 0-47,96-143 0 N/A
GPU4 NV18 NV18 NV18 NV18 X NV18 NV18 NV18 48-95,144-191 1 N/A
GPU5 NV18 NV18 NV18 NV18 NV18 X NV18 NV18 48-95,144-191 1 N/A
GPU6 NV18 NV18 NV18 NV18 NV18 NV18 X NV18 48-95,144-191 1 N/A
GPU7 NV18 NV18 NV18 NV18 NV18 NV18 NV18 X 48-95,144-191 1 N/A
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks可以读出很多有趣的信息:
通过对比这两个集群的拓扑信息,我可以得出以下几个重要结论:
- 互联方式
- 第一个集群:所有 GPU 之间通过 PCIe 和 NUMA 节点间的 SMP 互联(标记为 SYS)
- 第二个集群:所有 GPU 之间通过 18 条 NVLink 连接(标记为 NV18)
- 性能影响:第二个集群的 GPU 间通信性能显著优于第一个集群,因为 NVLink 的带宽和延迟都优于 PCIe+SMP 方案
- NUMA 架构
- 两个集群都采用双 NUMA 节点设计:
- GPU 0-3 属于 NUMA 节点 0
- GPU 4-7 属于 NUMA 节点 1
- GPU 通信:应尽量将相关任务分配到同一 NUMA 节点内的 GPU,以避免跨 NUMA 节点的频繁数据传输
- CPU 核心分配:
- 第一个集群:每个 NUMA 节点分配 32 个核心(如 0-15,32-47)
- 第二个集群:每个 NUMA 节点分配 96 个核心(如 0-47,96-143)
- 系统规模
- GPU 数量:两个集群都是 8 GPU 配置
- CPU 核心总数:
- 第一个集群:64 核心
- 第二个集群:192 核心
- 拓扑完整性
- 每个 GPU 都与其他所有 GPU 直接相连
NVLINK 查询
nvidia-smi nvlink --status -i 0
nvidia-smi nvlink --capabilities -i 0nvlink 查询结果
GPU 0: NVIDIA H100 80GB HBM3 (UUID: GPU-5a10e6e5-95f7-2785-ed63-6f6147f304f7)
Link 0: 26.562 GB/s
Link 1: 26.562 GB/s
Link 2: 26.562 GB/s
Link 3: 26.562 GB/s
Link 4: 26.562 GB/s
Link 5: 26.562 GB/s
Link 6: 26.562 GB/s
Link 7: 26.562 GB/s
Link 8: 26.562 GB/s
Link 9: 26.562 GB/s
Link 10: 26.562 GB/s
Link 11: 26.562 GB/s
Link 12: 26.562 GB/s
Link 13: 26.562 GB/s
Link 14: 26.562 GB/s
Link 15: 26.562 GB/s
Link 16: 26.562 GB/s
Link 17: 26.562 GB/s
GPU 0: NVIDIA H100 80GB HBM3 (UUID: GPU-5a10e6e5-95f7-2785-ed63-6f6147f304f7)
Link 0, P2P is supported: true
Link 0, Access to system memory supported: true
Link 0, P2P atomics supported: true
Link 0, System memory atomics supported: true
Link 0, SLI is supported: true
Link 0, Link is supported: true
Link 1, P2P is supported: true
Link 1, Access to system memory supported: true
Link 1, P2P atomics supported: true
Link 1, System memory atomics supported: true
Link 1, SLI is supported: true
Link 1, Link is supported: true
Link 2, P2P is supported: true
Link 2, Access to system memory supported: true
Link 2, P2P atomics supported: true
Link 2, System memory atomics supported: true
Link 2, SLI is supported: true
Link 2, Link is supported: true
Link 3, P2P is supported: true
Link 3, Access to system memory supported: true
Link 3, P2P atomics supported: true
Link 3, System memory atomics supported: true
Link 3, SLI is supported: true
Link 3, Link is supported: true
Link 4, P2P is supported: true
Link 4, Access to system memory supported: true
Link 4, P2P atomics supported: true
Link 4, System memory atomics supported: true
Link 4, SLI is supported: true
Link 4, Link is supported: true
Link 5, P2P is supported: true
Link 5, Access to system memory supported: true
Link 5, P2P atomics supported: true
Link 5, System memory atomics supported: true
Link 5, SLI is supported: true
Link 5, Link is supported: true
Link 6, P2P is supported: true
Link 6, Access to system memory supported: true
Link 6, P2P atomics supported: true
Link 6, System memory atomics supported: true
Link 6, SLI is supported: true
Link 6, Link is supported: true
Link 7, P2P is supported: true
Link 7, Access to system memory supported: true
Link 7, P2P atomics supported: true
Link 7, System memory atomics supported: true
Link 7, SLI is supported: true
Link 7, Link is supported: true
Link 8, P2P is supported: true
Link 8, Access to system memory supported: true
Link 8, P2P atomics supported: true
Link 8, System memory atomics supported: true
Link 8, SLI is supported: true
Link 8, Link is supported: true
Link 9, P2P is supported: true
Link 9, Access to system memory supported: true
Link 9, P2P atomics supported: true
Link 9, System memory atomics supported: true
Link 9, SLI is supported: true
Link 9, Link is supported: true
Link 10, P2P is supported: true
Link 10, Access to system memory supported: true
Link 10, P2P atomics supported: true
Link 10, System memory atomics supported: true
Link 10, SLI is supported: true
Link 10, Link is supported: true
Link 11, P2P is supported: true
Link 11, Access to system memory supported: true
Link 11, P2P atomics supported: true
Link 11, System memory atomics supported: true
Link 11, SLI is supported: true
Link 11, Link is supported: true
Link 12, P2P is supported: true
Link 12, Access to system memory supported: true
Link 12, P2P atomics supported: true
Link 12, System memory atomics supported: true
Link 12, SLI is supported: true
Link 12, Link is supported: true
Link 13, P2P is supported: true
Link 13, Access to system memory supported: true
Link 13, P2P atomics supported: true
Link 13, System memory atomics supported: true
Link 13, SLI is supported: true
Link 13, Link is supported: true
Link 14, P2P is supported: true
Link 14, Access to system memory supported: true
Link 14, P2P atomics supported: true
Link 14, System memory atomics supported: true
Link 14, SLI is supported: true
Link 14, Link is supported: true
Link 15, P2P is supported: true
Link 15, Access to system memory supported: true
Link 15, P2P atomics supported: true
Link 15, System memory atomics supported: true
Link 15, SLI is supported: true
Link 15, Link is supported: true
Link 16, P2P is supported: true
Link 16, Access to system memory supported: true
Link 16, P2P atomics supported: true
Link 16, System memory atomics supported: true
Link 16, SLI is supported: true
Link 16, Link is supported: true
Link 17, P2P is supported: true
Link 17, Access to system memory supported: true
Link 17, P2P atomics supported: true
Link 17, System memory atomics supported: true
Link 17, SLI is supported: true
Link 17, Link is supported: true可以分析看到一些对开发实用的特性:
- P2P(点对点)通信
- 系统内存访问
- P2P原子操作
- 系统内存原子操作
- SLI(多GPU并行)
- 完整的链路支持
GPU 监控
可以监控 GPU 的方式很多,这里推荐 nvitop,非常方便,pip 安装即可,看着最赏心悦目。
NCCL、RCCL和MCCL的区别
NCCL、RCCL和MCCL是用于高性能计算的通信库,主要区别在于支持的硬件平台和优化目标:
-
NCCL (NVIDIA Collective Communications Library)
-
硬件支持:专为NVIDIA GPU设计,支持多GPU和多节点通信。
-
优化目标:针对NVIDIA GPU的NVLink和PCIe拓扑进行优化,适合深度学习和大规模并行计算。
-
应用场景:主要用于深度学习训练,支持跨节点通信。
-
-
RCCL (ROCm Collective Communications Library)
-
硬件支持:专为AMD GPU设计,基于ROCm平台。
-
优化目标:针对AMD GPU的Infinity Fabric和PCIe拓扑进行优化,支持多GPU和多节点通信。
-
应用场景:适用于AMD GPU的深度学习和高性能计算。
-
-
MCCL (Machine Collective Communications Library)
-
硬件支持:专为机器学习加速器(如TPU、FPGA等)设计。
-
优化目标:针对特定机器学习硬件的通信需求进行优化,支持多设备通信。
-
应用场景:主要用于机器学习加速器的高性能计算任务。
-
总结
-
NCCL:适用于NVIDIA GPU。
-
RCCL:适用于AMD GPU。
-
MCCL:适用于机器学习加速器。
选择库时需根据硬件平台和具体需求决定。
NCCL与 MPI的区别
NCCL(NVIDIA Collective Communications Library) 和 MPI(Message Passing Interface) 都是用于并行计算和分布式计算的通信库,但它们的应用场景、设计目标和实现方式有显著区别。
MPI 是 NCCL 的基础,主要是因为 MPI 提供了一种通用的、标准化的分布式计算框架,而 NCCL 在此基础上针对 GPU 通信进行了专门优化。
以下是它们的详细对比:
1. 设计目标和应用场景
| 特性 | NCCL | MPI |
|---|---|---|
| 主要目标 | 优化多 GPU 和多节点之间的通信,特别是深度学习中的分布式训练。 | 通用的并行计算通信标准,适用于各种分布式计算场景(如科学计算、仿真等)。 |
| 应用场景 | 深度学习框架(如 TensorFlow、PyTorch)中的多 GPU 训练。 | 高性能计算(HPC)、科学计算、大规模并行计算。 |
| 硬件优化 | 针对 NVIDIA GPU 和 NVLink 进行深度优化。 | 不特定于硬件,支持多种硬件架构(如 CPU、GPU、InfiniBand 等)。 |
2. 通信模式
| 特性 | NCCL | MPI |
|---|---|---|
| 通信操作 | 专注于集体通信(Collective Communication),如 AllReduce、Broadcast 等。 | 支持点对点通信(Point-to-Point)和集体通信(Collective Communication)。 |
| 通信范围 | 主要用于单节点多 GPU 或多节点 GPU 集群。 | 支持任意规模的分布式计算,包括 CPU 和 GPU 集群。 |
| 通信效率 | 针对 GPU 通信高度优化,性能极高。 | 通用性强,但可能需要额外配置以优化 GPU 通信。 |
3. 硬件支持
| 特性 | NCCL | MPI |
|---|---|---|
| GPU 支持 | 专门为 NVIDIA GPU 设计,支持 NVLink 和 PCIe。 | 通过 CUDA-aware MPI 实现 GPU 支持,但需要额外配置。 |
| 多节点支持 | 支持多节点通信,但主要针对 GPU 集群。 | 支持多节点通信,适用于各种硬件(如 CPU、GPU、InfiniBand 等)。 |
| 硬件优化 | 深度优化 NVIDIA GPU 和 NVLink 的通信性能。 | 通用性强,但需要针对特定硬件进行优化。 |
4. 编程模型和集成
| 特性 | NCCL | MPI |
|---|---|---|
| 编程模型 | 提供简单的 API,专注于 GPU 集体通信。 | 提供丰富的 API,支持点对点和集体通信,编程模型更复杂。 |
| 集成性 | 与深度学习框架(如 TensorFlow、PyTorch)深度集成。 | 需要手动集成到应用程序中,适合自定义并行计算任务。 |
| 易用性 | 对深度学习开发者更友好,API 简单易用。 | 需要更多编程经验,适合高性能计算领域的开发者。 |
5. 性能对比
| 特性 | NCCL | MPI |
|---|---|---|
| GPU 通信性能 | 针对 NVIDIA GPU 优化,性能极高,延迟低。 | 性能依赖于实现(如 OpenMPI、MVAPICH2),可能需要额外优化。 |
| 多节点性能 | 针对 GPU 集群优化,但在纯 CPU 集群中性能不如 MPI。 | 在多节点 CPU 集群中性能优异,支持多种网络协议(如 InfiniBand、以太网)。 |
| 扩展性 | 适合中小规模 GPU 集群,大规模扩展性有限。 | 适合超大规模分布式计算,扩展性极强。 |
6. 典型使用场景
| 场景 | NCCL | MPI |
|---|---|---|
| 深度学习训练 | 用于多 GPU 分布式训练,如 TensorFlow、PyTorch 中的 AllReduce 操作。 | 可用于分布式训练,但需要更多手动配置。 |
| 科学计算 | 不常用。 | 广泛用于科学计算、仿真和大规模数值计算。 |
| 通用并行计算 | 不适用。 | 适用于各种并行计算任务,灵活性高。 |
总结
| 特性 | NCCL | MPI |
|---|---|---|
| 定位 | GPU 优化的集体通信库,专注于深度学习。 | 通用的并行计算通信标准,适用于多种场景。 |
| 硬件支持 | 针对 NVIDIA GPU 和 NVLink 优化。 | 支持多种硬件架构,通用性强。 |
| 易用性 | 对深度学习开发者更友好。 | 需要更多编程经验。 |
| 性能 | 在 GPU 集群中性能优异。 | 在大规模 CPU 集群中性能优异。 |
选择建议:
-
如果你的应用场景是 深度学习 或 多 GPU 训练,优先选择 NCCL。
-
如果你的应用场景是 科学计算 或 通用并行计算,优先选择 MPI。
NCCL与 xCCL的区别
xCCL是BCCL(百度的ccl),HCCL(华为的ccl),ACCL(阿里的ccl),TCCL(腾讯的ccl),RCCL(AMD的ccl)的代称,


















 1855
1855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









