




在本项目中,我们基于用户购买数据(Transaction Data)做用户的分群,使用的方法一次是RFM模型和K-means算法。
原始数据是:http://archive.ics.uci.edu/ml/datasets/online+retail 。本项目中使用的数据是已经经过清洗之后的,原始数据的话需要大量的清洗工作。
import pandas as pd
import numpy as np
import datetime as dt
# 读取transaction数据, 数据有些大,读取会需要点时间,耐心等几秒...
df = pd.read_excel('OnlineClean.xlsx')
df.head()# 对于时间属性做个转换,只保留年月日
df['InvoiceDate'] = df['InvoiceDate'].dt.date
# 一般情况下,在使用RFM模型的时候,一般需要过去一年的Transaction数据。为了提取过去一年的数据,我们首先对时间做一下处理。
print('Min date = {}, Max date = {}'.format(min(df.InvoiceDate), max(df.InvoiceDate)))
# 只考虑大于2010-12-09
df = df[df['InvoiceDate']>dt.date(2010,12,9)]
# 创建一个新的变量,叫做snapshot_date。 举个例子,我们已经有了过去一年的历史数据,然后基于历史数据要计算出R, F, M。
# 如果历史数据是昨天为止的,那当我们计算R(recency)的时候, 就需要今天 - 历史。 这样一来,今天其实就是昨天日期+1就可以了,这个
# 我们把它叫作snapshot_date
snapshot_date = max(df.InvoiceDate) + dt.timedelta(days=1)
# 我们再创建一个column叫作TotalSum, 来表示购买某一种商品的总额
df['TotalSum'] = df['Quantity'] * df['UnitPrice']
df.loc[df['InvoiceDate']>dt.date(2010,12,9) and df['CustomerID']==15805]
到目前为止数据方面的整理工作已经就绪。接下来呢,需要来计算R,F,M的值了。 为了计算R,F,M需要对每一位Customer做Aggregation操作,这部分可以通过df.groupby函数来实现。 Recency计算:recency = snapshot_date - 最近一次用户购买日期; Frequency计算:统计一下过去一年用户购买了多少次,这部分可以统计InvoiceNo的总数就可以了。通过count函数实现; Monetary计算:过去一年总花费的金额可以累加TotalSum字段就可以,使用sum函数实现。
# 写一段Aggregation函数来创建一个新的dataframe
def func(a):
return (snapshot_date-a.max()).days
data_rfm = df.groupby(['CustomerID']).agg({
'InvoiceDate': func,
'InvoiceNo': 'count',
'TotalSum': 'sum'
}).sort_index(ascending=True)
# 重新命名一下Columns
data_rfm.rename(columns = {'InvoiceDate': 'Recency',
'InvoiceNo': 'Frequency',
'TotalSum': 'MonetaryValue'}, inplace=True)
data_rfm.head()到目前为止,Recency, Frequency, MonetaryValue都是数值型的。 为了用户分群,我们需要把R,F,M的值分别需要映射到bucket中,比如Recency的值映射到1,2,3,4中的某一个数值上; Frequency映射到1,2,3,4中的某一个数值上,MonetaryValue也做同样的处理。 这里需要注意的一点是:值越大就说明用户越有价值,比如R=4的用户要比R=1的用户的价值更大。 所以当我们尝试映射的时候,也需要注意这一点。 因为Recency越大说明好久没有买了,所以这时候映射之后的数要越小; 相反,对于Frequency字段,这个值越大就说明用户购买次数越多,映射之后的值也需要越大; 所以我们需要考虑这一点。
具体映射时候需要用到的技术在课程里面也讲过,使用quantitle就可以了。 把一组数据通过quantitle分成25%, 50%, 75%点, 这样就可以分成4块了,然后每一块分别赋值,1,2,3,4就可以了。 取quantitle的时候可以直接使用 pd.qcut函数。
#创建三个新的Column, 分别表示R,F,M的quntitle值
rank_list = list(range(1,5))
rank_list_reverse = list(range(4,0,-1))
Rquartiles = pd.qcut(data_rfm['Recency'],4,labels=rank_list_reverse) # your code
data_rfm = data_rfm.assign(Recency_Q = Rquartiles.values)
Fquartiles = pd.qcut(data_rfm['Frequency'],4,labels=rank_list)# your code
data_rfm = data_rfm.assign(Frequency_Q = Fquartiles.values)
Mquartiles = pd.qcut(data_rfm['MonetaryValue'],4,labels=rank_list) # your code
data_rfm = data_rfm.assign(Moneytary_Q = Mquartiles.values)# 创建一个新的column叫作segment, 比如Recency_Q = 1, Frequency_Q = 2, Monetary_Q=4, 则segment为124.
# 实现过程就是直接把每一个值拼接在一起。
data_rfm['Segment'] = data_rfm[['Recency_Q','Frequency_Q','Moneytary_Q']].apply(lambda x: ''.join(x.map(str)), axis=1)
data_rfm.head()接下来计算一下RFM_Score。这个值越大说明,说明这个用户价值越大。对于Score可以有不同的计算方式。但在这里我们使用最简单而且最经典的计算方法,其实就是把所有的值加在一起。 比如一个客户的 R=1, F=2, M=3, 则这个客户的RFM_Score为6。
# 创建一个新的column叫作RFM_Score
data_rfm['RFM_Score'] = data_rfm[['Recency_Q','Frequency_Q','Moneytary_Q']].sum(axis=1)# your code
有了RFM_Score之后,就可以对用户分群了。 这个值越大,我们可以认为这个用户价值越高。 现在我们希望把用户分层三大类, 金牌客户,银牌客户,以及普通客户,那如何做分群呢? 一种简单的方法是定义阈值的方式做。比如RFM_Score在某一个区间就认为是金牌客户,银牌客户等等。 在这里,我们就使用这种方法,规则为:
- Gold: RFM_Score >= 9 的时候
- Silver: RFM_Score >= 5 and RFM_Score < 9 的时候
基于K-means算法的分群
接下来我们通过使用k-means算法来对用户分群,使用的值仍然是Recency, Frequency, Moneytary Value. 当我们使用k-means算法的时候经常需要做预处理工作,因为算法依赖于距离的计算,而且R,F,M的值的范围差别很大。
对于预处理,我们做如下2个方面的工作:
- 即使针对于某一个属性,它的值差别很大,所以我们先使用log transform把值做个转换
- 使用归一化操作把值映射到 N(0,1),使用的是
sklearn里的StandardScaler。
# 只选取R,F,M的值
data_rfm = data_rfm[['Recency','Frequency', 'MonetaryValue']]
# 1. 先做log transform, +1是为了避免log(0)
data_rfm = np.log(data_rfm+1)
# 2. 归一化操作
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(data_rfm)
data_rfm = scaler.transform(data_rfm)接下来试着使用K-Means算法对R,F,M的值做聚类。 首先,需要选出最合适的K值,这里使用的方法是对于每一个K值计算Distortion score,并把这个值按照K值来可视化,之后根据可视化的结果来选择合适的K值。完整的代码已经给出,只需要运行就可以看到可视化结果。
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
import seaborn as sns
sse = {}
for k in range(2, 11):
kmeans = KMeans(n_clusters=k, random_state=99).fit(data_rfm)
cluster_labels = kmeans.labels_
sse[k] = kmeans.inertia_
plt.title('Distortion Score Elbow for KMeans')
sns.pointplot(x=list(sse.keys()), y=list(sse.values()))
plt.show()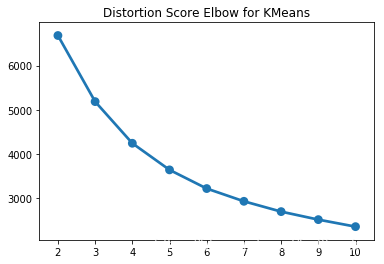
基于上图,选择较好的三个K值:3,4,5。
对于每一个K值,训练K-means算法,按照K-means的结果把用户分群,最后展示每一个群体的R, F, M的平均值。
# 第一个K值: K = 3
kmeans_3 = KMeans(n_clusters=3,random_state=100).fit(data_rfm)
cluster_labels_3 = kmeans_3.labels_
average_rfm_3 = kmeans_3.cluster_centers_
print(average_rfm_3)# 第二个K值: K = 4
kmeans_4 = KMeans(n_clusters=4,random_state=100).fit(data_rfm)
cluster_labels_4 = kmeans_4.labels_
average_rfm_4 = kmeans_4.cluster_centers_
print(average_rfm_4)# 第三个K值: K = 5
kmeans_5 = KMeans(n_clusters=5,random_state=100).fit(data_rfm)
cluster_labels_5 = kmeans_5.labels_
average_rfm_5 = kmeans_5.cluster_centers_
print(average_rfm_5)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









