




本项目的目标是基于用户提供的评论,通过算法自动去判断其评论是正面的还是负面的情感。比如给定一个用户的评论:
- 评论1: “我特别喜欢这个电器,我已经用了3个月,一点问题都没有!”
- 评论2: “我从这家淘宝店卖的东西不到一周就开始坏掉了,强烈建议不要买,真实浪费钱”
对于这两个评论,第一个明显是正面的,第二个是负面的。 我们希望搭建一个AI算法能够自动帮我们识别出评论是正面还是负面。
情感分析的应用场景非常丰富,也是NLP技术在不同场景中落地的典范。比如对于一个证券领域,作为股民,其实比较关注舆论的变化,这个时候如果能有一个AI算法自动给网络上的舆论做正负面判断,然后把所有相关的结论再整合,这样我们可以根据这些大众的舆论,辅助做买卖的决策。 另外,在电商领域评论无处不在,而且评论已经成为影响用户购买决策的非常重要的因素,所以如果AI系统能够自动分析其情感,则后续可以做很多有意思的应用。
情感分析是文本处理领域经典的问题。整个系统一般会包括几个模块:
- 数据的抓取: 通过爬虫的技术去网络抓取相关文本数据
- 数据的清洗/预处理:在本文中一般需要去掉无用的信息,比如各种标签(HTML标签),标点符号,停用词等等
- 把文本信息转换成向量: 这也成为特征工程,文本本身是不能作为模型的输入,只有数字(比如向量)才能成为模型的输入。所以进入模型之前,任何的信号都需要转换成模型可识别的数字信号(数字,向量,矩阵,张量...)
- 选择合适的模型以及合适的评估方法。 对于情感分析来说,这是二分类问题(或者三分类:正面,负面,中性),所以需要采用分类算法比如逻辑回归,朴素贝叶斯,神经网络,SVM等等。另外,我们需要选择合适的评估方法,比如对于一个应用,我们是关注准确率呢,还是关注召回率呢?
1. 数据读取
import re
import pandas as pd
import numpy as np
def process_file():
"""
读取训练数据和测试数据,并对它们做一些预处理
"""
global train_comments
global train_labels
global test_comments
global test_labels
train_pos_file = "data/train_positive.txt"
train_neg_file = "data/train_negative.txt"
test_comb_file = "data/test_combined.txt"
df_pos=generate_dataframe(train_pos_file)
df_neg=generate_dataframe(train_neg_file)
df_com=generate_dataframe(test_comb_file)
# TODO: 读取文件部分,把具体的内容写入到变量里面
train_comments = list(df_pos.append(df_neg)['Comment'])
train_labels = list(df_pos.append(df_neg)['Label'])
test_comments = list(df_com['Comment'])
test_labels=list(df_com['Label'])
def generate_dataframe(filepath):
"""
generate a dataframe to store the comments and labels
"""
_comments = open(filepath,encoding='utf-8').read().replace('\n','').split('</review>')
#remove empty elements
while '' in _comments:
_comments.remove('')
#create DataFrame object to store Comments and Labels
local_comments=[]
local_labels=[]
if filepath.find('pos') > 0:#for pos file
for i in range(len(_comments)):
if i == 0:
text = re.findall('^\ufeff<.*>(.*)',_comments[i])
local_comments.append(text[0])
else:
text = re.findall('^<.*>(.*)',_comments[i])
local_comments.append(text[0])
df=pd.DataFrame(local_comments,columns=['Comment'])
label_pos=[1 for local_comment in range(len(local_comments))]
df['Label']=label_pos
elif filepath.find('neg') > 0:#for neg file
for j in range(len(_comments)):
text = re.findall('^<.*>(.*)',_comments[j])
local_comments.append(text[0])
df=pd.DataFrame(local_comments,columns=['Comment'])
label_neg=[0 for local_comment in range(len(local_comments))]
df['Label']=label_neg
else:# for combined file
for k in range(len(_comments)):
text = re.findall('^<.*>(.*)',_comments[k])
local_comments.append(text[0])
numbers = re.findall('<.*>',_comments[k])
local_labels.append(numbers[0][-3])
local_labels = [int(x) for x in local_labels]
df=pd.DataFrame(local_comments,columns=['Comment'])
df['Label']=local_labels
return df
train_comments = []
train_labels = []
test_comments = []
test_labels = []
process_file()
# print("****************Train Comments**************:\n",train_comments)
# print("****************Train Labels**************:\n",train_labels)
# print("****************Test Comments**************:\n",test_comments)
# print("****************Test Labels**************:\n",test_labels)
2. 可视化分析
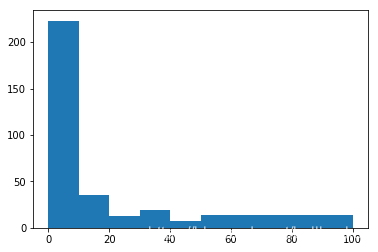
这里有一个假设想验证。我觉得,如果一个评论是负面的,则用户留言时可能会长一些,因为对于负面的评论,用户很可能会把一些细节写得很清楚。但对于正面的评论,用户可能就只写“非常好”,这样的短句。我们想验证这个假设。 为了验证这个假设,打算画两个直方图,分别对正面的评论和负面的评论。 具体的做法是:1. 把正面和负面评论分别收集,之后分别对正面和负面评论画一个直方图。 2. 直方图的X轴是评论的长度,所以从是小到大的顺序。然后Y轴是对于每一个长度,出现了多少个正面或者负面的评论。 通过两个直方图的比较,即可以看出评论是否是一个靠谱的特征。
# 对于训练数据中的正负样本,分别画出一个histogram, histogram的x抽是每一个样本中字符串的长度,y轴是拥有这个长度的样本的百分比。
import pandas as pd
import matplotlib.pyplot as plt
df_both = pd.DataFrame({'Comment':train_comments,'Label':train_labels})
df_pos = df_both.loc[df_both['Label']==1]['Comment']
df_neg = df_both.loc[df_both['Label']==0]['Comment']
pos_pivot=df_pos.str.len().value_counts()
neg_pivot=df_neg.str.len().value_counts()
plt.hist(pos_pivot,bins=[0,10,20,30,40,50,100])
plt.show()
plt.hist(neg_pivot,bins=[0,10,20,30,40,50,100])
plt.show()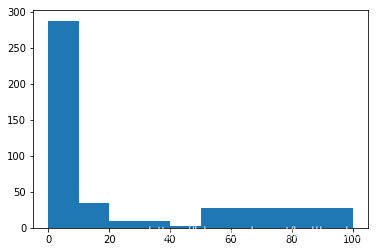
3. 文本预处理
在此部分需要做文本预处理方面的工作。 分为几大块:
去掉特殊符号比如#$.... 这部分的代码已经给出,不需要自己写把数字转换成特殊单词把数字转换成 " NUM ", 这部分需要写。 注意:NUM前面和后面加一个空格,这样可以保证之后分词时被分掉。分词并过滤掉停用词停用词库已经提供,需要读取停用词库,并按照此停用词库做过滤。 停用词库使用给定的文件:stopwords.txt
def clean_symbols(text):
"""
对特殊符号做一些处理,此部分已写好。如果不满意也可以自行改写,不记录分数。
"""
text = re.sub('[!!]+', "!", text)
text = re.sub('[??]+', "?", text)
text = re.sub("[a-zA-Z#$%&\'()*+,-./:;:<=>@,。★、…【】《》“”‘’[\\]^_`{|}~]+", " OOV ", text)
return re.sub("\s+", " ", text)
# 对于train_comments, test_comments进行字符串的处理
import re
import jieba
stopwords_path = 'data/stopwords.txt'
stopwords = open(stopwords_path,encoding='utf-8').read().splitlines()
# 1. 去掉特殊符号
# 2. 把数字转换成特殊字符或者单词
# 3. 分词并做停用词过滤
# 4. ... (或者其他)#
# 需要注意的点是,由于评论数据本身很短,如果去掉的太多,很可能字符串长度变成0
# 预处理部分,可以自行选择合适的方法.
seg_train_lists=[]
seg_test_lists=[]
for train_comment in train_comments:
clean_symbols(train_comment)# 1. 去掉特殊符号
train_comment = re.sub('\d',' NUM ',train_comment)# 2. 把数字转换成特殊字符或者单词
cut_train=jieba.cut(train_comment)# 3. 分词并做停用词过滤(训练数据)
# for word in cut_train:
# print(word)
# seg_train.append(word)
# train_seg_temp = seg_train[i]#
seg_train=[word for word in cut_train if word not in stopwords]
seg_train_lists.append(seg_train)
for test_comment in test_comments:# 3. 分词并做停用词过滤(测试数据)
clean_symbols(test_comment)
test_comment = re.sub('\d',' NUM ',test_comment)
cut_test=jieba.cut(test_comment,cut_all=False)
# for word in cut_test:
# seg_test.append(word)
# test_seg_temp = seg_test[i]
seg_test=[word for word in cut_test if word not in stopwords]
seg_test_lists.append(seg_test)
train_comments_cleaned = seg_train_lists
test_comments_cleaned = seg_test_lists4. 把文本转换为向量
预处理好文本之后,我们就需要把它转换成向量形式,这里我们使用tf-idf的方法。 sklearn自带此功能,直接调用即可。输入就是若干个文本,输出就是每个文本的tf-idf向量。详细的使用说明可以在这里找到: 参考:https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
# 利用tf-idf从文本中提取特征,写到数组里面.
# 参考:https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
X_train = tfidf.fit_transform(train_comments)# 训练数据的特征
X_test = tfidf.transform(test_comments)# 测试数据的特征
y_train = train_labels # 训练数据的label
y_test = test_labels # 测试数据的label
print (np.shape(X_train), np.shape(X_test), np.shape(y_train), np.shape(y_test))5. 交叉验证训练模型
这里我们分别使用逻辑回归,朴素贝叶斯和SVM来训练。针对于每一个方法我们使用交叉验证(gridsearchCV), 并选出最好的参数组合,然后最后在测试数据上做验证。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
import warnings
warnings.filterwarnings('ignore')
# 利用逻辑回归来训练模型
# 1. 评估方式: F1-score
# 2. 超参数(hyperparater)的选择利用grid search
# 3. 打印出在测试数据中的最好的结果(precision, recall, f1-score, 需要分别打印出正负样本,以及综合的)
params_c = np.logspace(-5,2,15)
model = GridSearchCV(estimator = LogisticRegression(penalty='l2'),param_grid={'C':params_c},scoring='f1',cv=10)
model.fit(X_train,y_train)
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))
from sklearn.naive_bayes import MultinomialNB
# 利用朴素贝叶斯来训练模型
# 1. 评估方式: F1-score
# 2. 超参数(hyperparater)的选择利用grid search
# 3. 打印出在测试数据中的最好的结果(precision, recall, f1-score, 需要分别打印出正负样本,以及综合的)
params_alpha= [1]
model = GridSearchCV(estimator = MultinomialNB(fit_prior=True),param_grid = {'alpha':params_alpha},scoring='f1',cv=10)
model.fit(X_train,y_train)
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))
from sklearn import svm
# 利用SVM来训练模型
# 1. 评估方式: F1-score
# 2. 超参数(hyperparater)的选择利用grid search
# 3. 打印出在测试数据中的最好的结果(precision, recall, f1-score, 需要分别打印出正负样本,以及综合的)
params = [
{'kernel': ['linear'], 'C': [1, 10]},
{'kernel': ['poly'], 'C': [1]},
{'kernel': ['rbf'], 'C': [10], 'gamma':[1, 0.1]}
]
model = GridSearchCV(estimator = svm.SVC(),param_grid = params,scoring='f1',cv=10)
model.fit(X_train,y_train)
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









