







 Pandas是基于Numpy构建的数据处理库,核心数据结构包括DataFrame和Series。Series是一维数组对象,可看作是数组和字典的结合,支持数值计算和索引操作。创建Series可以通过列表或数组,索引可以是数字位置或自定义index。Series支持数学运算、通用函数及字典特性,如与标量计算、布尔筛选等。在与DataFrame运算时,会按列匹配索引并进行广播。
Pandas是基于Numpy构建的数据处理库,核心数据结构包括DataFrame和Series。Series是一维数组对象,可看作是数组和字典的结合,支持数值计算和索引操作。创建Series可以通过列表或数组,索引可以是数字位置或自定义index。Series支持数学运算、通用函数及字典特性,如与标量计算、布尔筛选等。在与DataFrame运算时,会按列匹配索引并进行广播。
Pandas是基于Numpy构建的,主要用于灵活的数据处理,和numpy配合使用
1. 简介
Pandas主要功能
- 具备两种数据结构DataFrame,Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
2. Series---- 一维数组对象
Series是一种类似于一维数组的对象(有点类似于数组和字典的结合体),由一组数据和
2.2 Series 的建立
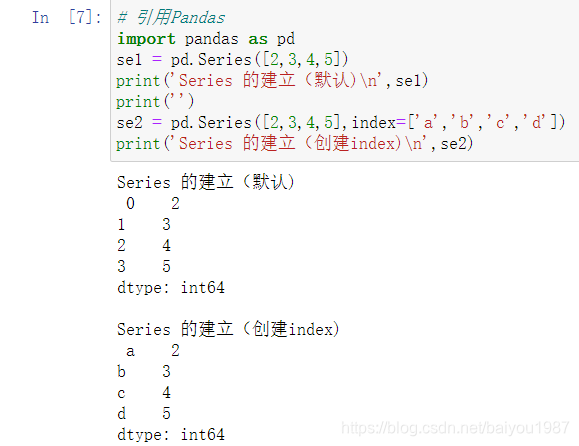
2.2.1 列表形式创建
pd.Series()方法创建Series对象,其中的参数包括value和index:
-
values:列表形式;
- index:列表形式,如果缺省,则index为range(0,N)
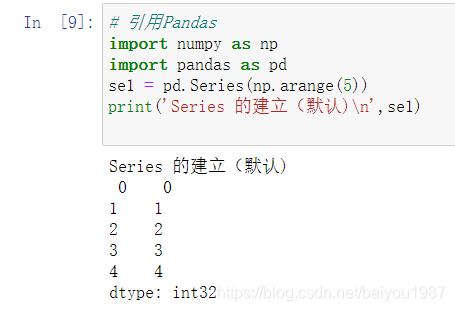
2.2.2 数组形式创建
通过np.arange建立一个数组,然后通过pd.Series()建立序列
2.3 Series 的索引
Series实际由两种索引,一种是按照数字位置索引(从0开始),另一种是按照index索引,如下面的例子

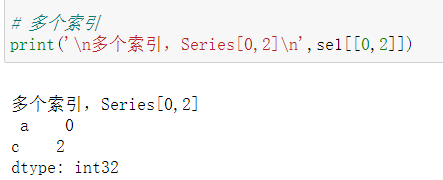
如果是对多个独立索引进行访问,则需要使用队列形式,如下面的例子
Series的切片,使用切片的时候要注意是左闭右开如[1:4]实际是[1,2,3]

2.4 Series 的计算
2.4.1 和标量的计算
和numpy里array用法相同可以和标量进行计算。

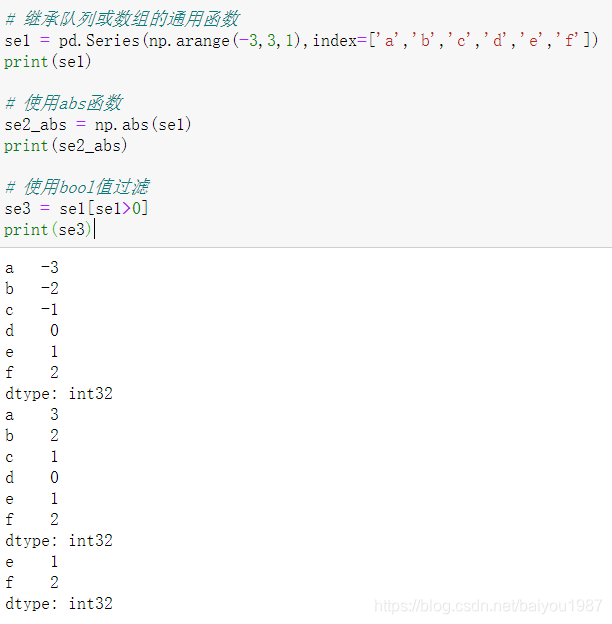
2.4.2 支持通用函数
继承列表或者数组的运算,如np.abs(sr),sr[sr>0]等。
2.4.3 继承字典的特性
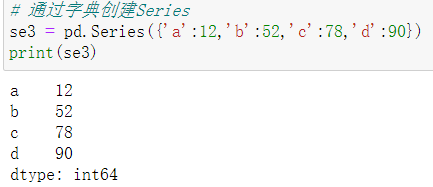
- 从字典创建Series:Series(dic)
- in运算:'a' in sr
- 键索引:sr['a']
3. 4 DataFrame 和 Series之间的运算
默认情况下,DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame的列,然后沿着行向下广播。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









