




最近在学习多模态的算法和工程优化,以下是个人的一些总结,对多模态大模型有兴趣的朋友欢迎讨论交流~
1 多模态学习路线规划
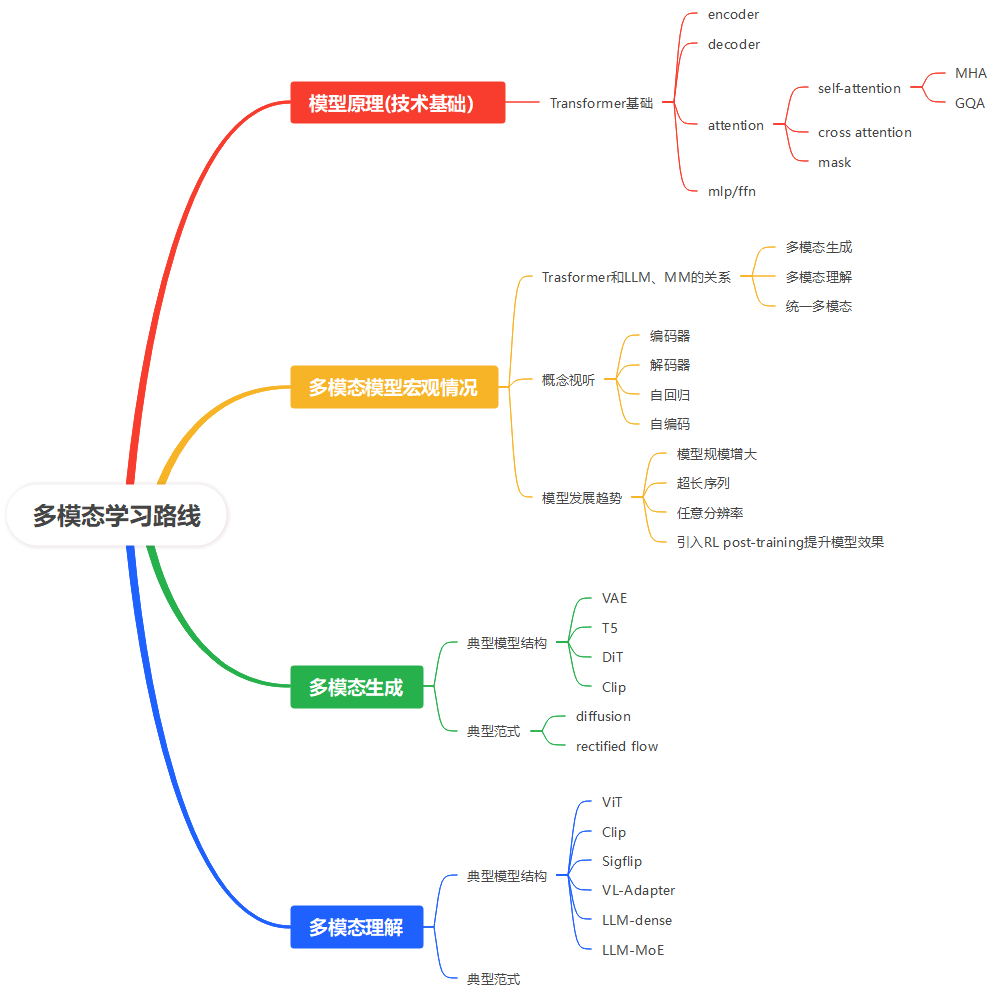
2 经典论文阅读计划
| 模型 | 论文链接 | 发布时间 | 一句话描述贡献 |
| Transformer(Attention Is All You Need) | 2017-06 | 提出 Transformer 架构,完全基于自注意力机制,无需 RNN/CNN,奠定后续所有 LLM 与多模态大模型的通用底座。 | |
| ViT | 2020-10 | 首次证明“纯 Transformer 直接作用于 16×16 图像块序列”即可在大规模预训练后取得 SOTA 分类效果,无需卷积。 | |
| CLIP | 2021-02 | 利用 4 亿图文对训练双塔 Transformer,实现“零样本”图像分类与图文检索,把视觉概念映射到文本语义空间。 | |
| Flamingo | 2022-04 | 在冻结的 LLM 前插入交叉注意力池化层,仅用少量图文交错数据就能让模型输出开放式文本描述,奠定“冻结 LLM + 视觉连接器”范式。 | |
| BLIP-2 | 2023-01 | 提出轻量 Q-Former 把 ViT 特征压缩成 32 个查询 token,零样本指令下也能让冻结的 LLM 生成准确字幕并回答视觉问题。 | |
| LLaVA | 2023-04 | 将图片切块经 ViT 线性投影后与文本 prompt 拼接,端到端微调 LLM,首次展示 GPT-4 级多模态对话能力且代码开源。 | |
| GPT-4V | 无论文(技术报告) | 2023-09 | OpenAI 公布的 GPT-4 视觉接口,用同一套 Transformer 同时接受图像+文本输入并生成文本,首次把大规模多模态能力产品化。 |
| Gemini | 2023-12 | Google 发布的多模态 Gemini 系列,用原生 Transformer 端到端训练文本、图像、音频、视频统一 tokenizer,在多项基准上超越 GPT-4V。 |

















 2319
2319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









