




 LevelDB是Google提供的高性能K-V存储引擎,支持数据压缩、原子操作及一致性快照。本文详细介绍了其特性,如自定义比较函数、数据迭代及Snappy压缩,同时也探讨了其局限性,包括不支持SQL查询和单一进程访问等。文章还深入解析了关键数据结构如Slice、SkipList及BloomFilter,并概述了LevelDB的整体架构,涉及MemTable、SSTable、WALLog等核心组件。
LevelDB是Google提供的高性能K-V存储引擎,支持数据压缩、原子操作及一致性快照。本文详细介绍了其特性,如自定义比较函数、数据迭代及Snappy压缩,同时也探讨了其局限性,包括不支持SQL查询和单一进程访问等。文章还深入解析了关键数据结构如Slice、SkipList及BloomFilter,并概述了LevelDB的整体架构,涉及MemTable、SSTable、WALLog等核心组件。
LevelDB是一个由Google提供的K-V型的存储引擎, 具有非常高的写入性能, 目前很多的存储系统底层都会用到LevelDB及其基础上的RocksDB。
LevelDB的特征
- 所有的key和value是任意的字符数组;
- 按照key的排序来存储数值;
- 使用者可以定制比较函数, 来覆盖默认的比较函数;
- 基本的操作是:Put(key,value), Get(key), Delete(key);
- 多个改变数值操作可以在一个原子任务执行;
- 用户可以创建一个瞬时的snapshot来得到数据的一致性;
- 数据上的iterator支持向前和向后移动;
- 数据自动使用Snappy压缩库进行压缩;
- 外部动作(比如, 文件系统操作)依赖于虚拟接口, 因此用户可以定制文件系统交互。
LevelDB的limitations:
- 它不是一个SQL数据库, 它不支持关系型数据模型, 它也不支持SQL查询以及索引;
- 在同一时刻, 只有一个进程(可能多个线程)可以访问某一个LevelDB数据库;
- 没有内嵌的客户端-服务器。 需要这样支持的应用程序, 需要把该库程序wrap到他们的应用中;
基本数据结构
像其他数据库一样, LevelDB也定义了一些自己的数据结构:
- Slice
Slice是一个类似于string的类,用于管理字符串,相比较于String支持的许多操作,Slice只包含最简单和基本的功能,也就是字符串的地址、字符串的大小;与string不同的是,Slice自己本身并不提供存储字符串的空间,而是保留字符串的指针。
class Slice {
public:
// Create an empty slice.
Slice() : data_(""), size_(0) { }
// Create a slice that refers to d[0,n-1].
Slice(const char* d, size_t n) : data_(d), size_(n) { }
// Create a slice that refers to the contents of "s"
Slice(const std::string& s) : data_(s.data()), size_(s.size()) { }
// Create a slice that refers to s[0,strlen(s)-1]
Slice(const char* s) : data_(s), size_(strlen(s)) { }
// Return a pointer to the beginning of the referenced data
const char* data() const { return data_; }
// Return the length (in bytes) of the referenced data
size_t size() const { return size_; }
//other functions
private:
const char* data_;
size_t size_;
// Intentionally copyable
};
-
Skiplist
SkipList的定义:
1、 一个跳表应该有几个层(level)组成;
2、跳表的第一层包含所有的元素;
3、每一层都是一个有序的链表;
4、如果元素x出现在第i层,则所有比i小的层都包含x;
5、第i层的元素通过一个down指针指向下一层拥有相同值的元素;
6、在每一层中,-1和1两个元素都出现(分别表示INT_MIN和INT_MAX);
7、Top指针指向最高层的第一个元素。
Skiplist 详细介绍 -
bloom filter(布隆过滤器)
bloom filter是一种二进制向量数据结构, 每一位有0或者1 表示某个映射到该位的哈希函数的计算结果。
查询一个数据是否存在于BloomFiler中,即将数据通过K个哈希函数分别映射到位列上,看位列相应的位置上的位值是否都为1:
如果都为1,则说明可能存在;
如果任何一位为0,则说明一定不存在。
具体的实现可以参考代码: $LEVELDB/util/bloom.cc
BloomFilter 详细介绍
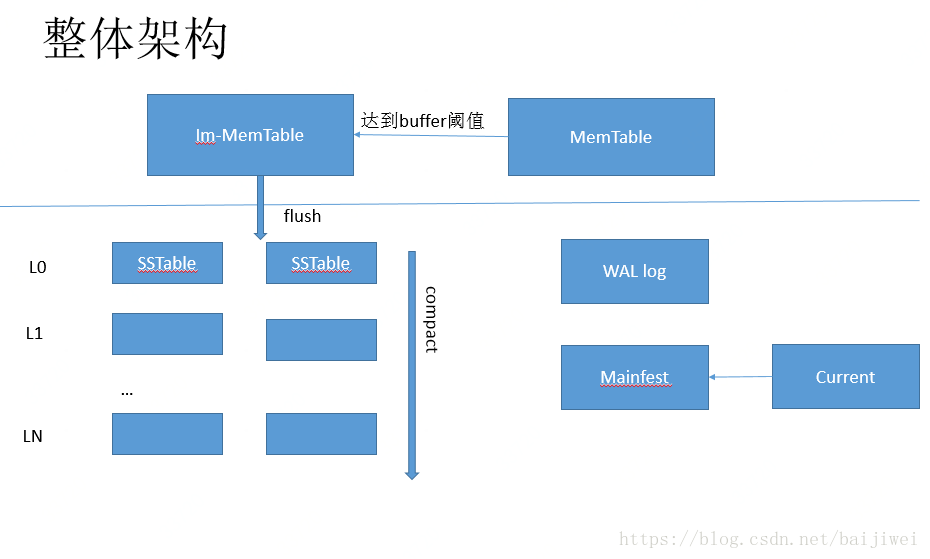
LevelDB的整体架构
整个LevelDB的数据以4种形式存在: memtable, immemtable, SSTable, WAL log, Mainfest 文件以及current:
-
MemTable
MemTable是内存的数据存储以及操作, 所有新插入或者更新的k-v数据, 首先会保存在MemTable里面, 需要注意一点, LevelDB的所有操作, 包含删除, 都是在MenTable里面最后面添加一条记录。 也就是说, 所有的随机操作都变成了顺序操作, 而且还是内存的操作,所以它的写入操作才会有非常高的效率。 -
im-MemTable
MemTable的数据是直接存入内存的, 拥有很高的效率, 但是内存的数量是一定的, 当达到设定的阈值以后, 它就变成只读型的MemTable, 被称为im-MemTable, 等待compact线程, 将内存的数据专才到磁盘上面。 -
SSTable
im-MemTable被写入磁盘后变成了SSTable, 除了L0以外, 其他层的数据在每一个SSTable内部是有序的。 随着新的数据插入, 低层有可能和高层有重叠, 这就需要compact线程, 来进行数据的搬迁以及SSTable的删除以及生成新的。 -
WAL log
与其他的数据库一样, LevelDB也是用了WAL Log机制来保证数据的不丢失,在写入数据到MEMTable之前, 先向log 文件陷入日志记录, 这样即便LevelDB以外退出, 通过回放Log也可以保证没有写入磁盘的数据不会丢失。 -
Mainfest
LevelDB的分层机制, 可以保证在数据查询的时候比较有效地找到目的SSTable, 但是如果不知道某一层的Key的范围, 也没有办法做到最有的查询。 Mainfest主要是用来记录每一层Key的范围以及每一个SST的范围。 -
Current
Current是记录当前的Mainfest文件。

















 7243
7243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









