 数据纵向完全合并:concat操作详解
数据纵向完全合并:concat操作详解





 本节介绍如何使用pandas的concat函数将相同结构的CSV数据文件纵向完全合并。通过读取并合并transaction_1.csv和transaction_2.csv,展示了如何忽略索引并检查合并后的行数以确保完整性。进一步讨论了将不同数据集横向合并的问题。
本节介绍如何使用pandas的concat函数将相同结构的CSV数据文件纵向完全合并。通过读取并合并transaction_1.csv和transaction_2.csv,展示了如何忽略索引并检查合并后的行数以确保完整性。进一步讨论了将不同数据集横向合并的问题。
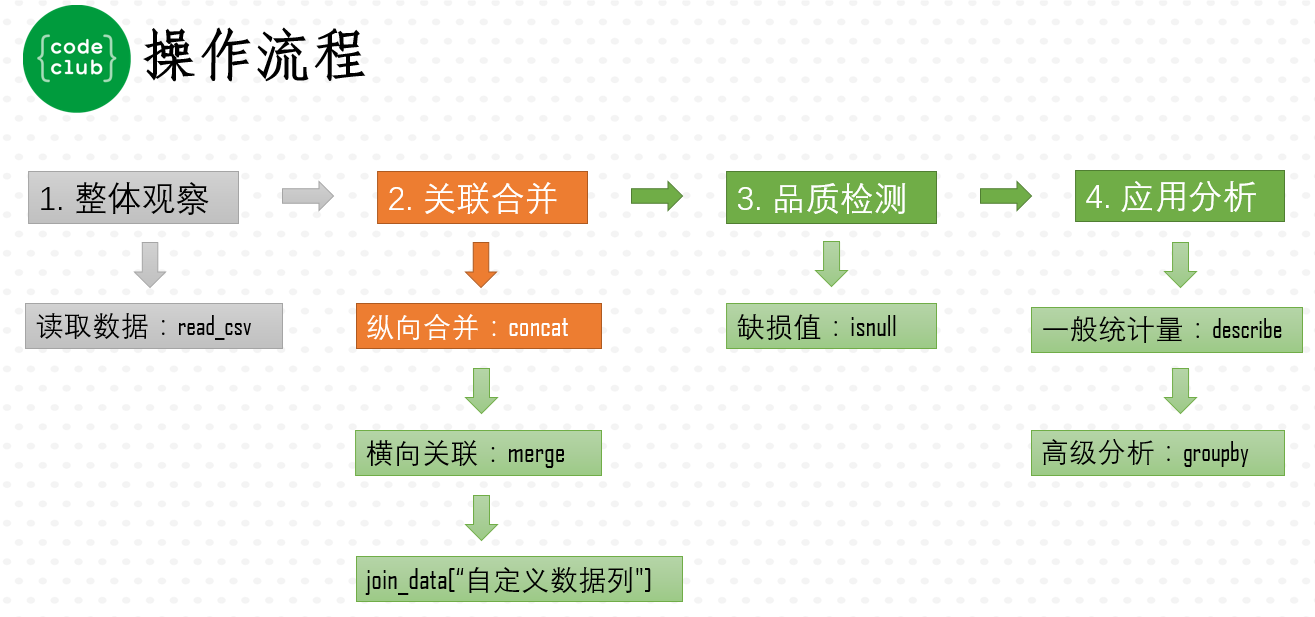
这一节,我们学习如何将“transaction_1.csv”文件和“transaction_2.csv”文件合并起来。观察这两个数据文件可以发现,数据文件的数据列都是一样的。这种情况下的所谓合并,就是相同结构下数据量的增加,好比原来是11层楼(transaction_1.csv),现在再增加盖5层楼(transaction_2.csv)的意思,也就是数据的纵向完全合并。
上一节中,我们已经将“transaction_1.csv”文件转换成了transaction_1 变量,接下来,再读取“transaction_2.csv”文件,转换成transaction_2 变量。代码如下:
transaction_2 = pd.read_csv('transaction_2.csv')
transaction = pd.concat([transaction_1,transaction_2],ignore_index=True)
transaction.head()
解释一下代码:
第1行:使用pandas中的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2727
2727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









