




 博客介绍了在Jupyter Notebook中使用Python的pandas库读取CSV数据的过程,通过`read_csv`函数加载数据并利用`head()`显示数据前5行以理解数据列关系。以customer_master.csv为例,展示了如何读取和预览多个数据文件,强调了在数据分析前理解数据轮廓的重要性,特别是transaction_1和transaction_detail_1数据对于满足刘先生提升店铺销量需求的关键作用。下一步将探讨如何合并transaction_1.csv和transaction_2.csv进行完整分析。
博客介绍了在Jupyter Notebook中使用Python的pandas库读取CSV数据的过程,通过`read_csv`函数加载数据并利用`head()`显示数据前5行以理解数据列关系。以customer_master.csv为例,展示了如何读取和预览多个数据文件,强调了在数据分析前理解数据轮廓的重要性,特别是transaction_1和transaction_detail_1数据对于满足刘先生提升店铺销量需求的关键作用。下一步将探讨如何合并transaction_1.csv和transaction_2.csv进行完整分析。
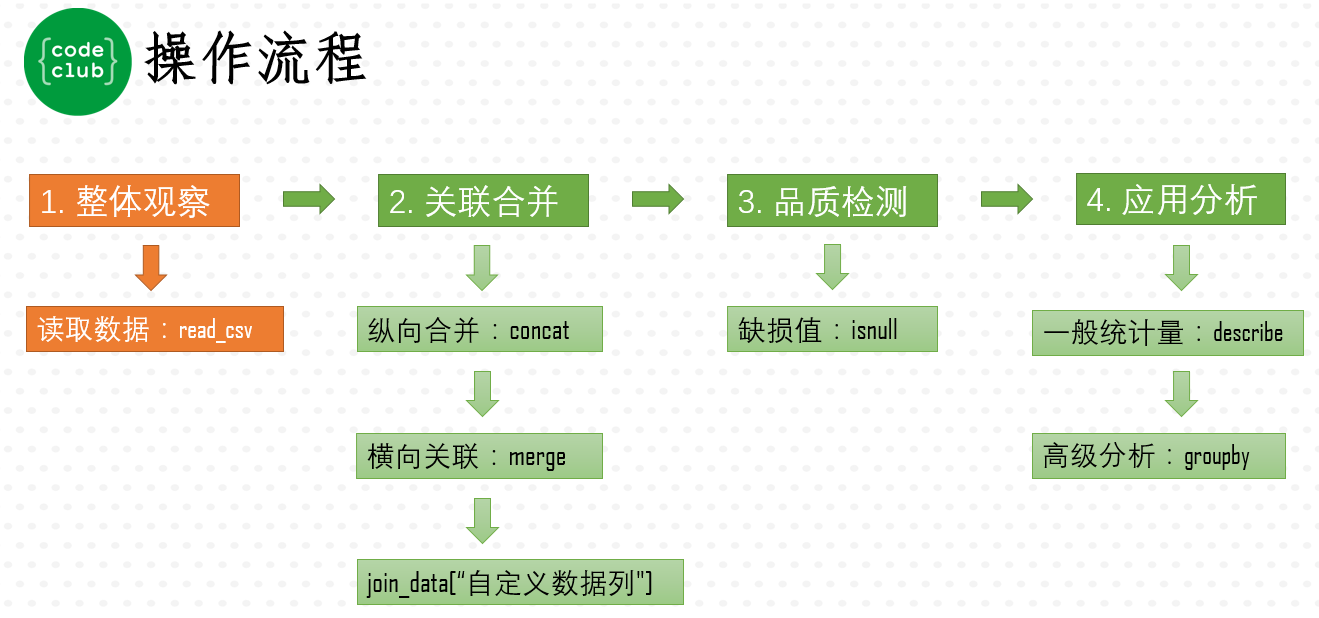
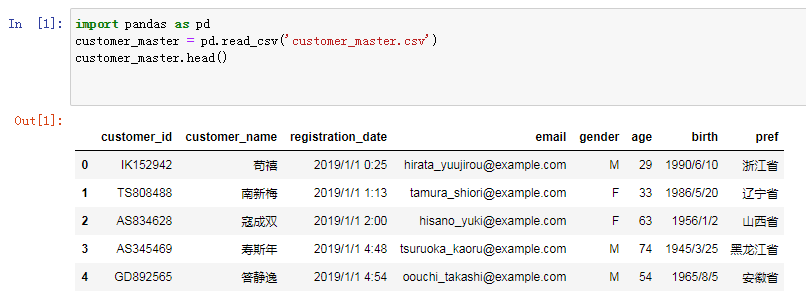
数据文件上传到jupyter notebook后,接下来,就开始读取各个数据文件,然后将每个数据文件的前5行数据内容显示出来,观察一下数据列之间的关系。比如,首先来读取customer_master.csv文件中的内容,代码如下:
import pandas as pd
customer_master = pd.read_csv('customer_master.csv')
customer_master.head()
解释一下代码:
第1行:引入Python的软件包——pandas。
第2行:使用pandas中的read_csv函数,读取外部的“customer_master.csv”文件,转换成pandas的处理数据对象,存储到customer_master变量中,这个变量就是类似表格的数据结构。
第3行:使用head()函数,将customer_master变量的前5行数据显示出来。
点击"运行",执行效果如下图所示。
按照同样的方法,我们把其它数据文件也读取并显示出
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9390
9390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









