







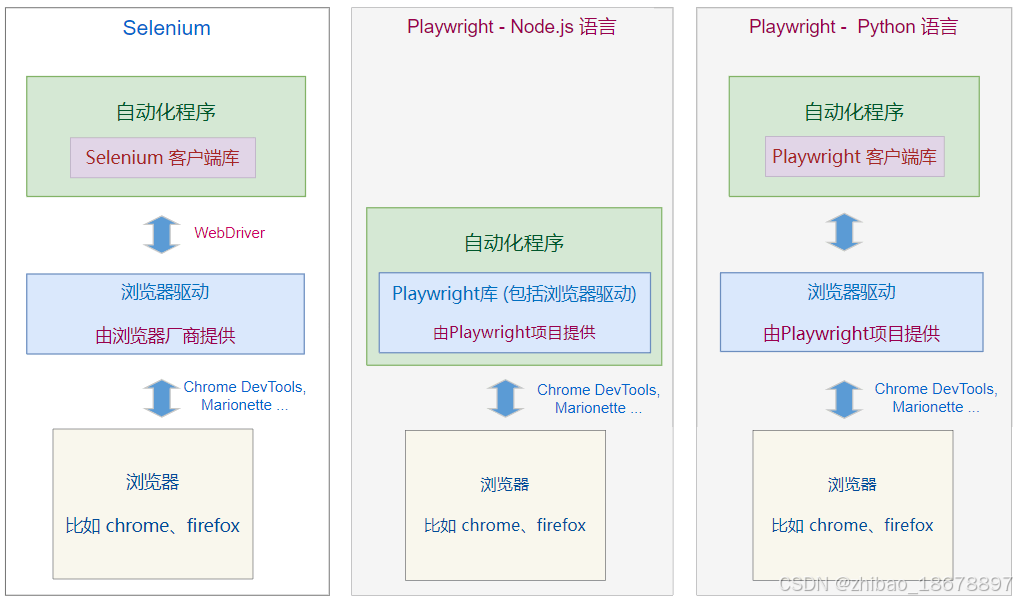
Playwright 支持多种语言开发,比如 JavaScript/TypeScript, Python, Java, C#
本教程 使用的是 Python语言
1.安装:
pip install playwright
playwright install chromium
# 1.安装 playwright 客户端库
# 执行 pip install playwright
#
# 2.安装 浏览器
# playwright 默认使用自己编译好的浏览器,比如 chromium, firefox, webkit
# playwright install 将安装三款浏览器
# playwright install chromium 指定安装一款浏览器
#
# playwright 也可以自动化 已经安装好的品牌浏览器,比如Chrome, Edge, Firefox等,后文会有讲解
# 品牌浏览器往往会自动更新,如果使用Selenium自动化,就需要不断下载新的驱动。
# playwright使用自编译浏览器不会自动更新,从而避免驱动和浏览器不匹配的问题。
2.简单示例
from playwright.sync_api import sync_playwright
input('1....')
# 启动 playwright driver 进程
p = sync_playwright().start()
input('2....')
# 启动浏览器,返回 Browser 类型对象
browser = p.chromium.launch(headless=False) # 无头模式=假
# 创建新页面,返回 Page 类型对象
page = browser.new_page()
page.goto("https://www.byhy.net/cdn2/files/selenium/stock1.html") #打开指定网页
print(page.title()) # 打印网页标题栏
# 输入通讯,点击查询。这是定位与操作,是自动化重点,后文详细讲解
# locator查询 #按ID查询 fill写入内容 click点击
page.locator('#kw').fill('通讯') # 输入通讯 在page页面,通过 locator方法按ID查询,然后填写数据
page.locator('#go').click() # 点击查询
# 打印所有搜索内容
lcs = page.locator(".result-item").all()
for lc in lcs:
print(lc.inner_text())
input('3....')
# 关闭浏览器
browser.close()
input('4....')
# 关闭 playwright driver 进程
p.stop()3.使用其它浏览器
# 使用其它浏览器
# 可以换一种启动firefox浏览器
browser = p.firefox.launch(headless=False)
# 可以换一种启动webkit浏览器
browser = p.webkit.launch(headless=False)
# 使用 系统自带浏览器
# 加上 executable_path参数
browser = p.chromium.launch(headless=False,executable_path='c:\Program Files\Google\Chrome\Application\chrome.exe') # 程序路径4.使用 with as 会话管理
代码简化,不需要调用 start() 和 stop()
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.byhy.net/cdn2/files/selenium/stock1.html")
print(page.title())
page.locator('#kw').fill('通讯\n')
page.locator('#go').click()
# 打印所有搜索内容
lcs = page.locator(".result-item").all()
for lc in lcs:
print(lc.inner_text())
browser.close()5. wait_for_timeout 界面等待
不能在Playwright中使用 time.sleep 进行等待,可能产生异外结果.
因为Playwright底层使用的是异步的python库进行各种事件处理,time.sleep 会破坏异步框架的处理逻辑。
可以使用 Page 对象的 wait_for_timeout 方法达到等待效果,单位是 毫秒
page.wait_for_timeout(1000)6.自动化代码助手
命令行运行:
playwright codegen注意这个只能作为助手,它主要是记录人对页面的输入。
并不能取代人自己写代码,特别是那些 获取页面上信息 的代码
比如,这个打印标题栏,就没法自动化生成
print(page.title())7.tracing 跟踪功能
启用跟踪功能后, 可以在执行自动化后,通过记录的跟踪数据文件, 回看自动化过程中的每个细节
下面的的代码进行了自动化搜索股票,并打开跟踪功能,保存 跟踪数据文件 为 trace.zip。
from playwright.sync_api import sync_playwright
p = sync_playwright().start()
browser = p.chromium.launch(headless=False)
# 创建 BrowserContext对象
context = browser.new_context()
# 启动跟踪功能
context.tracing.start(snapshots=True, sources=True, screenshots=True)
page = context.new_page()
page.goto("https://www.baidu.com/")
# 搜找到对应元素后输入内容,
page.locator('#kw').fill('百度一下') #输入内容
page.locator('#kw').press('Enter') #按回车
page.wait_for_timeout(1000) # 等待1秒
# 结束跟踪
context.tracing.stop(path="trace.zip")
browser.close()
p.stop()执行完以后,我们发现,当前工作目录下面多了 trace.zip 这个跟踪数据文件。
怎么查看这个跟踪文件呢?有2种方法:
-
直接访问 trace.playwright.dev 这个网站,上传 跟踪文件
-
执行命令
playwright show-trace trace.zip
8.缺省等待时间
Playwright 中,当我们定位元素(比如 通过locator/get_by_text 等方法)后,
对元素进行操作(比如 click, fill),
如果当时根据定位条件,找不到这个元素, Playwright并不会立即抛出错误,
而是缺省等待元素时间为30秒,在30秒内如果元素出现了,就立即操作成功返回。
表示等待元素出现时长修改为10毫秒,再运行,就会有错误了
print(lc.inner_text(timeout=10 ))# 想修改 缺省 等待时间, 可以使用 BrowserContext 对象
from playwright.sync_api import sync_playwright
p = sync_playwright().start()
browser = p.chromium.launch(headless=False, slow_mo=50)
context = browser.new_context()
context.set_default_timeout(10) #修改缺省等待时间为10毫秒
page = context.new_page() # 通过context 创建Page对象
page.goto("https://www.byhy.net/cdn2/files/selenium/stock1.html")
page.locator('#kw').fill('通讯\n')
page.locator('#go').click()
element = page.locator("[id='1']")
print(element.inner_text())
# 可以发现缺省等待时间修改为10毫秒,后续操作等待时间无需单独指定,都是10毫秒了。slow_mo参数可以在启动浏览器时设置,其值以毫秒为单位,表示每次操作之间的延迟时间。例如,slow_mo=50表示每次操作之间会有0.05秒的延迟

















 1846
1846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









