



文章详解了视觉与多模态模型的区别,解析了卷积神经网络(CNN)的基础原理和结构,梳理了视觉模型架构的演变过程,从残差连接到Vision Transformer、Swin Transformer,再到多模态模型CLIP和VILT。指出视觉领域目前缺乏统一基座模型,未来视觉基座模型的问世将重塑众多下游应用并大幅降低成本。
首先我们需要区分视觉模型和多模态模型。如果模型的输入和输出都仅限于图像,那么它属于单模态,而非多模态。只有当输入包含多种媒体形式的数据(如图像+文本),或者输出是多种形式(文本/图像/文本+图像),才属于多模态。简而言之,大模型在输入或输出环节涉及多种类型的数据,即可称为多模态。接下来,我将从单模态视觉任务的分析入手,逐步过渡到多模态任务进行说明。
常见的视觉任务主要包括:图像分类、目标检测、图像分割、人脸识别、姿态识别、视觉问答(VQA)和视觉生成等,如下图所示。值得注意的是,迄今为止,处理这些视觉识别任务通常需要不同的专用模型。这与自然语言处理(NLP)领域(如GPT、DeepSeek、千问等模型)的做法形成鲜明对比。在NLP领域,通常存在一个基座模型,针对不同任务只需关注应用层的适配即可。然而,在视觉模型领域,往往需要为特定任务开发或选用专门的模型结构。

视觉任务都会用到CNN卷积神经网络,常用于做计算机视觉任务。
1.卷积核
要理解卷积神经网络(CNN),首先需要明确什么是卷积核。本质卷积核是一个带有权重的矩阵,用于通过滑动窗口与输入数据局部区域进行点积运算以提取特征。
卷积核的计算规则:
- 假设需要计算输出图像上绿色像素的值(如图‘卷积核计算’所示,位于第二行第三列)。
- 根据位置对应关系,找到原图中相同位置(第二行第三列)的像素。
- 以该像素为中心,在原图上选取一个与卷积核尺寸相同的区域(例如,图中卷积核为3x3,则选取一个3x3的像素区域)。
- 将卷积核(一个n x n的矩阵,n的大小决定了处理的感受野大小)覆盖在选取的像素区域上。
- 进行逐元素相乘:将卷积核矩阵中的每个权重值,与覆盖的原图区域中对应位置的像素值相乘。然后将所有相乘的结果累加求和。
- 这个累加和就是输出图像上对应位置(绿色像素)的值(如图中计算结果为0)。
滑动计算: 通过让这个以目标像素为中心的“窗口”(感受野)在整个原图上滑动,并对每个位置重复上述计算,最终就能生成完整的输出图像(特征图)。在上述例子中,该卷积核起到了边缘提取的作用。
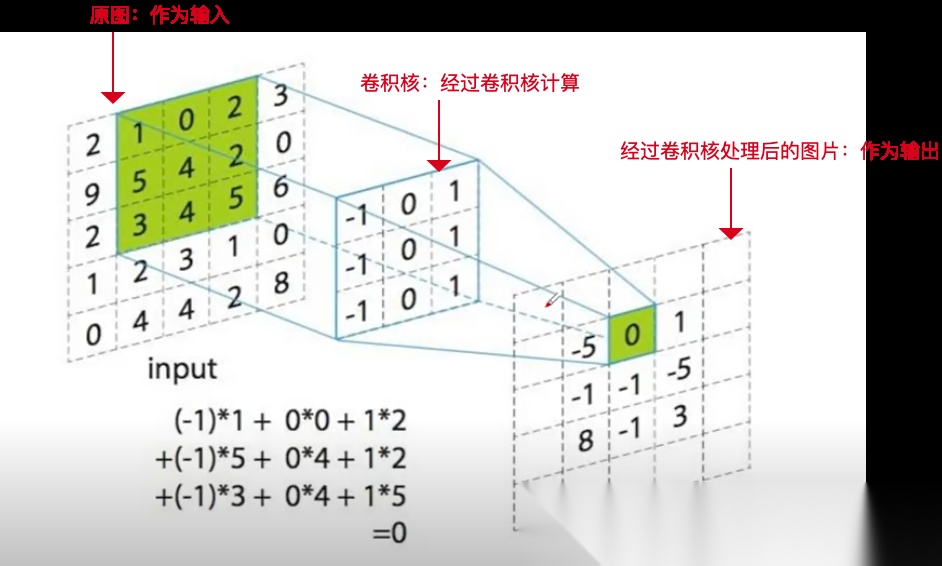
若将卷积核替换为下图所示的3x3矩阵,此时该卷积核实现的是图像模糊效果。
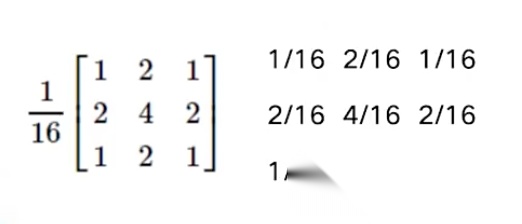
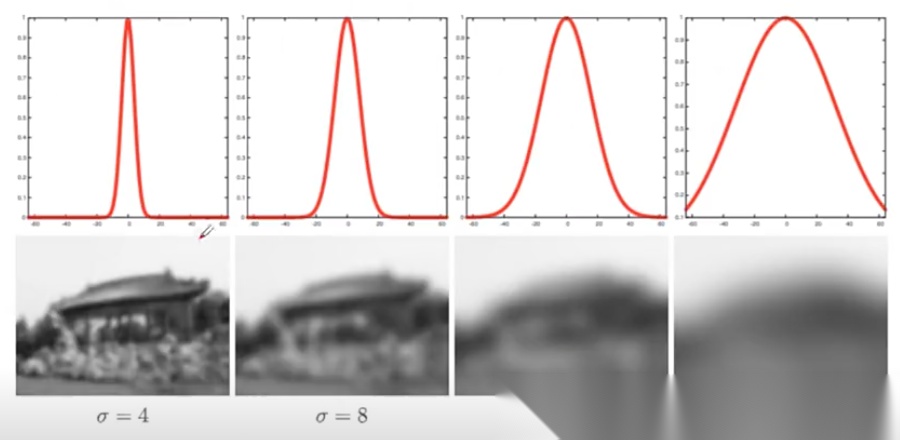
以上仅是两个示例。实际应用中存在种类繁多的卷积核,其权重值(矩阵元素)不同,即代表不同的卷积核,功能也可能各异(例如用于图像美白、祛痘等处理)。
当构建模型执行具体任务时,卷积核的权重值并非预先设定。以3x3卷积核为例,其初始权重值通常是随机生成的。通过卷积神经网络的训练过程,模型会根据任务目标自动学习并确定这些权重的最佳值。
卷积核的核心作用在于特征提取。不同的卷积核能够提取图像中不同类型的特征,例如边缘特征或身体关节点特征。在处理不同视觉任务时,具体应使用何种卷积核(其权重矩阵)是未知的。卷积核中的每个权重值,本质上是神经网络中需要通过学习确定的参数。
卷积核在图像上滑动计算时,每一次操作都是对图像中一个局部感受野进行特征提取。当整个图像被一个卷积核处理完毕后,生成的新矩阵称为特征图(其作用类似于LLM中的向量)。若对同一张图像同时使用多个不同的卷积核(即多个“头”),便可得到多组特征图。这种设计思路,与我在《大白话分析Transformer架构》一文中阐述的“多头自注意力机制”有相似之处,二者都旨在从不同视角(或维度)提取信息。自注意力机制提取语义信息,而多卷积核则提取图像的不同特征。
尽管视觉领域的“多头”(多卷积核)与语言处理中的“多头自注意力机制”在概念上存在相似性(即并行多角度处理),但两者有一个关键区别:空间尺度的概念。空间尺度(如感受野大小、局部区域)在视觉任务中至关重要,而在语言/文字处理领域则不存在这种空间尺度的概念。

即使使用相同尺寸的卷积核,在不同尺寸的图像上提取的特征也可能不同。这本质上是因为其感受野所覆盖的图像相对范围发生了改变。重要的是,模型需要保留并融合来自不同尺度(图像尺寸)的特征信息。例如在飞机识别任务中:当飞机距离较近(图像尺寸大/分辨率高)时,模型应能识别具体机型细节。当飞机距离较远(图像尺寸小/分辨率低)时,模型同样需要能够识别其机型类别。
2.卷积神经网络最常见的结构:
模型与 AI 归根结底围绕三个核心概念:向量、空间、特征。万物皆可表示为向量,而向量的唯一目的就是提取特征,卷积核也不例外。向量的维度即所在空间的坐标。在 AI 里,我们永远用一套数学公式把向量从当前空间映射到另一空间,CNN 亦然。接下来,我们剖析 CNN 识别数字的全过程:
背景:如下图所示,这张数字“2”的图片是一个28×28像素的单通道图像(末尾的1表示单通道),现在要识别图片上的数字是几。
1)卷积核计算:
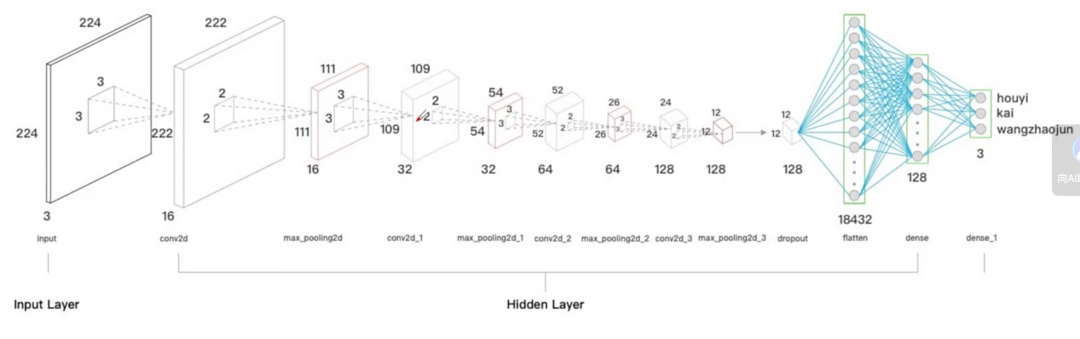
卷积核就是微观特征提取器。如图,原图是224×224 的三通道彩色图(红、绿、蓝各一通道,数值 0-255),经卷积核逐像素滑动后,得到 16 张 222×222 的特征图,每个数值对应原图某小区域的某类特征;也可视作 16 个通道,即 16 张图或 16 维特征点,本质相同。
2)池化(pooling):
什么是池化,缩小特征图,增加感受野,便于提取结构特征。图片上还写了个2*2池化,2*2池化就是比如2*2像素图片,我现在相比这个图片变成1*1像素图片,也就是说2*2原本有4个数值,我现在用1个数值去标识这4个数值,相当于把图片变小了一倍。如 222×222像素被压成111×111特征图。
最大化池化(Max pooling)又是什么意思呢?比如2*2像素,我想用1*1像素标识,4个值我现在用一个值表示,我取四个中值最大的一个代表这四个像素值。
3)重复卷积、池化:
通常卷积与池化至少各做两次。再次卷积后,图像变成32 张 109×109 的特征图;卷积、池化后再卷积,通道数翻倍,由 16 张增至 32 张。池化层数越多,提取的特征越丰富,信息量增加,就需要更高维的向量来承载。如图,最终得到 128 张 12×12 的特征图,将其展平成 18 432 维向量,作为原图的表示输入后续神经网络。
4)神经网络
18432个向量是神经网络的输入,神经网络的输出就应该是三个类型值的概率。这个神经网络就相当于我们transformer模型中的linear和softmax阶段。这里和语言模型不同的是,我们要知道这里的可训练参数都在卷积核里。
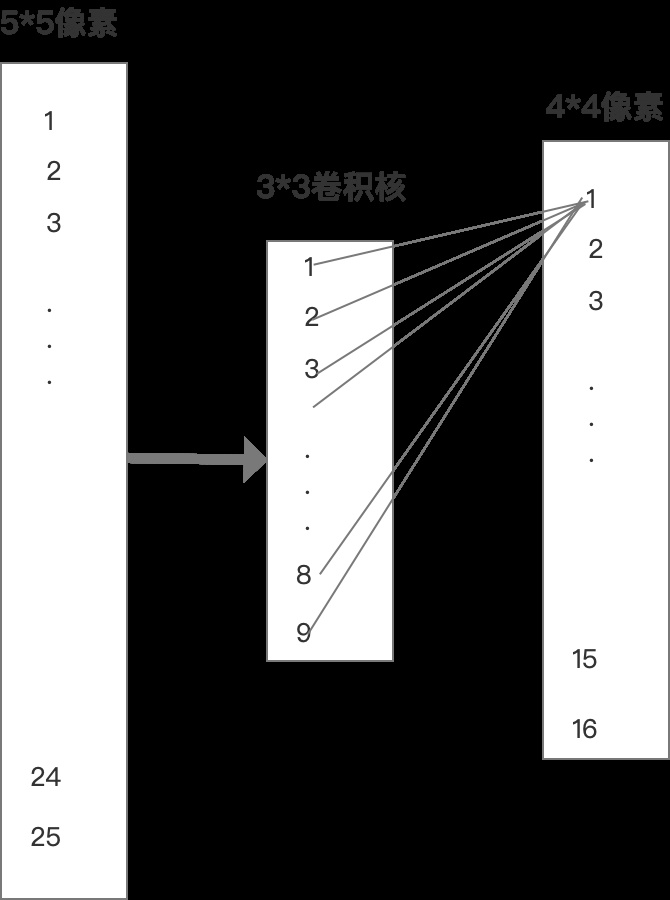
CNN卷积神经网络就是特殊一点的神经网络。比如把 5×5 图像用 3×3 核卷积,输出 4×4 即 16 个值;25 个输入只与 9 个神经元相连,而传统全连接需 25×16 个神经元连接。为什么CNN卷积神经网络要这么做,因为在计算机视觉领域,处理某个区域,其他离得比较远的区域,因为相关度比较低,所以就没必要做连接。
3.处理图片模型架构的演变过程:
1)残差链接(Residual Connection):
2015 年,Google 团队提出残差连接,核心目的正是缓解梯度爆炸与梯度消失。在 NLP 领域,GPT-3.0 已堆到 96 层;CNN 同样热衷于加深网络。层数越多,提取到的特征就越抽象、越“深”。举例而言,判断一张图片里有没有人,几层卷积也许就够;但要识别里面是否有机器人,难度骤增——可能需要分辨特定材质。再进一步,若想区分谁是“变形金刚”,任务愈发复杂,浅层特征已远远不够,必须依赖更深层的表达,于是网络只能继续加层。
然而,层数一旦过深,效果往往不升反降。原因何在?网络越深,训练越难:反向传播逐层求梯度,维度膨胀后,方向信息在后几层可能完全失真。
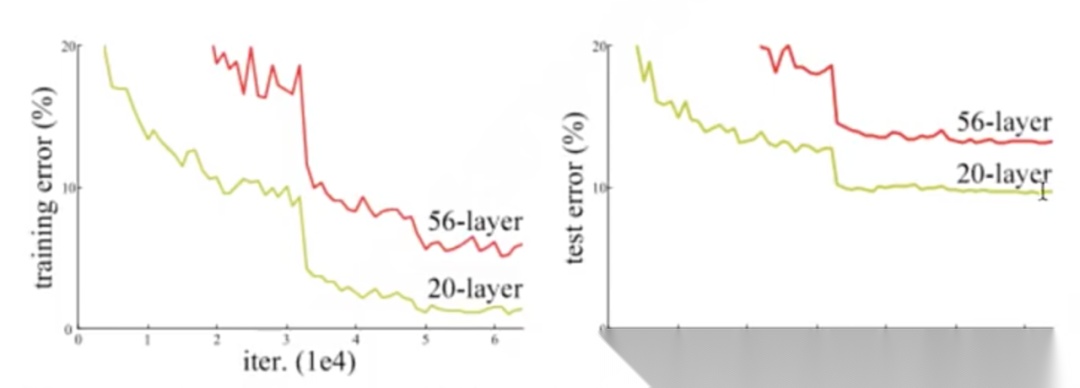
当网络层数被无限叠加时,过拟合同样可能悄然而至。所有大模型的训练本质上都是在寻找输入与输出之间的映射:给定一组输入,究竟用怎样的运算才能得到合理的输出。层数越多,模型的拟合能力就越强,能够捕捉到更细粒度的特征;然而,如果训练集规模并未同步扩大(例如始终只有一万张图片),你的拟合能力过强就会记住过多噪声,从而干扰最终判断。
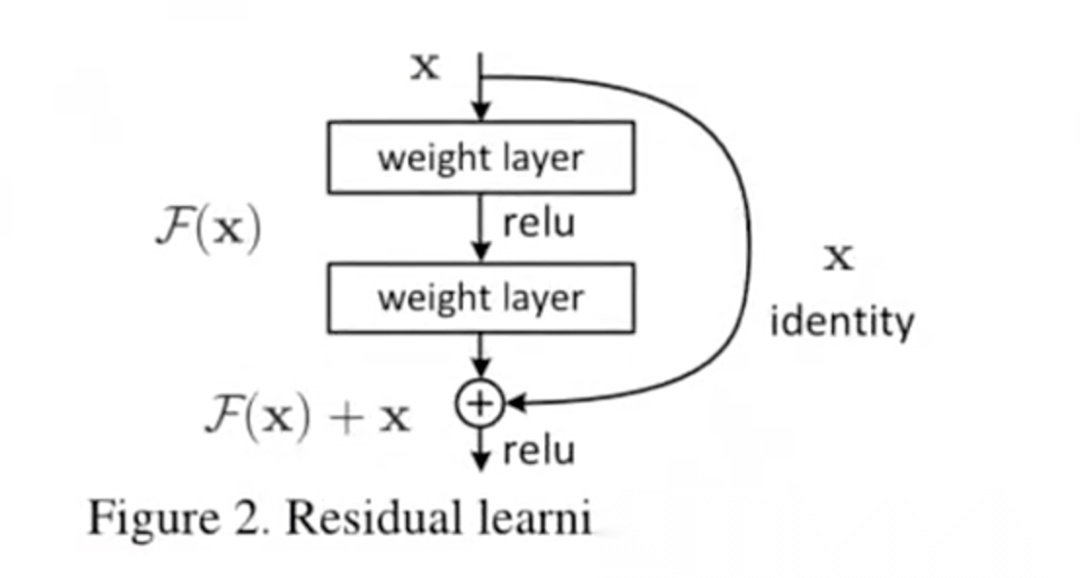
正因如此,“残差(Residual)连接”应运而生:若当前层的输入为 x,输出为 f(x),则下一层的输入改为 x + f(x),把原始输入 x 一并带进去,再次作为输入参与后续运算就不用担心信息失真了。
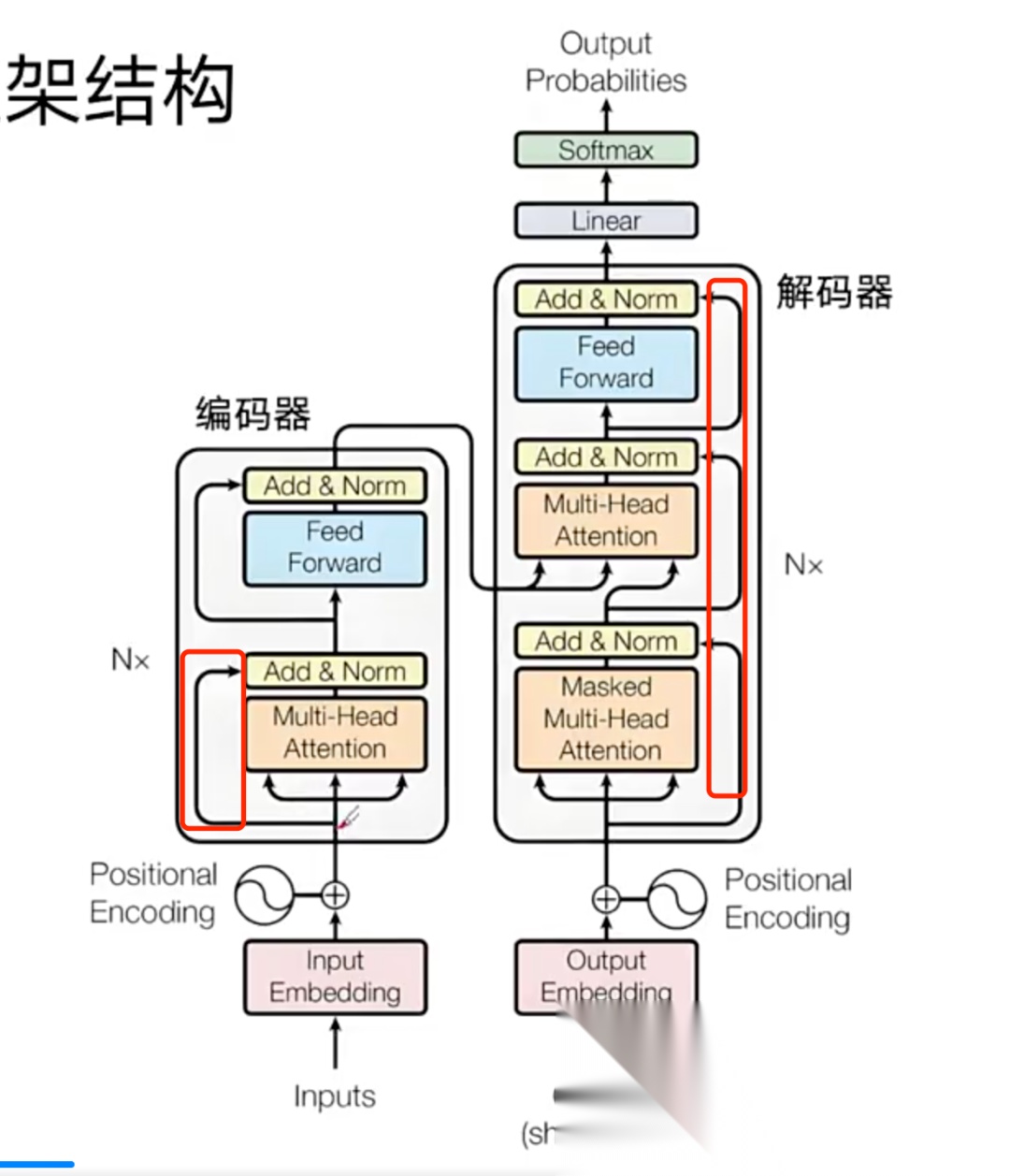
在Transformer 架构示意图中,被红框标注的那几条路径就是残差连接;图中的 “Norm” 指归一化的意思。具体流程是:将多头注意力机制的输入与输出执行残差相加(add),随后做一次归一化(Norm),再把结果送入前馈网络(Feed Forward)。
残差连接通过引入跨层信息传递机制,既能有效缓解深度神经网络训练中的梯度消失,又能同步提升模型性能与训练效率。
2)VIT(Vision Transformer)-视觉版的transformer:
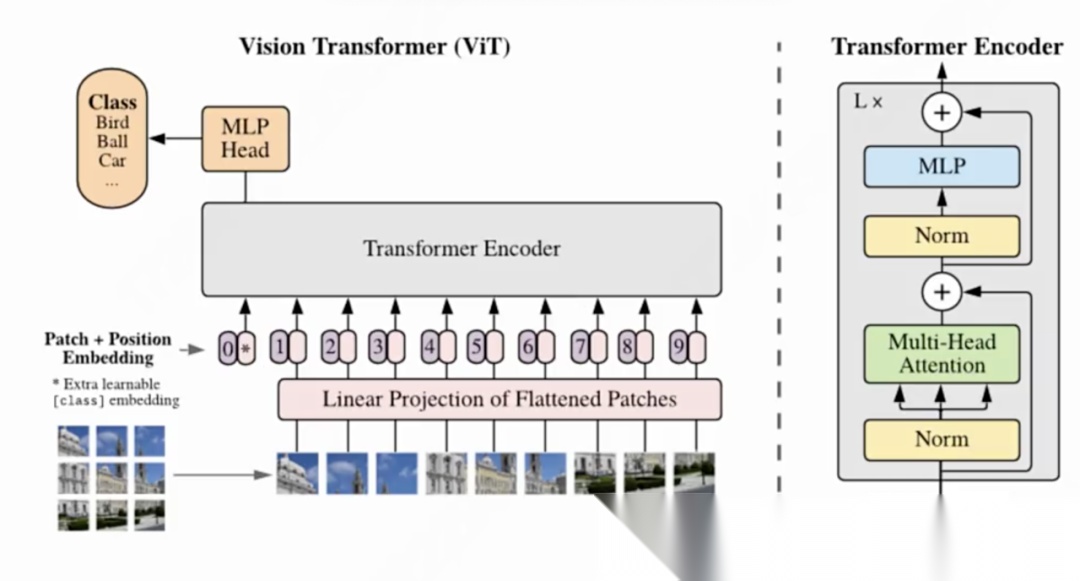
2020 年,Google 团队提出 Vision Transformer(ViT)。其核心思路是:能否彻底舍弃 CNN?既然 Transformer 已在 NLP 中取代 RNN,而 Transformer 只接受“序列化的数字”,也就是把一句话拆成若干 token,再把每个 token 映射成向量,那么只要将图片也拆成序列,并把序列元素转成向量,Transformer 就能直接处理。
具体做法是:把图像切成16×16 或 32×32 像素的小方块,然后将这些小方格拉平,每个小方格这里叫一个patche(类似于语言模型中的token)。如图,每个 patch 先经过 Linear 层(相当于 NLP 中的 token embedding),例如 9 个 patch 便得到 9 个向量;还有第 0 个向量是抽取向量(把被切分后的局部图像块统一映射为固定长度的向量序列)。随后加入位置编码(position embedding),再送入 Transformer Encoder,执行多头注意力等运算,最终输出 10 个向量(包括了第0个向量处理后的向量)。对这 10 个向量再做线性变换,即可得到分类结果(鸟、飞机、汽车……)。
ViT 的验证目标是:证明 Transformer 可以替代 CNN。如果成功,未来就能用同一个大模型实现真正的多模态,实现无论输入是图片还是文字,皆可统一处理。
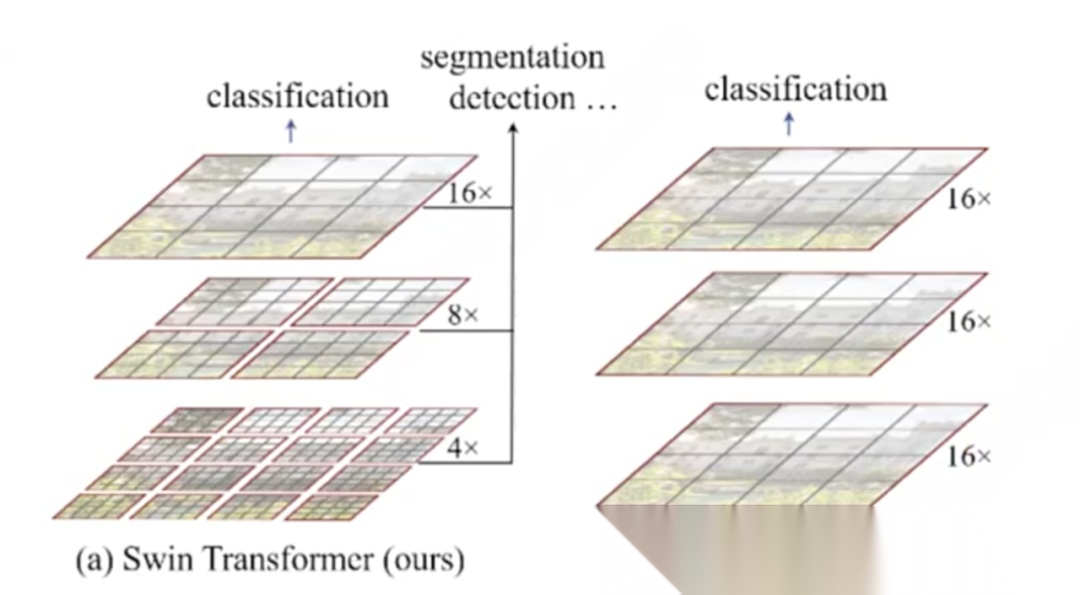
3)Swin Transformer:
2021年,微软团队提出Swin Transformer,是基于Vision Transformer(ViT)的改进框架。ViT仅支持图像分类,无法处理图像分割、目标检测等复杂任务;而Swin Transformer兼具基础分类与高级任务(分割/检测/人脸识别)能力。
ViT 把图像切分成固定数量的 patch,之后 patch 的个数不再变化,再在这些 patch 之间做全局多头自注意力。Swin Transformer 对 ViT 的改动在于:自注意力不再全局计算,而是仅在局部窗口内进行。具体做法是,先在图像上画出许多小红格,每个格子包含若干 patch;注意力只在同一红格内的 patch 之间执行。
此外,ViT 的每一层都沿用语言模型原生的 Transformer,而语言模型并不考虑“尺度”。视觉任务却对尺度敏感。因此 Swin 采用逐层扩大感受野的策略:
• 第一层只在最小窗口内做多头自注意力;
• 第二层窗口变大,但 patch 数量与第一层相同,仍在窗口内部做注意力;
• 第三层进一步合并为单一窗口,仍保持 patch 数不变,在该窗口内完成全局多头自注意力。
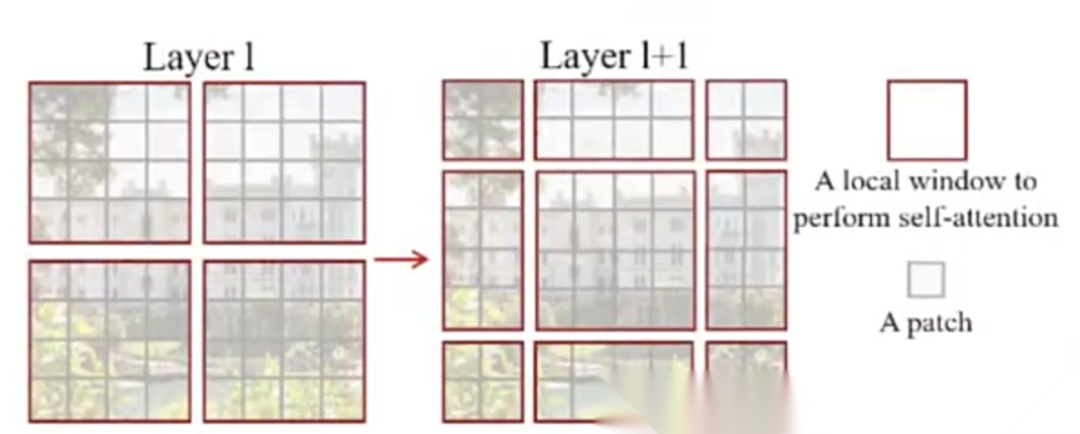
Swin Transformer 还有一个巧妙设计:先在 Layer1 的各红框内分别做自注意力,再在 Layer1+1 的各红框内分别做自注意力,两步完成后才算完整的一层计算。这样一来,像素点会随着窗口移动,与周围不同位置的像素依次做自注意力,例如第一阶段胸部与头、肩部交互,第二阶段胸部又与腹部交互,虽然未做全局注意力,却把所有可能相关的局部关系都遍历了一次。
4)CLIP模型(Contrastive Language-Image Pre-training):
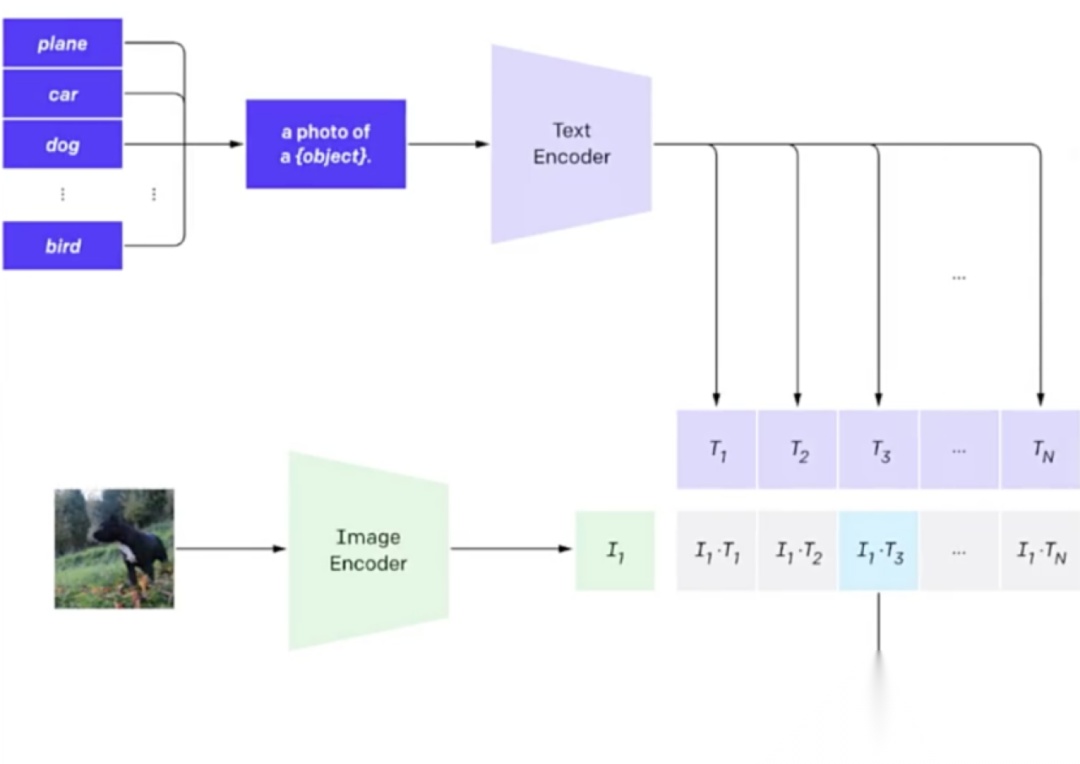
2021 年提出的 CLIP 首次把人类语言与视觉统一在同一框架内。模型内部包含两个编码器:Text Encoder(即 Transformer 编码器)接收一段文字,输出文字向量;Image Encoder(即 ViT)接收一张图片,输出图像向量。
训练数据通过多源渠道收集了4 亿余组图文对,文本即对图片的简短描述。训练采用对比学习:先把每对图文分别送入各自编码器,得到成对向量。我们希望,当一段文字与其对应图片计算相似度(向量点积,也就是相似度计算)时,该值应显著高于文字与其他任意图片、或图片与其他任意文字的点积结果。经过多轮优化,模型最终实现了这一目标。
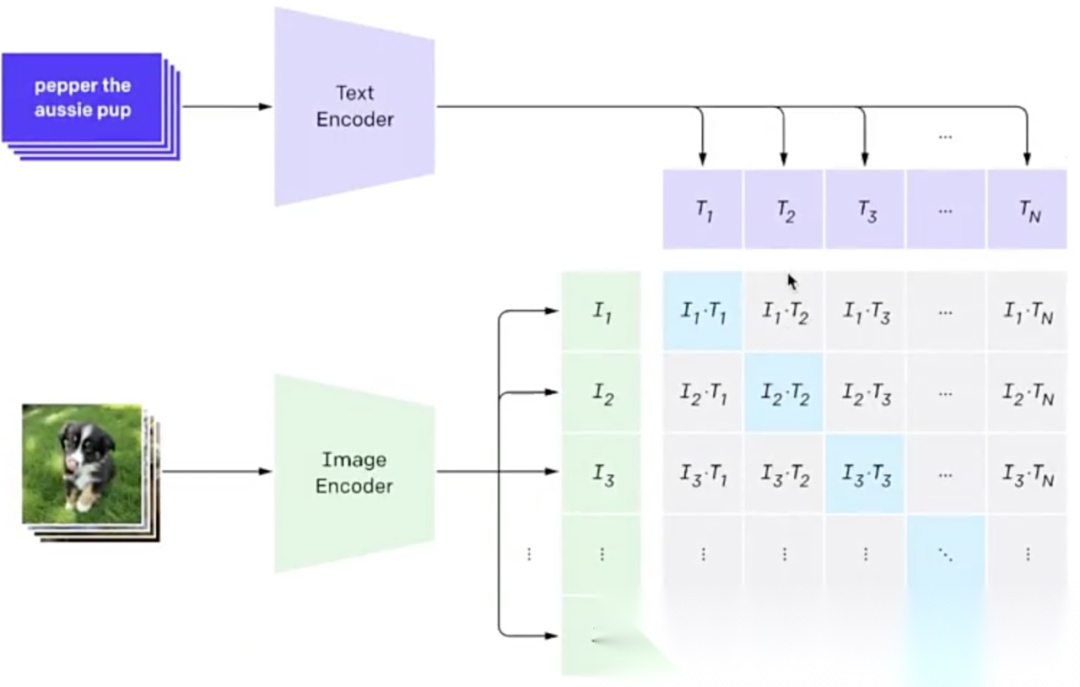
训练完成的CLIP 会留下两个编码器:一段文字先经提示词(prompt)模板补全,如把 dog 改写成 “a photo of a dog”,再送入文本编码器得到向量;图片则直接送入图像编码器得到向量。面对“这是什么图片?”的提问,只需计算图文向量的相似度,得分最高的自然语言描述即为答案。借助这一提示工程,CLIP 真正实现了文本与图像打通的效果,后续所有文生图、文生视频系统几乎都以它作为基石。
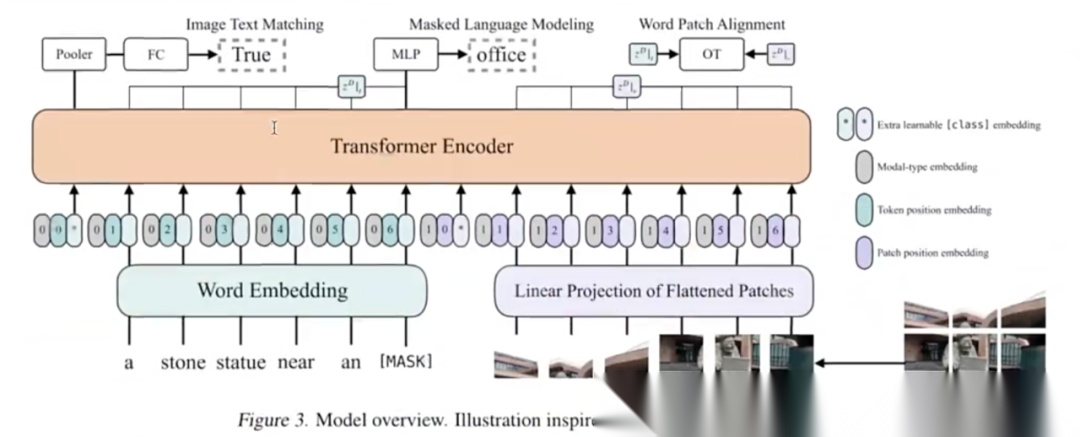
5)VILT(Vision-and-Language Transformer):
VILT 同样诞生于 2021 年,与CLIP需两个独立编码器(图像Encoder + 文本Encoder)有所不同,它仅用一套 Transformer Encoder,就能把文字和图片各自编码成向量,并直接判断二者是否描述同一件事。
时至今日,视觉领域仍缺乏统一、公认的基座模型,各类视觉任务所用的网络架构差异巨大。一旦视觉基座模型问世,其影响将与语言领域 GPT 的出现相媲美:众多下游应用将被重塑,而最关键的变化在于成本的大幅降低。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









