



一、引言
AI的快速发展推动了各行各业的智能化转型和创新,随之而来的是对AI应用的迫切需求。
如何微调大模型、高效搭建AI应用成为了开发者们广泛关注的技术方向。阿里云人工智能平台PAI,联合开源低代码大模型微调框架LLaMA Factory ,共同打造多模态大模型微调训练最佳实践,通过微调 Qwen2-VL 模型,快速搭建文旅领域知识问答机器人,带您开启AI创新与应用之旅,点击阅读原文可马上体验~
二、详细实验步骤
1、环境准备和资源准备
为了顺利开发文旅领域知识问答机器人,首先需要准备好运行环境,包括开通阿里云交互式建模PAI-DSW服务并创建实例。
1.1领取PAI-DSW免费试用权益
前往文末“阅读原文”中的阿里云活动页面,领取PAI-DSW产品的免费试用资源包。新用户可免费获得试用资源,用于启动和运行实例,具体试用权益和试用规则请参考领取页面。老用户可创建按量付费实例,按小时计费,约6-30元/小时。
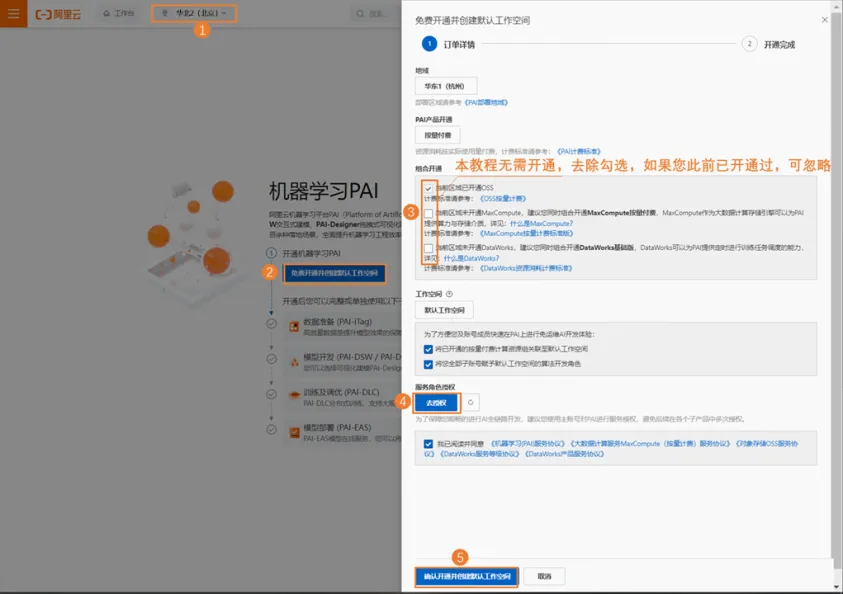
1.2开通机器学习PAI并创建默认工作空间
前往PAI控制台,其中关键参数配置如下:
-
本教程地域选择:华北2(北京)。您也可以根据情况选择华东1(杭州)、华东2(上海)、华南1(深圳)地域。
-
组合开通:本教程无需使用其他产品,去除勾选MaxCompute和DataWorks产品。
-
服务角色授权:单击去授权,完成服务角色授权。
说明:更多详细内容,请参见开通并创建默认工作空间。
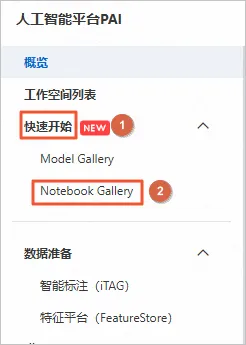
1.3 进入PAI NotebookGallery
登录PAI控制台。
在左侧导航栏中,选择快速开始>NotebookGallery。
在Notebook Gallery页面,单击进入“LLaMA Factory多模态微调实践:微调Qwen2-VL构建文旅大模型”教程。
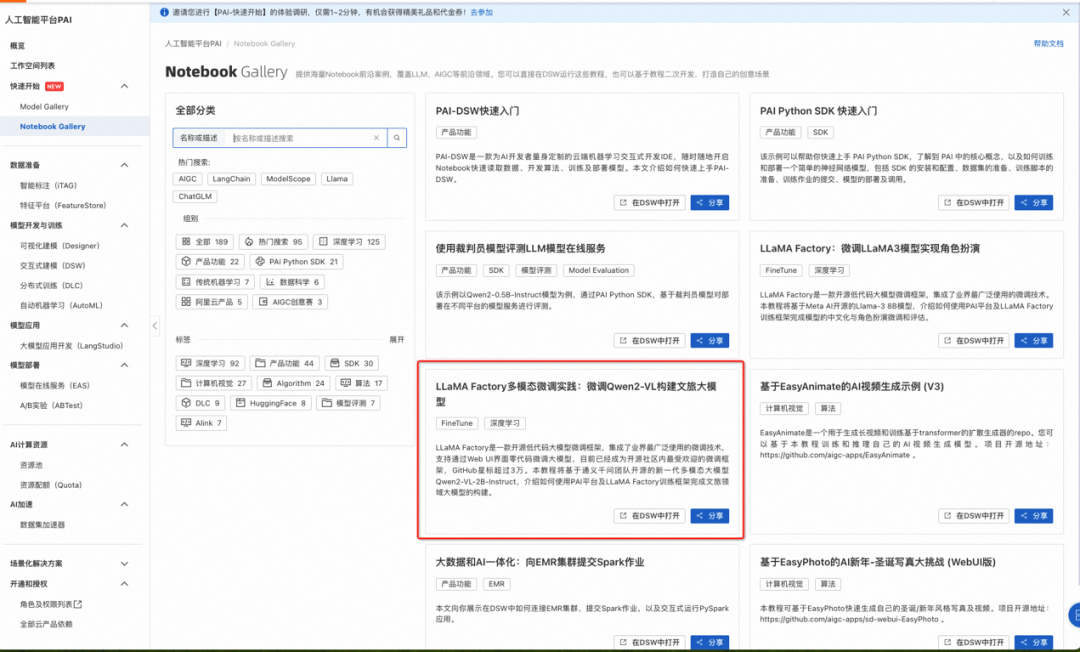
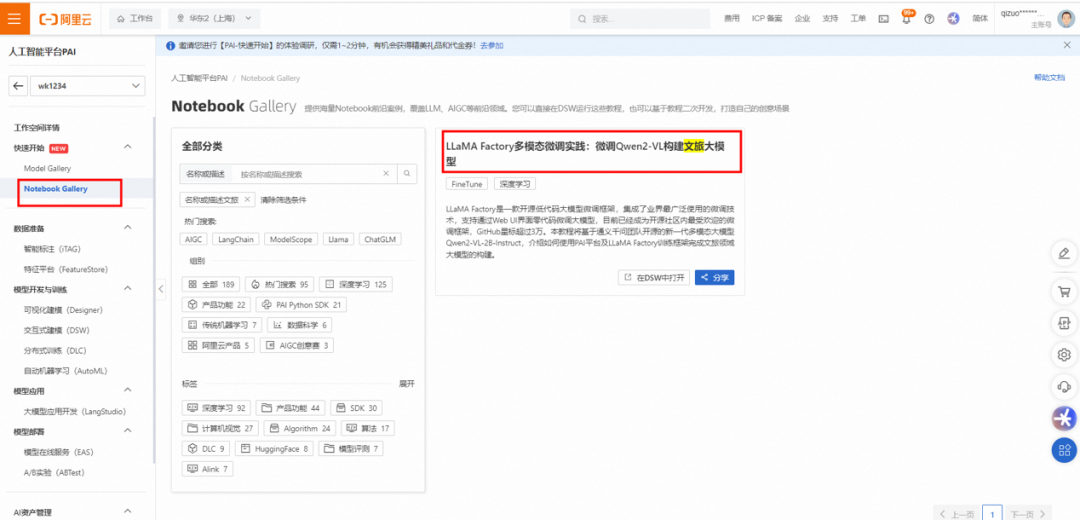
在详情页面,您可查看到预置的LLaMA Factory多模态微调实践:微调Qwen2-VL构建文旅大模型教程,单击右上角的在DSW中打开。
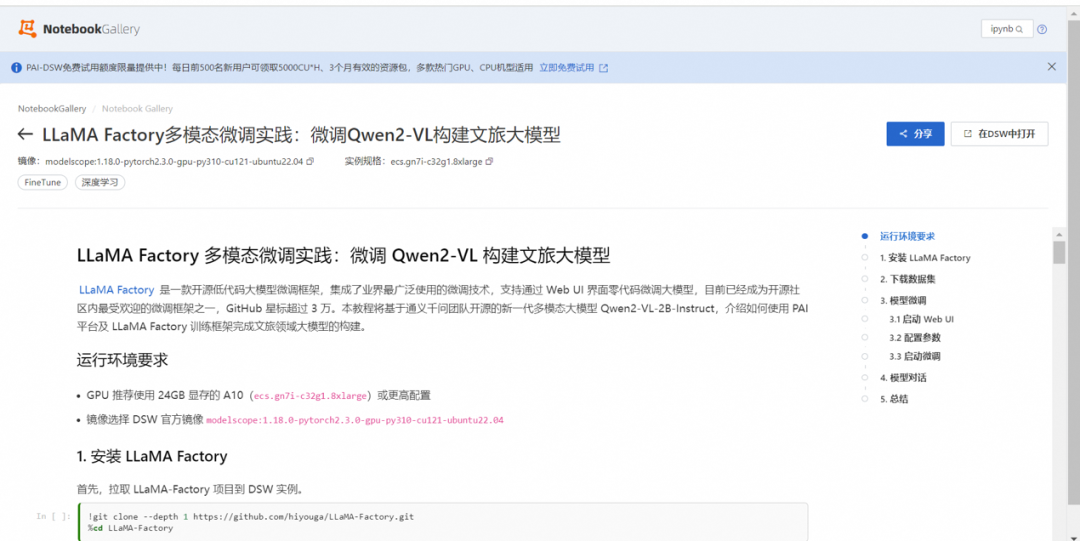
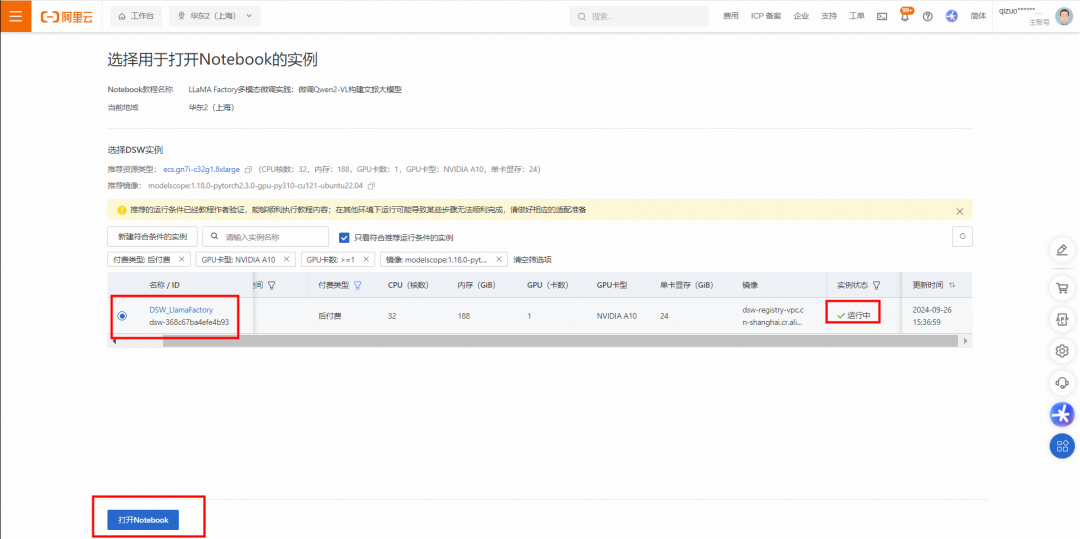
在请选择对应实例对话框中,单击新建DSW实例。
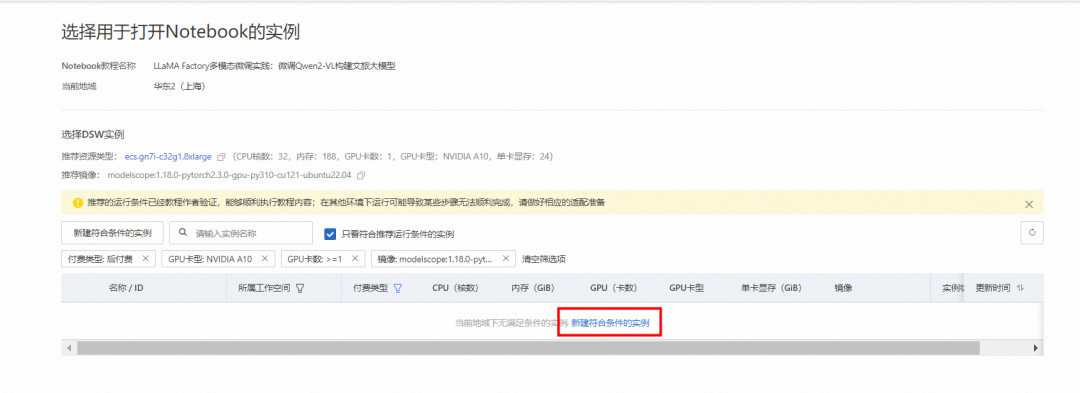
1.4 创建PAI-DSW实例
在配置实例页面,自定义输入实例名称,例如DSW_LlamaFactory。
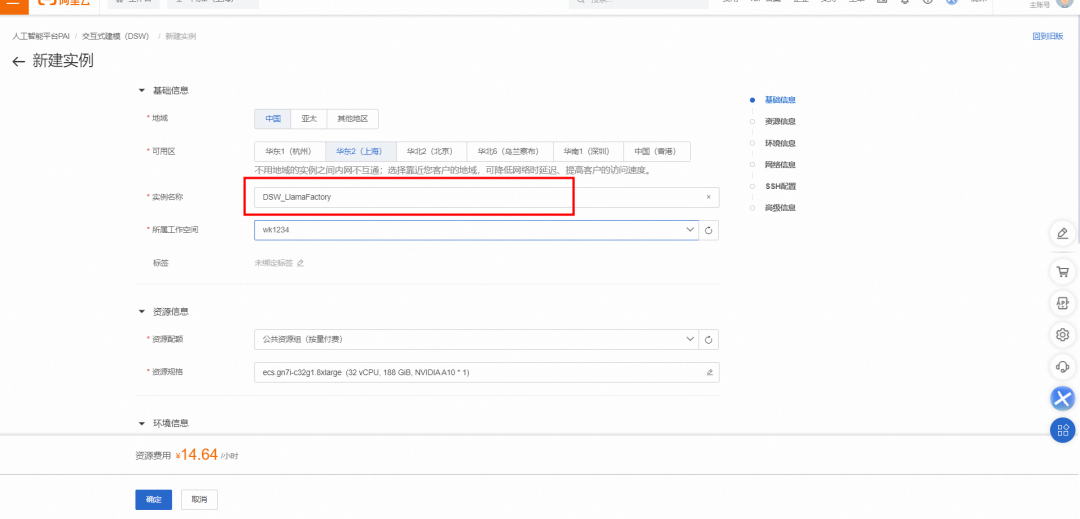
说明:
-
若您是 PAI 产品新用户,请再次确认是否已领取免费使用权益,点击领取。若您未领取免费试用权益,或不符合免费试用条件,或历史已领取且免费试用额度用尽或到期,完成本实验将产生扣费,大约为6-30元/小时。
-
请在实验完成后,参考最后一章节清理及后续,停止/删除实例,以免产生不必要的扣费或资源消耗。
GPU推荐使用 24GB 显存的 A10(ecs.gn7i-c8g1.2xlarge)或更高配置。
※ 支持免费试用的资源:
ecs.gn7i-c8g1.2xlarge、ecs.gn6v-c8g1.2xlarge、ecs.g6.xlarge
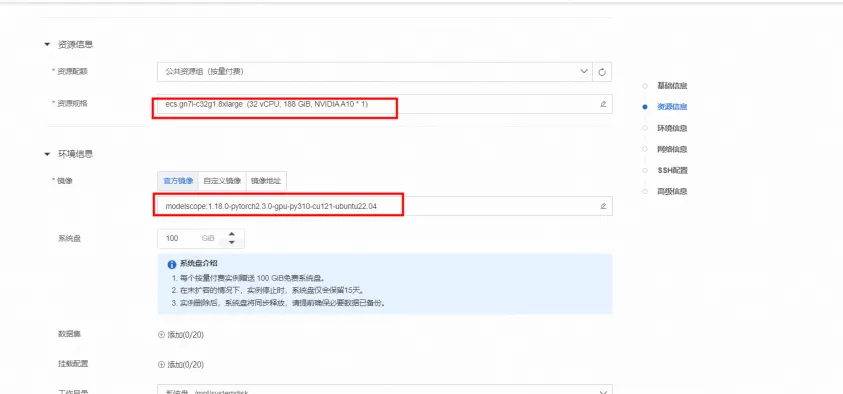
在配置实例页面的选择镜像区域,请确认镜像是否为官方镜像的modelscope:1.14.0-pytorch2.1.2-gpu-py310-cu121-ubuntu22.04。
在配置实例页面,未提及的参数保持默认即可,单击确认,创建实例。
请您耐心等待大约3分钟左右,当状态变为运行中时,表示实例创建成功,点击打开NoteBook。
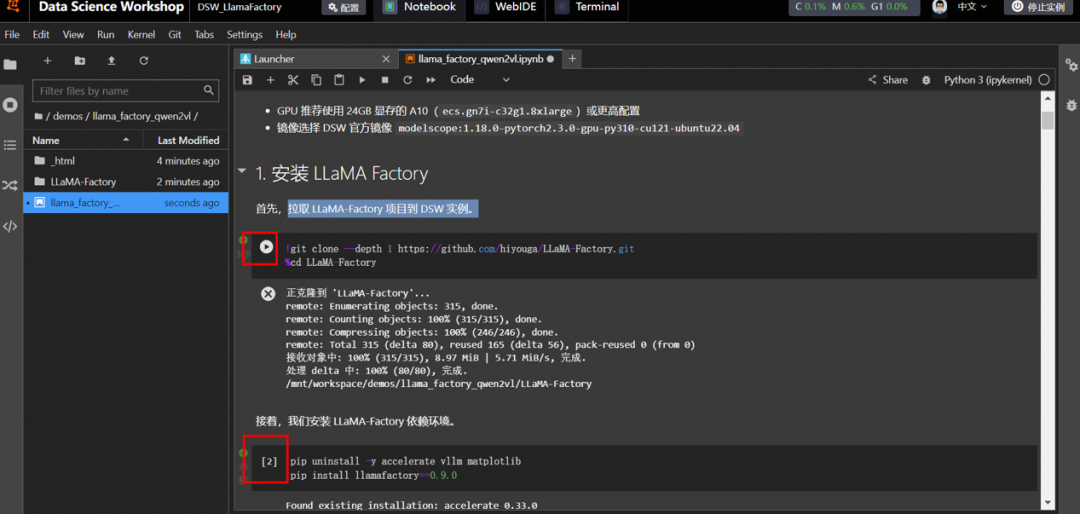
1.5 运行Notebook教程文件
安装LLaMA Factory
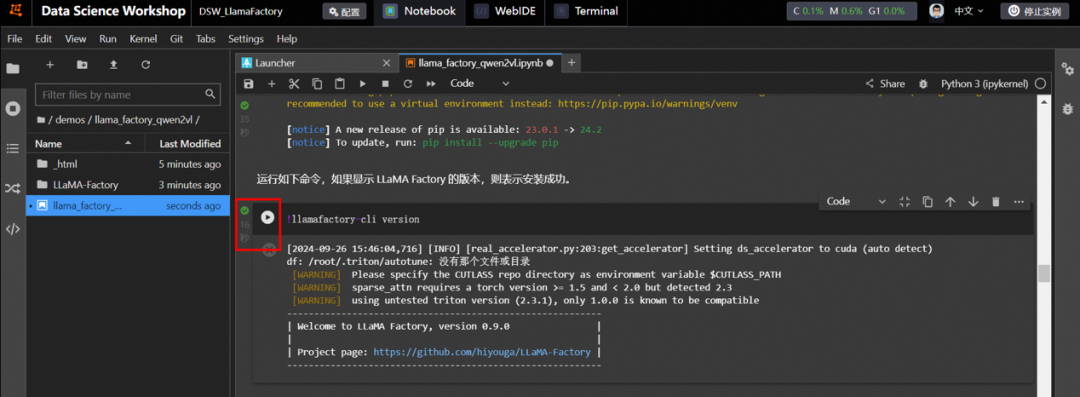
根据教程指引,依次运行命令。
说明:单击命令左侧的运行▶按钮表示开始运行任务,当左侧为✅号时表明成功运行结束。
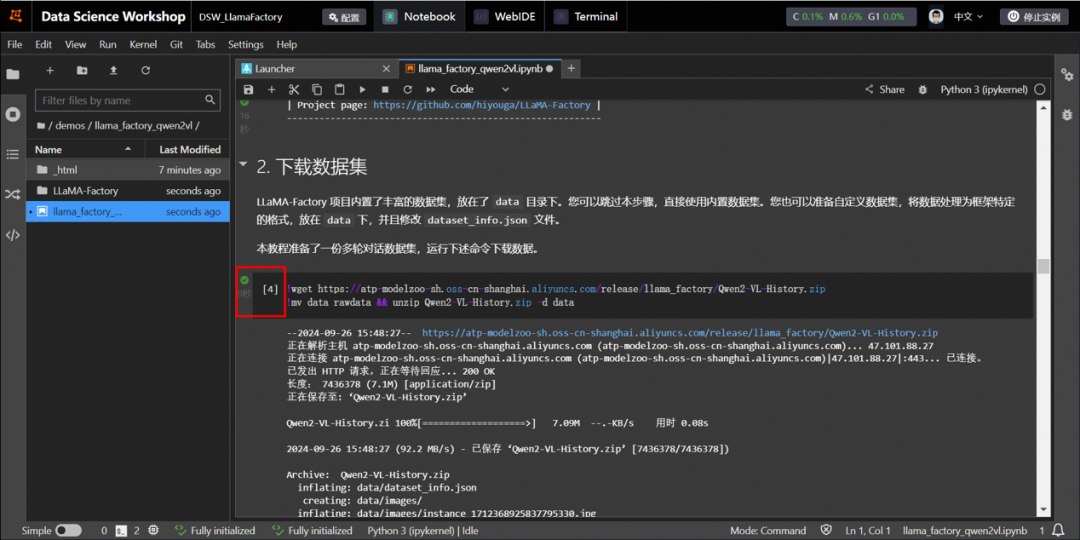
下载数据集
LLaMA-Factory 项目内置了丰富的数据集,放在了 data目录下。您可以跳过本步骤,直接使用内置数据集。您也可以准备自定义数据集,将数据处理为框架特定的格式,放在 data 下,并且修改 dataset_info.json 文件。
本教程准备了一份多轮对话数据集,运行下述命令下载数据。
说明:单击命令左侧的运行▶按钮表示开始运行任务,当左侧为✅号时表明成功运行结束。
2. 模型微调
2.1 启动 Web UI
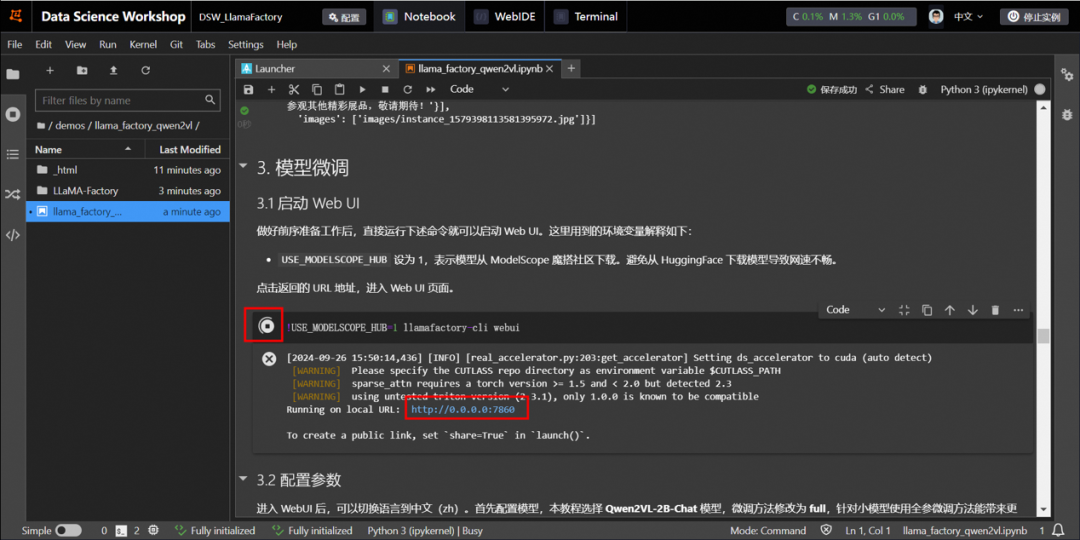
单击命令左侧的运行▶按钮表示开始运行任务,当左侧为✅号时表明成功运行结束。
然后单击返回的URL地址,进入Web UI页面。
2.2 配置参数
进入 WebUI 后,可以切换语言到中文(zh)。首先配置模型,本教程选择 Qwen2VL-2B-Chat 模型,微调方法修改为 full,针对小模型使用全参微调方法能带来更好的效果。

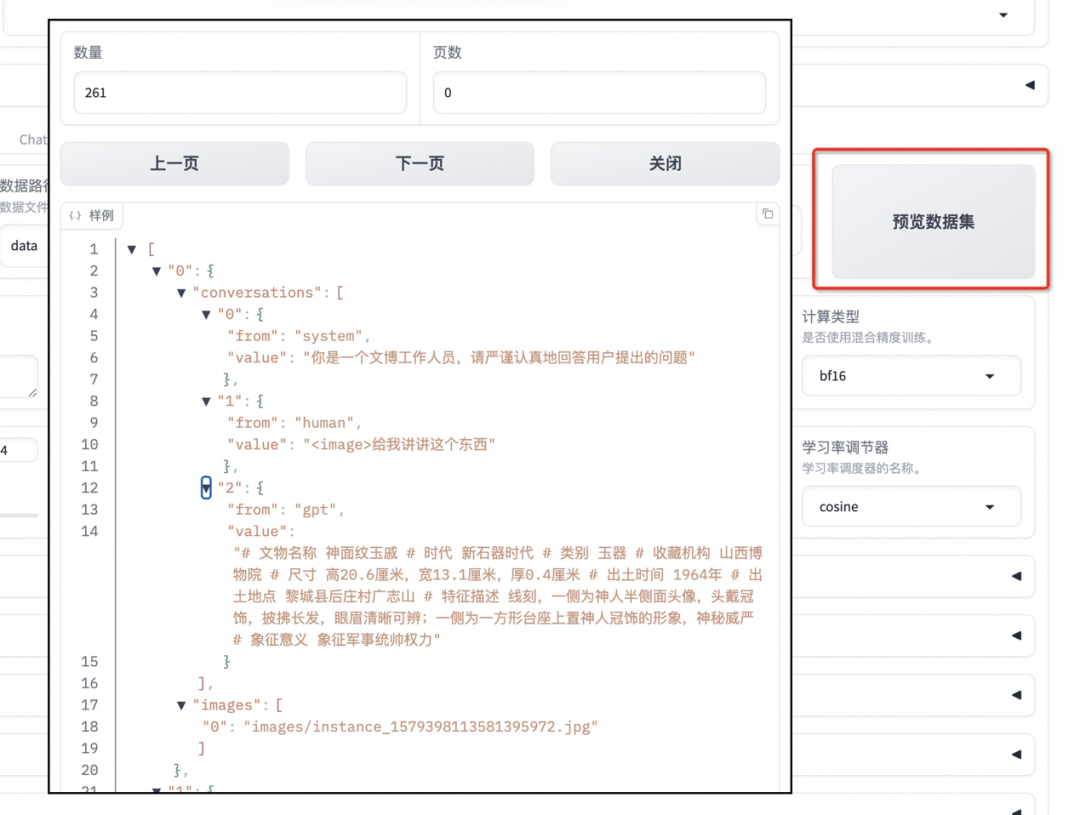
数据集使用上述下载的 train.json。

可以点击「预览数据集」。点击关闭返回训练界面。
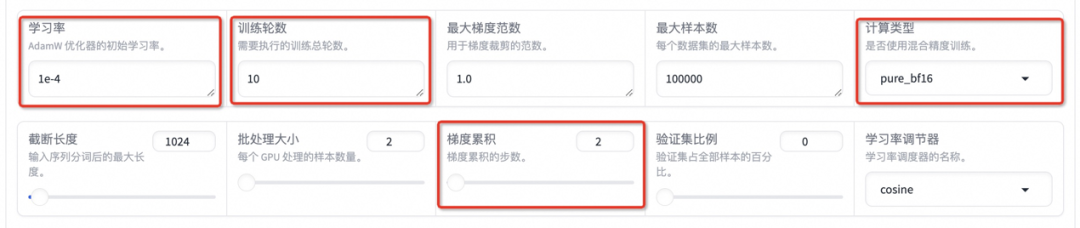
设置学习率为 1e-4,训练轮数为 10,更改计算类型为 pure_bf16,梯度累积为 2,有利于模型拟合。
在其他参数设置区域修改保存间隔为 1000,节省硬盘空间。

2.3 启动微调
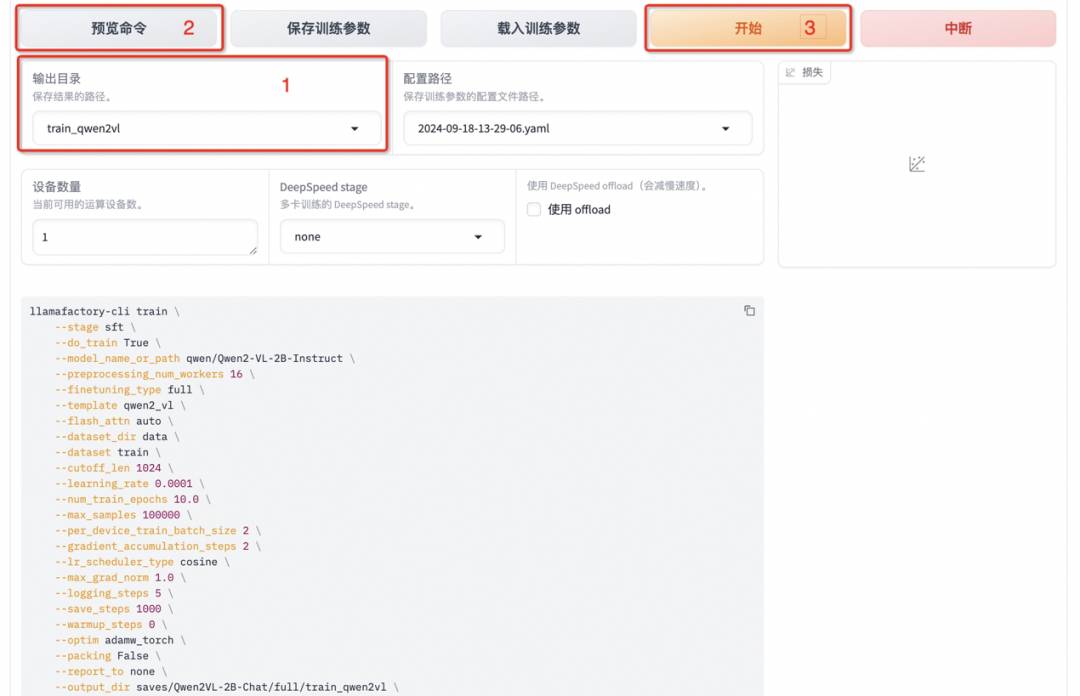
将输出目录修改为 train_qwen2vl,训练后的模型权重将会保存在此目录中。点击「预览命令」可展示所有已配置的参数,您如果想通过代码运行微调,可以复制这段命令,在命令行运行。
点击「开始」启动模型微调。
启动微调后需要等待一段时间,待模型下载完毕后可在界面观察到训练进度和损失曲线。模型微调大约需要 14 分钟,显示“训练完毕”代表微调成功。
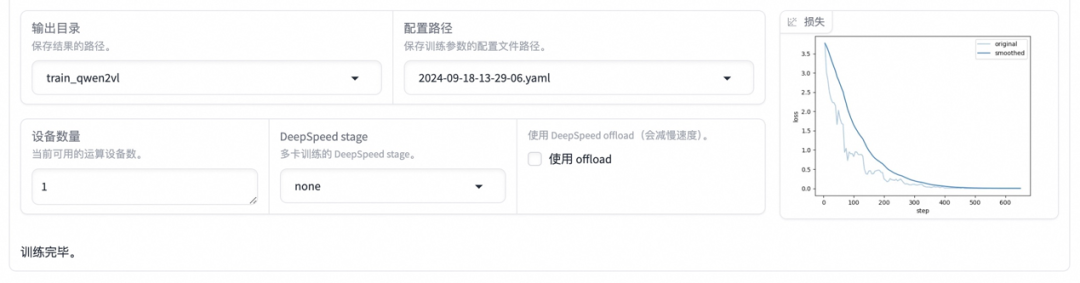
3. 模型对话
选择「Chat」栏,将检查点路径改为 train_qwen2vl,点击「加载模型」即可在 Web UI 中和微调后的模型进行对话。
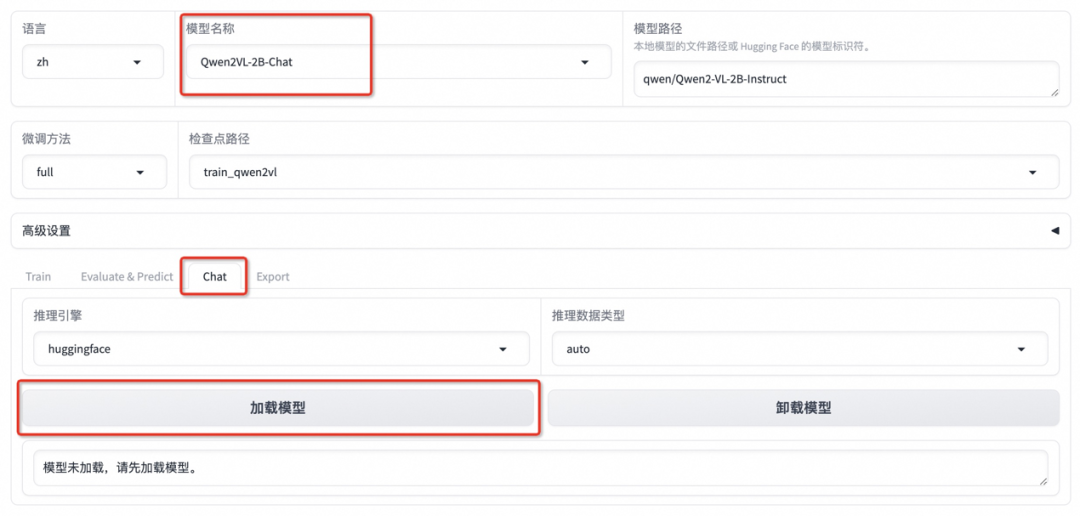
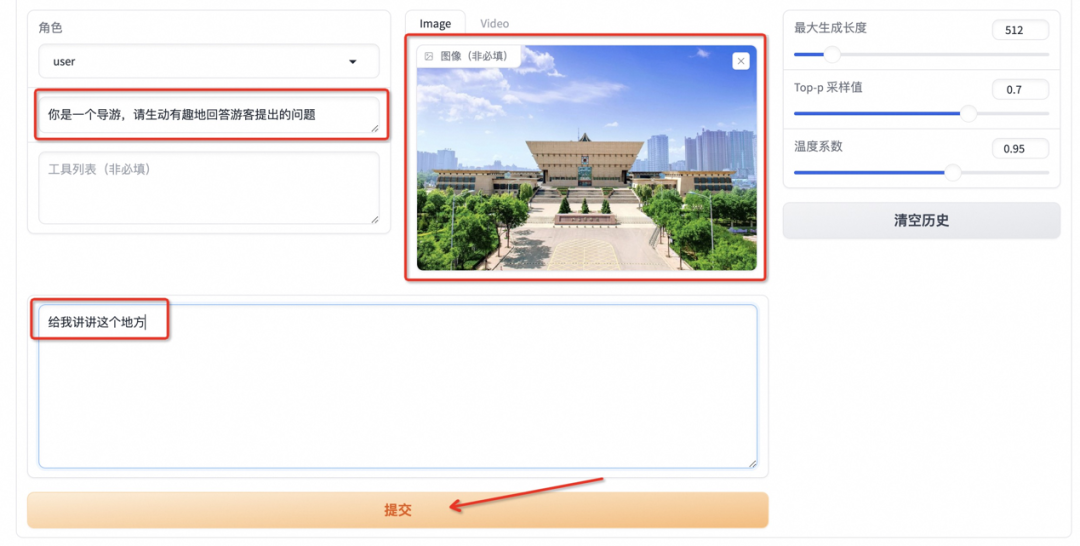
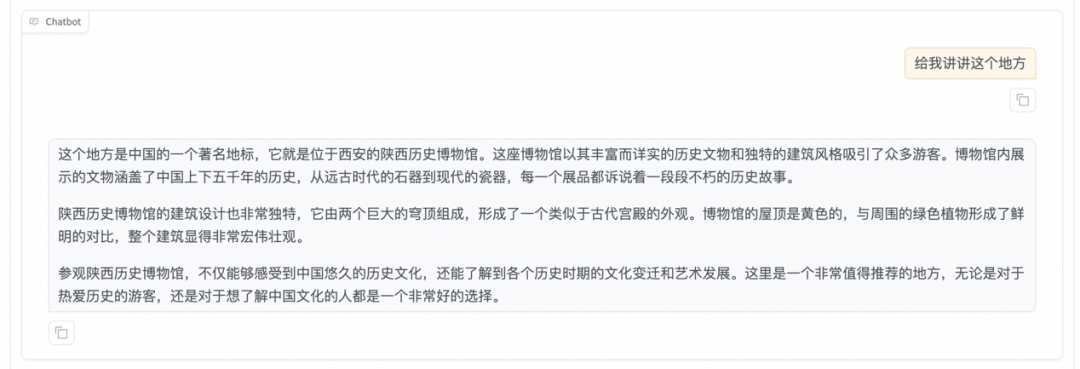
首先点击下载测试图片1或测试图片2,并上传至对话框的图像区域,接着在系统提示词区域填写“你是一个导游,请生动有趣地回答游客提出的问题”。在页面底部的对话框输入想要和模型对话的内容,点击提交即可发送消息。
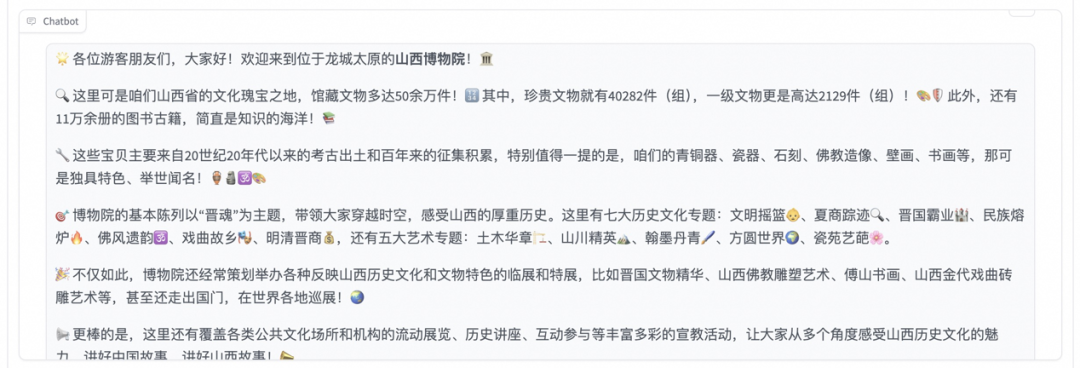
发送后模型会逐字生成回答,从回答中可以发现模型学习到了数据集中的内容,能够恰当地模仿导游的语气介绍图中的山西博物院。
点击「卸载模型」,点击检查点路径输入框取消勾选检查点路径,再次点击「加载模型」,即可与微调前的原始模型聊天。

重新向模型发送相同的内容,发现原始模型无法准确识别山西博物院。
三、资源清理和后续操作
- 资源清理
- 在实验完成后,前往控制台停止或删除实例,以避免资源的持续消耗和不必要的费用。
- 后续使用
- 在试用有效期内,可以继续使用DSW实例进行模型训练和推理验证,探索更多AI图像编辑的可能性。
四、晒出与AI 导游的创意对话,最高赢乐歌台式升降桌M2S
想必你通过实操,已经学会如何利用阿里云PAI-DSW和LLaMA Factory开源低代码大模型微调框架,微调 Qwen2-VL 模型,快速搭建文旅领域知识问答机器人。现在邀请你来到阿里云开发者社区参加**“使用PAI+LLaMA Factory 微调 Qwen2-VL 模型,搭建文旅领域知识问答机器人”活动,领取免费试用云资源,跟随教程完成作品生成并上传,得精美计时器,限量400个。邀请好友完成任务即有机会获得乐歌台式升降桌M2S、小米充电宝、小米双肩包等诸多好礼。点击阅读原文**查看活动详情~

如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈


















 9203
9203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









