



什么是内存池?
内存池是一种预分配内存并进行重复利用的技术,通过减少频繁的动态内存分配与释放操作,从而提高程序运行效率。内存池通常预先分配一块大的内存区域,将其划分为多个小块,每次需要分配内存时直接从这块区域中分配,而不是调用系统的动态分配函数(如new或malloc)。简单来说就是申请一块较大的内存块(不够继续申请),之后将这块内存的管理放在应用层执行,减少系统调用带来的开销。
为什么要做内存池?
性能优化:
- 减少动态内存分配的开销:系统调用
malloc/new和free/delete涉及复杂的内存管理操作(如内存查找、碎片整理),导致性能较低,而内存池通过预分配和简单的管理逻辑显著提高了分配和释放的效率。 - 避免内存碎片:动态分配内存会产生内存碎片,尤其在大量小对象频繁分配和释放的场景中,导致的后果就是:当程序长时间运行时,由于所申请的内存块的大小不定,频繁使用时会造成大量的内存碎片从而降低程序和操作系统的性能。内存池通过管理固定大小的内存块,可以有效避免碎片化。
- 降低系统调用频率:系统级内存分配(如
malloc)需要进入内核态,频繁调用会有较高的性能开销。内存池通过减少系统调用频率提高程序效率。
确定性(实时性):
- 稳定的分配时间:使用内存池可以使分配和释放操作的耗时更加可控和稳定,适合实时性有严格要求的系统。
内存池的设计
采用三级缓存的架构
+----------------------------------+
| 应用请求内存
+----------------------------------+
|
|
+----------------------------------+
| ThreadeCache
------------------------------------
| 检查本地缓存
| 有:直接分配
| 无:请求 Central
+----------------------------------+
|
|
+----------------------------------+
| CentralCache
------------------------------------
| 检查共享内存
| 有:分配给Thread
| 无:请求Pagre
+----------------------------------+
|
|
+----------------------------------+
| PageCache
------------------------------------
| 从操作系统获取
| 切分成小块
| 返还给Central
+----------------------------------+
- ThreadCache:无锁,快速分配
- CentralCache:自旋锁,管理多个线程共享的内存块,批量从PageCache获取内存,分配给 ThreadCache
- PageCache:锁,从操作系统获取大块内存,将大块内存切分成小块,供CentralCache使 用,负责内存的回收和再利用
分级缓存的目的是:
- 让小内存加小范围的锁,大内存加大范围的锁。控制锁的粒度,因为粒度越大冲突越大
- 提高内存分配效率
- 降低内存碎片
页缓存设计
class PageCache
{
public:
static const size_t PAGE_SIZE = 4096; // 4K 每个内存页的大小
static PageCache& getInstance()
{
static PageCache instance;
return instance;
}
// 分配指定页数的span 负责从页缓存中分配连续的内存页
void* allocateSpan(size_t numPages);
// 释放span
void deallocateSpan(void* ptr, size_t numPages);
private:
PageCache() = default;
// 用于向操作系统申请指定页数的内存。
void* systemAlloc(size_t numPages);
private:
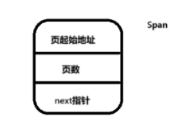
struct Span //用于表示一个连续的内存块
{
void* pageAddr; // 页起始地址
size_t numPages; // 页数
Span* next; // 链表指针
};
std::map<size_t, Span*> freeSpans_;
std::map<void*, Span*> spanMap_;
std::mutex mutex_;
};
- 系统内存申请
直接与操作系统交互,通过mmap申请大块内存
以页(4KB)为单位进行内存管理
充当内存池与操作系统之间的桥梁
- 大块内存管理
管理和组织空闲的内存页
处理内存的分配和回收
实现内存页的合并和分割
- 可以通过组合多个页面来满足大内存的需求
- 也可以将大的页面分割成小的页面
- 提供了灵活的内存分配策略
为什么以页为单位?
1. 以页为单位可以简化内存管理的复杂度
2. 使用map数据结构可以快速找到合适大小的内存块
3. 便于实现内存的分配和回收算法
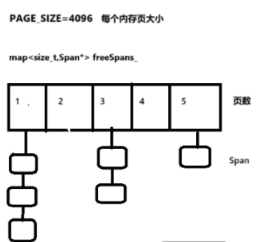
`freeSpans_`:这是一个 `std::map<size_t, Span*>` 类型的容器,它按 `span` 包含的页数对空闲的 `span` 进行分类管理,每个页数对应一个 `Span` 链表。`freeSpans_` 主要用于在分配内存时快速找到合适大小的空闲 `span`。
spanMap_:
- 记录所有由PageCache管理的span(包括已分配和空闲的)
- 用于内存地址到span的快速映射
- 主要用途是内存管理和合并操作
重点函数实现
void PageCache::deallocateSpan(void* ptr, size_t numPages)
{
std::lock_guard<std::mutex> lock(mutex_);
// 查找对应的span,没找到代表不是PageCache分配的内存,直接返回
auto it = spanMap_.find(ptr);
if (it == spanMap_.end()) return;
Span* span = it->second;
// 尝试合并相邻的span
void* nextAddr = static_cast<char*>(ptr) + numPages * PAGE_SIZE;
auto nextIt = spanMap_.find(nextAddr);
if (nextIt != spanMap_.end())
{
Span* nextSpan = nextIt->second;
// 1. 首先检查nextSpan是否在空闲链表中
bool found = false;
auto& nextList = freeSpans_[nextSpan->numPages];
// 检查是否是头节点
if (nextList == nextSpan)
{
nextList = nextSpan->next;
found = true;
}
else if (nextList) // 只有在链表非空时才遍历
{
Span* prev = nextList;
while (prev->next)
{
if (prev->next == nextSpan)
{
// 将nextSpan从空闲链表中移除
prev->next = nextSpan->next;
found = true;
break;
}
prev = prev->next;
}
}
// 2. 只有在找到nextSpan的情况下才进行合并
if (found)
{
// 合并span
span->numPages += nextSpan->numPages;
spanMap_.erase(nextAddr);
delete nextSpan;
}
}
// 将合并后的span通过头插法插入空闲列表
auto& list = freeSpans_[span->numPages];
span->next = list;
list = span;
}
主要作用是释放之前通过 `PageCache` 分配的内存页范围(`span`),并尝试将释放的 `span` 与相邻的空闲 `span` 进行合并,最后将合并后的 `span` 重新插入到空闲列表中,以减少内存碎片,提高内存利用率。
1. 加锁:使用 `std::lock_guard` 对互斥锁 `mutex_` 进行加锁,确保在多线程环境下对 `PageCache` 的操作是线程安全的。
2. 查找 `span`:通过 `spanMap_` 查找 `ptr` 对应的 `span`。如果未找到,说明该内存块不是由 `PageCache` 分配的,直接返回。
3. 尝试合并相邻的 `span`:计算当前 `span` 相邻的下一个 `span` 的起始地址 `nextAddr`,并在 `spanMap_` 中查找该地址对应的 `span`。如果找到,检查其是否在空闲链表 `freeSpans_` 中。如果在,将其从链表中移除,并与当前 `span` 进行合并。
4. 插入到空闲列表:将合并后的 `span` 通过头插法插入到 `freeSpans_` 中对应的空闲链表头部。
中心缓存设计
class CentralCache
{
public:
static CentralCache& getInstance()
{
static CentralCache instance;
return instance;
}
void* fetchRange(size_t index, size_t batchNum);
void returnRange(void* start, size_t size, size_t index);
private:
// 相互是还所有原子指针为nullptr
CentralCache()
{
for (auto& ptr : centralFreeList_)
{
ptr.store(nullptr, std::memory_order_relaxed);
}
// 初始化所有锁
for (auto& lock : locks_)
{
lock.clear();
}
}
// 从页缓存获取内存
void* fetchFromPageCache(size_t size);
private:
// 中心缓存的自由链表数组 == atomic<void*> arr[FREE_LIST_SIZE]
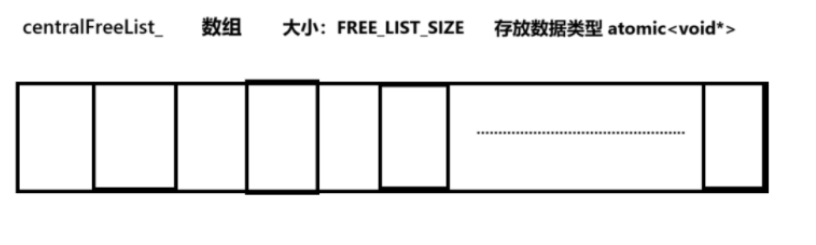
std::array<std::atomic<void*>, FREE_LIST_SIZE> centralFreeList_;
// 用于同步的自旋锁
std::array<std::atomic_flag, FREE_LIST_SIZE> locks_;
};
主要实现
void* CentralCache::fetchRange(size_t index, size_t batchNum)
{
// 索引检查,当索引大于等于FREE_LIST_SIZE时,说明申请内存过大应直接向系统申请
// 首先检查传入的索引是否超出了允许的范围,或者请求的批量数量是否为 0,如果是则返回 nullptr。
if (index >= FREE_LIST_SIZE || batchNum == 0)
return nullptr;
// 自旋锁保护
// 使用自旋锁 locks_[index] 来保证同一时间只有一个线程可以访问该索引对应的中心缓存链表,避免数据竞争。
//while(..)只要返回true说明锁已经被其他线程占有
// 如果锁已经被其他线程持有,当前线程会调用 std::this_thread::yield() 让出 CPU 时间片,避免忙等待。
while (locks_[index].test_and_set(std::memory_order_acquire))
{
std::this_thread::yield(); // 添加线程让步,避免忙等待,避免过度消耗CPU
}
void* result = nullptr;
try
{
// 尝试从中心缓存获取内存块
// 从中心缓存的对应索引位置获取内存块链表的头指针。
result = centralFreeList_[index].load(std::memory_order_relaxed);
if (!result)
{
// 如果中心缓存为空,从页缓存获取新的内存块
// 计算请求的内存块实际大小。
size_t size = (index + 1) * ALIGNMENT; //按照ALIGNMENT(8)字节对齐
// 调用 fetchFromPageCache 函数从页缓存中获取新的内存块。
//批量获取,一次最少SPAN_PAGES(8)页,每页PAGE_SIZE(4096--4k)大小
result = fetchFromPageCache(size);
if (!result)
{
// 如果从页缓存获取失败,释放锁并返回 nullptr。
locks_[index].clear(std::memory_order_release);
return nullptr;
}
// 将从PageCache获取的内存块切分成小块
// 将获取到的内存块指针转换为 char* 类型,方便进行内存块的切分操作。
char* start = static_cast<char*>(result);
// 计算获取到的内存块总共可以切分成多少个小块。
size_t totalBlocks = (SPAN_PAGES * PageCache::PAGE_SIZE) / size;
// 取请求的批量数量和总块数的较小值,作为本次要分配的块数。
size_t allocBlocks = std::min(batchNum, totalBlocks);
// 构建返回给ThreadCache的内存块链表
if (allocBlocks > 1)
{
// 确保至少有两个块才构建链表
// 构建链表,将每个小块的 next 指针指向下一个小块。
for (size_t i = 1; i < allocBlocks; ++i)
{
void* current = start + (i - 1) * size;
void* next = start + i * size;
*reinterpret_cast<void**>(current) = next;
}
// 将最后一个小块的 next 指针置为 nullptr,表示链表结束。
*reinterpret_cast<void**>(start + (allocBlocks - 1) * size) = nullptr;
}
// 构建保留在CentralCache的链表
if (totalBlocks > allocBlocks)
{
// 计算剩余内存块的起始位置。
void* remainStart = start + allocBlocks * size;
// 构建剩余内存块的链表。
for (size_t i = allocBlocks + 1; i < totalBlocks; ++i)
{
void* current = start + (i - 1) * size;
void* next = start + i * size;
*reinterpret_cast<void**>(current) = next;
}
// 将最后一个剩余小块的 next 指针置为 nullptr,表示链表结束。
*reinterpret_cast<void**>(start + (totalBlocks - 1) * size) = nullptr;
// 将剩余内存块链表的头指针存储到中心缓存的对应索引位置。
centralFreeList_[index].store(remainStart, std::memory_order_release);
}
}
else // 如果中心缓存有index对应大小的内存块
{
// 从现有链表中获取指定数量的块
// 遍历现有链表,找到第 batchNum 个块。
void* current = result;
void* prev = nullptr;
size_t count = 0;
while (current && count < batchNum)
{
prev = current;
current = *reinterpret_cast<void**>(current);
count++;
}
if (prev) // 当前centralFreeList_[index]链表上的内存块大于batchNum时需要用到
{
// 将第 batchNum 个块的前一个块的 next 指针置为 nullptr,截断链表。
*reinterpret_cast<void**>(prev) = nullptr;
}
// 将截断后剩余链表的头指针存储到中心缓存的对应索引位置。
centralFreeList_[index].store(current, std::memory_order_release);
}
}
catch (...)
{
// 如果发生异常,释放锁并重新抛出异常。
locks_[index].clear(std::memory_order_release);
throw;
}
// 释放锁
locks_[index].clear(std::memory_order_release);
return result;
}
线程缓存的设计
class ThreadCache
{
public:
// 单例模式,每个线程一个实例
static ThreadCache* getInstance()
{
static thread_local ThreadCache instance;
return &instance;
}
void* allocate(size_t size);
void deallocate(void* ptr, size_t size);
private:
ThreadCache() = default;
// 从中心缓存获取内存
void* fetchFromCentralCache(size_t index);
// 归还内存到中心缓存
void returnToCentralCache(void* start, size_t size, size_t bytes);
// 每个线程的自由链表数组
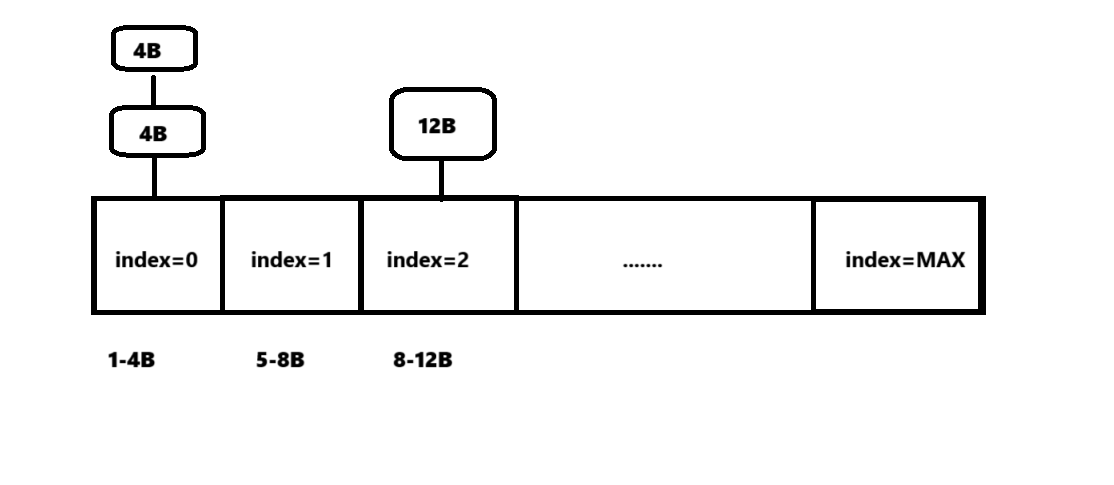
std::array<void*, MAX> freeList_;
std::array<size_t,MAX> freeListSize_; // 自由链表大小统计
};
freeList_:
主要实现
void* ThreadCache::allocate(size_t size)
{
// 处理0大小的分配请求
if (size == 0)
{
size = ALIGNMENT; // 至少分配一个对齐大小
}
if (size > MAX_BYTES)
{
// 大对象直接从系统分配
return malloc(size);
}
size_t index = SizeClass::getIndex(size);
// 更新自由链表大小
freeListSize_[index]--;
// 检查线程本地自由链表
// 如果 freeList_[index] 不为空,表示该链表中有可用内存块
if (void* ptr = freeList_[index])
{
freeList_[index] = *reinterpret_cast<void**>(ptr); // 将freeList_[index]指向的内存块的下一个内存块地址(取决于内存块的实现)
return ptr;
}
// 如果线程本地自由链表为空,则从中心缓存获取一批内存
return fetchFromCentralCache(index);
}

















 343
343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









