




线性回归是预测连续结果的关键数据科学工具。本指南解释了它的原则、用途以及如何使用真实数据在 Python 中实现它。它涵盖了简单线性回归和多元线性回归,重点介绍了它们的重要性、局限性和实际示例。
在本文中,您将了解线性回归,这是机器学习中的一个关键概念。我们将探讨什么是线性回归,它如何作为线性回归模型,以及它在基于数据关系预测结果中的应用。
学习目标
• 了解线性回归的原理和应用。
• 区分简单线性回归和多元线性回归。
• 了解如何在 Python 中实现简单线性回归。
• 掌握梯度下降的概念及其在优化线性回归中的用途。
• 探索用于评估回归模型的评估指标。
• 识别线性回归中的假设和潜在陷阱,例如过度拟合和多重共线性。
什么是线性回归?
线性回归通过假设两个变量具有直线连接来预测它们之间的关系。它找到使预测值和实际值之间的差异最小的最佳线。它用于经济和金融等领域,有助于分析和预测数据趋势。线性回归也可以涉及多个变量(多元线性回归)或适用于是/否问题(逻辑回归)。
简单线性回归
在简单线性回归中,有一个自变量和一个因变量。该模型估计最佳拟合线的斜率和截距,它表示变量之间的关系。斜率表示自变量中每个单位变化的因变量变化,而截距表示自变量为零时因变量的预测值。
线性回归是一种安静且最简单的统计回归技术,用于机器学习中的预测分析。它显示了自(预测)变量(即 X 轴)和因(输出)变量(即 Y 轴)之间的线性关系,称为线性回归。如果存在单个输入变量 X(自变量),则此类线性回归是简单线性回归。

上图显示了 output(y) 和 predictor(X) 变量之间的线性关系。蓝色线称为最佳拟合直线。根据给定的数据点,我们尝试绘制一条最适合这些点的线。
简单回归计算
为了计算最佳拟合线,线性回归使用传统的斜率截距形式,如下所示:
Y i = β 0 + β 1 X i
其中 Y i = 因变量,β 0 = 常数/截距,β 1 = 斜率/截距,X i = 自变量。
此算法使用直线 Y= B 0 + B 1 X 解释因(输出)变量 y 和自(预测变量)变量 X 之间的线性关系。
但是回归如何找出哪条线是最合适的线呢?
线性回归算法的目标是获取 B 0 和 B 1 的最佳值,以找到最佳拟合线。最佳拟合线是误差最小的线,这意味着预测值和实际值之间的误差应该最小。
但是线性回归如何找出哪条线是最好的呢?
线性回归算法的目标是获取B 的最佳值0和 B1以找到最佳拟合线。最佳拟合线是误差最小的线,这意味着预测值和实际值之间的误差应该最小。
随机误差(残差)
在回归中,因变量的观测值 (y i ) 与预测值 (预测) 之间的差值称为残差。
ε I = Y 预测 – Y I
其中 y 预测 = B 0 + B 1 X i
什么是最佳拟合线?
简单来说,最佳拟合线是最适合给定散点图的线。从数学上讲,您可以通过最小化残差平方和 (RSS) 来获得最佳拟合线。
线性回归的 Cost 函数
成本函数有助于计算出 B 0 和 B 1 的最佳值,从而为数据点提供最佳拟合线。
在线性回归中,通常使用均值平方Error (MSE) 成本函数,即 y 预测值与 y i 之间发生的平均平方误差。
我们使用简单的线性方程 y=mx+b 计算 MSE:
使用 MSE 函数,我们将更新 B 0 和 B 1 的值,以便 MSE 值稳定在最小值。可以使用梯度下降法确定这些参数,以使成本函数的值最小。
线性回归的梯度下降
梯度下降 (Gradient Descent) 是一种优化算法,可优化成本函数 (目标函数) 以达到最佳最小解。为了找到最佳解决方案,我们需要降低所有数据点的成本函数 (MSE)。这是通过迭代更新斜率系数 (B1) 和常数系数 (B0) 的值来完成的,直到我们得到线性函数的最佳解。
回归模型通过随机选择系数值来减少成本函数,然后迭代更新系数值以达到最小成本函数,从而优化梯度下降算法以更新线的系数。
梯度下降示例
让我们举个例子来理解这一点。想象一个 U 形坑。你站在坑的最高点,你的动机是到达坑底。假设坑底有个宝藏,您只能走不连续的步数才能到达底部。如果您选择一次迈出一步,您最终会到达坑底,但这需要更长的时间。如果您决定每次都采取更大的步骤,您可能会更快地到达底部,但是,您有可能超过坑底,甚至不会接近底部。在 gradient descent 算法中,您采取的步数可以被视为学习率,这决定了算法收敛到最小值的速度。
为了更新 B 0 和 B 1,我们从成本函数中获取梯度。为了找到这些梯度,我们对 B 0 和 B 1 进行偏导数。
我们需要最小化成本函数 J。实现此目的的方法之一是应用批量梯度下降算法。在 batch gradient descent 中,值在每次迭代中更新。(最后两个方程显示了值的更新)
部分导数是梯度,它们用于更新 B 0 和 B 1 的值。Alpha 是学习率。
为什么线性回归很重要?
线性回归很重要,原因如下:
• 简单性和可解释性:这是一个相对容易理解和应用的概念。生成的简单线性回归模型是一个简单的方程,用于显示一个变量如何影响另一个变量。与更复杂的模型相比,这使得更容易解释和信任结果。
• 预测:线性回归允许您根据现有数据预测未来值。例如,您可以使用它来根据营销支出预测销售额或根据平方英尺预测房价。
• 其他技术的基础:它是许多其他数据科学和机器学习方法的构建块。即使是复杂的算法也经常依赖线性回归作为起点或用于比较目的。
• 广泛的适用性:线性回归可用于各个领域,从金融和经济学到科学和社会科学。它是一个多功能工具,用于揭示许多实际场景中变量之间的关系。
从本质上讲,线性回归为理解数据和进行预测提供了坚实的基础。这是一项为更高级的数据分析方法铺平道路的基础技术。
线性回归的评估指标
任何线性回归模型的强度都可以使用各种评估指标进行评估。这些评估指标通常用于衡量模型生成观察到的输出的程度。
最常用的指标是
- 决定系数或 R 平方 (R2)
- 均方根误差 (RSME) 和残差标准误差 (RSE)
决定系数或 R 平方 (R2)
R 平方是一个数字,用于解释开发的模型解释/捕获的变异量。它总是在0和1之间。总体而言,R 平方的值越高,模型与数据的拟合就越好。
在数学上,它可以表示为,
R2= 1 – ( RSS/TSS )
• 残差平方和 (RSS) 定义为绘图/数据中每个数据点的残差平方和。它是预期和实际观测输出之间差值的度量。
• 总平方和 (TSS) 定义为数据点与响应变量平均值的误差之和。数学上 TSS 是,
其中 y hat 是样本数据点的平均值。
R 平方的显著性如下图所示,
均方根误差
均方根误差是残差方差的平方根。它指定模型与数据的绝对拟合度,即观察到的数据点与预测值的接近程度。在数学上,它可以表示为,
为了使此估计无偏,必须将残差的平方和除以自由度,而不是模型中数据点的总数。该术语称为残差标准误差 (RSE)。在数学上,它可以表示为,
R 平方是比 RSME 更好的度量。由于均方根误差的值取决于变量的单位(即它不是标准化的度量),因此它可以随着变量单位的变化而变化。
线性回归的假设
回归是一种参数方法,这意味着它对要分析的数据做出假设。要成功进行回归分析,必须验证以下假设。
-
残差的线性度:因变量和自变量之间需要存在线性关系。
-
残差的独立性: 误差项不应相互依赖(就像在时间序列数据中一样,其中下一个值依赖于前一个值)。残差项之间不应有关联。这种现象的缺失称为自相关。
错误项中不应有任何可见的模式。
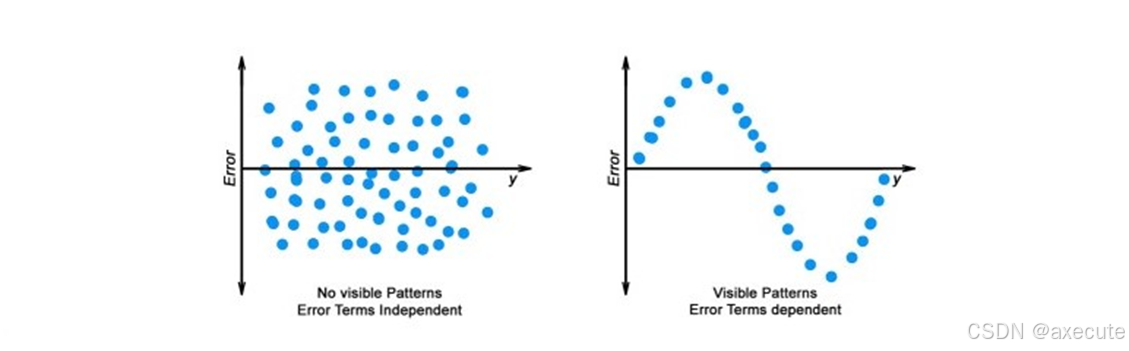
-
残差的正态分布:残差的均值应服从均值等于零或接近零的正态分布。这样做是为了检查所选行是否为最佳行。如果误差项是非正态分布的,则表明必须仔细研究一些不寻常的数据点才能制作出更好的模型。
-
残差的相等方差:误差项必须具有常数方差。这种现象被称为 Homoscedasticity。误差项中存在的非常量方差称为异方差。通常,在存在异常值或极端杠杆值时会出现非常量方差。
线性回归中的假设
在数据上拟合了一条直线后,您需要问:“这条直线是否与数据有显著的拟合?“或者”Is the beta coefficient explain the variance in the drawing data?”这就是对 beta 系数进行假设检验的想法。在这种情况下,Null 和 Alternate 假设是:
H 0 : B 1 = 0
H A : B 1 ≠ 0
为了检验这个假设,我们使用 t 检验,beta 系数的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









