






一、Kafka核心概念
kafka是一个分布式流处理平台,主要用于构建实时数据管道和流处理应用。通俗来讲,生产者生产(Produce)消息,消费者消费(Consume)消息,在两者之间,需要一个沟通的桥梁,即不同系统之间如何进行传递消息。
二、Kafka的作用(应用)
1.消息队列:生产者生产消息,消费者读取消息,从而实现系统之间的解耦;
2.日志收集:可以收集来自不同服务的日志数据,供后续处理和分析;
3.流处理:实时处理数据;
4.事件驱动架构:kafka支持事件驱动架构,系统中的各个组件可以听你刚刚事件进行驱动。例如,订单系统生成订单创建事件,库存系统消费该事件并更新库存。
5.数据缓冲:kafka可以做为数据缓冲层,平衡生产者和消费者之间的速度差异;
注意:feign远程调用是同步调用,不同服务之间的调用为异步调用,需要使用消息中间件,例如,自媒体微服务调用文章微服务,进行内容的上架或下架;
三、安装(docker)
kafka支持集群部署,broker集群的注册管理和Topic的注册管理需要用到注册中心的zookeeper。安装kafka之前需要安装zookeeper
docker下载镜像
docker pull zookeeper:3.4.14docker创建容器
docker run -d --nume zookeeper -p 218l:218l zookeeper:3.4.14docker安装kafka
docker pull wrstmcister/kafka:2.12-2.3.1docker创建容器
docker run -d --name kafka \
--env KAFKA ADVERTISED HOST NAME-192.168.216.139 \
--env KAFKA Z00KEEPER CONNECT-192.168.216.139:2181 \
--env KAFKA ADVERTISED LISTENERS=PLAINTEXT://192.168.216.139:9092 \
--env KAFKA LISTENERS-PLAINTEXT://0.0.0.0:9092 \
--env KAFKA HEAPOPTS-”Xmx256MXms256M \
net=host wurstmeister/kafka:2.12-2.3.1注意:上面的ip地址都要换成自己的ip地址
四、具体使用
- 新手入门
(1)导入依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.8.0</version>
</dependency>
</dependencies>(2)编写生产者类ProducerTest
//设置kafka的配置信息
Properties properties=new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.216.139:9092");
//消息key的序列化器
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//消息value的序列化器
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//创建生产者对象
KafkaProducer<String,String> producer=new KafkaProducer<String,String>(properties);
//发送消息
ProducerRecord<String,String> record=new ProducerRecord<String,String>("topic","aaa","bbb");
producer.send(record);
producer.close();(3)编写消费者者类ConsumerTest
//配置kafka的配置信息
Properties properties=new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.216.139:9092");
//设置消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group1");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
//创建消费者对象
KafkaConsumer<String,String> consumer=new KafkaConsumer<String,String>(properties);
consumer.subscribe(Collections.singletonList("topic"));
while (true){
ConsumerRecords<String,String> consumerRecords=consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println(consumerRecord.key());
System.out.println(consumerRecord.value());
}
//同步提交消费者当前的偏移量
consumer.commitSync();
}注意:
1.上述put键和值的第二个参数是在External Libraries中找的kafka中找的类路径,Producer中找的是序列化类,Consumer中找的是反序列化类;
2.一定要先启动Consumer类在启动Producer类,
3.IP地址一定要换成自己的
上述实现的结果是:
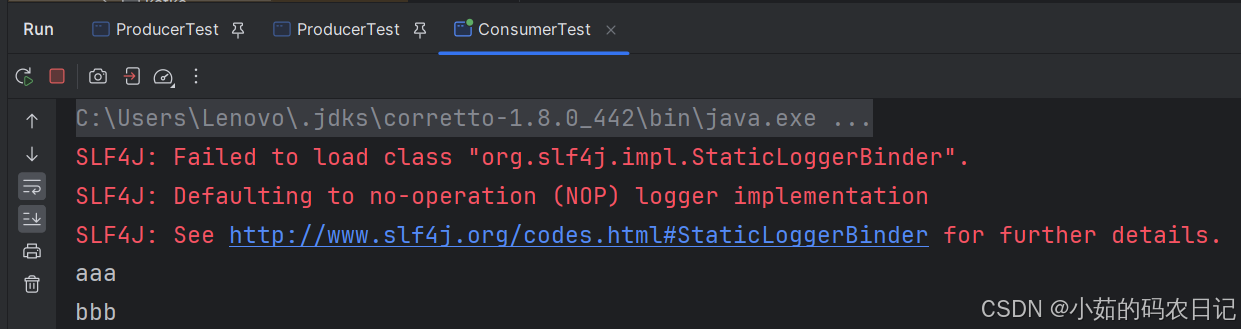
2.基于Spring Boot的RESful API 与Kafka集成——使用类控制器来实现Kafka消息的生产和消费
(1)引入依赖
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.6.6</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.3.9.RELEASE</version>
</dependency>
</dependencies>(2)在modul中配置application.yml
server:
port: 9991
spring:
application:
name: kafka02
kafka:
bootstrap-servers: 192.168.216.139:9092
producer:
retries: 10
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: ${spring.application.name}-test
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
注意:上述的IP地址需要把地址换为自己的;下面的生产者中的序列化器和消费者的反序列化器要对应,一定要对应,不然会出现毒丸现象。
(3)生产者
@RestController
@RequestMapping("/produce")
public class ProduceTest {
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
@GetMapping("/hello")
public String hello(){
kafkaTemplate.send("topic1", "aaa");
return "ok";
}
}(4)消费者
@Component
public class ConsumerTest {
@KafkaListener(topics = "topic1")
public void consumer(String message){
if (!StringUtils.isEmpty(message)){
System.out.println(message);
}
}
}(5)结果
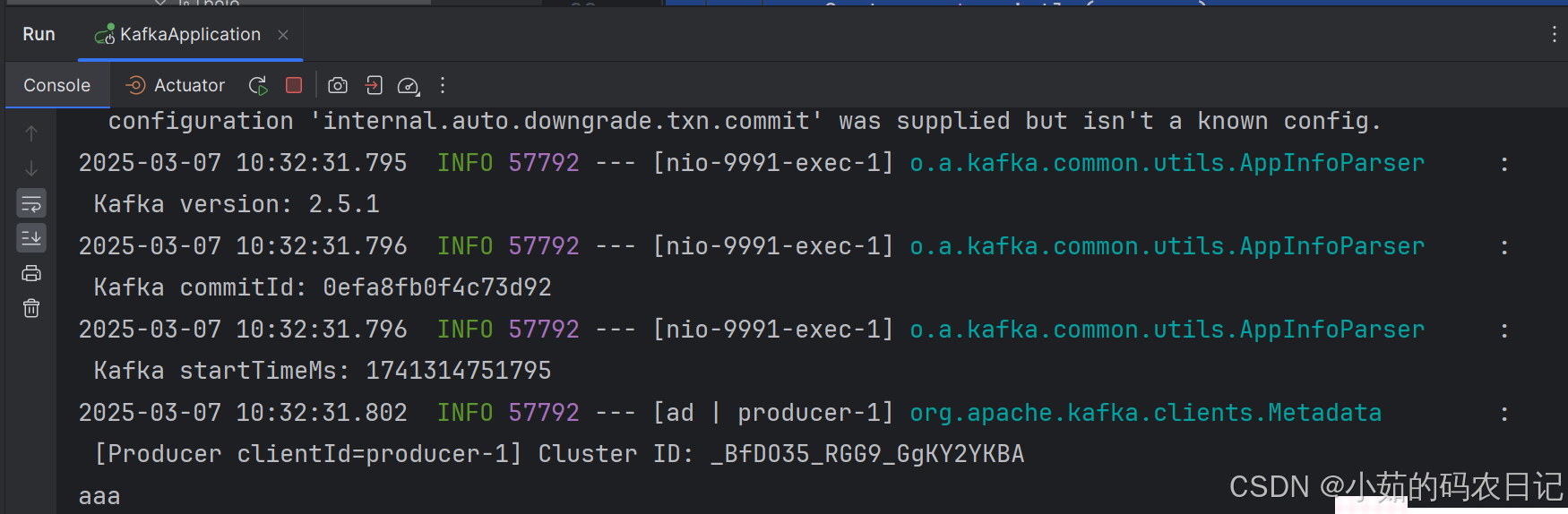
项目实战应用场景:发布内容上架、下架;内容点赞、取消点赞;内容收藏、取消收藏;上述内容的实时更新。
五、其他
1.消息队列通信模式
(1)点对点模式——基于拉取或是轮询的消息传递模型,发送到队列的消息被一个且只有一个消费者进行处理。
(2)发布订阅模式——生产者将消息放入队列后,队列会将消息推送给订阅过该类消息的消费者。

















 713
713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









