



1.语义通信
语义通信简介
语义通信被视为一种有望突破香农极限的先进技术。
认知语义通信:它不仅理解和传输语义,还能动态学习、推理、预测信息的语义相关性,从而实现更高效的通信。
┌──────────────────────────────────┐
│ 认知语义通信框架 │
├──────────────────────────────────┤
│ 1. 语义层(Semantic Layer) │ ← 提取语义信息(如三元组)
│ 2. 认知层(Cognitive Layer) │ ← 学习用户意图、上下文、知识推理
│ 3. 通信层(Physical Layer) │ ← 实际信号传输、资源分配
└──────────────────────────────────┘
语义信息三元组:头实体、关系、尾实体
-
头实体 (Head Entity, h)
通常是主语或起点,比如 “爱因斯坦”、“微软”、“太阳”。 -
关系 (Relation, r)
表示头实体与尾实体之间的语义联系,比如 “出生地”、“创始人”、“是一种”。 -
尾实体 (Tail Entity, t)
通常是宾语或终点,比如 “德国”、“比尔·盖茨”、“恒星”。
| 示例语句 | 语义三元组表示 |
|---|---|
| “爱因斯坦出生于德国。” | (爱因斯坦, 出生地, 德国) |
| “微软的创始人是比尔·盖茨。” | (微软, 创始人, 比尔·盖茨) |
| “太阳是恒星。” | (太阳, 是一种, 恒星) |
语义通信的三种实现方式
目标导向通信:根据目标导向指标,只传输重要和必要信息。在这种范式中通过过滤掉与通信目标相关性较低的冗余信息来实现语义压缩。仅限于某些特定的无线服务或通信环境。
神经网络嵌入:利用神经网络将原始数据嵌入到低维空间中,以压缩源信息来实现语义通信。依赖于大规模深度学习(DL)模型,以准确和快速地识别和提取预期的语义信息,并且不需要语义指标。然而,深度学习通常需要大量高质量的标记数据。
知识共享:利用源和目的地之间的共享知识库来实现语义压缩和通信。借助知识库实现语义压缩和通信,而无需语义指标。此外,由于知识库中的推理规则,它在压缩过程中具有可解释性。
| 维度 | 目标导向通信 | 神经网络嵌入 | 知识共享 |
|---|---|---|---|
| 出发点 | “我只要任务完成” | “我让模型学会理解语义” | “我们共享背景知识” |
| 关注点 | 任务目标(Task) | 数据特征(Feature) | 知识与语境(Knowledge) |
| 实现手段 | 特征筛选、任务优化 | 深度网络编码与语义向量 | 知识图谱与推理机制 |
| 压缩方式 | 丢弃任务无关信息 | 降维嵌入语义空间 | 只传差异信息(Δ语义) |
| 通信内容 | 与任务直接相关的信息 | 学习得到的语义特征向量 | 语义差异或新增知识 |
| 典型指标 | 任务完成率、控制精度 | 语义保真度、相似度 | 语义一致率、推理准确率 |
| 代表模型 | Task-Oriented Semantic Comm. | DeepSC, AutoEncoder, Transformer | Knowledge Graph-based Semantic Comm. |
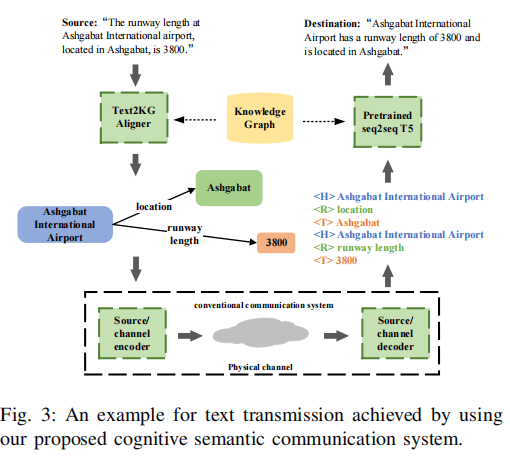
文章基于以上思路提出了一种基于知识图谱的认知语义通信系统,该知识图谱是发送方和接收方之间的共享知识库。为了开发一种简单且通用的语义信息检测解决方案,将三元组视为语义符号。由于三元组是更通用的语义组织形式,并且本质上可读,因此我们提出的系统是可解释的。此外,预训练模型被微调以恢复语义信息,这克服了使用固定比特长度编码来编码不同长度句子的缺点。系统在数据压缩率和通信可靠性方面优于其他基准系统。
认知语义通信系统的三个优势:
高效性:仅传输重要信息,可以实现高语义压缩率
稳定性:通过知识图谱驱动的推理来纠正语义错误,可以获得稳健的性能。
可解释性:知识图谱的三元组具有可理解性,可以实现通信过程的可解释性。
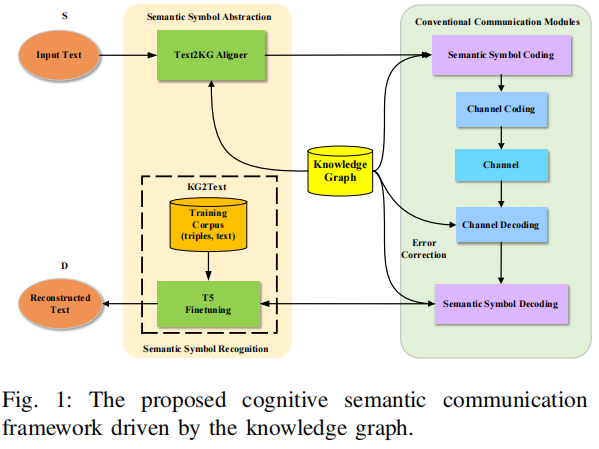
Text2KG 对齐器是一个语义匹配模块,用于:
从文本(Text)中提取语义三元组,并与知识图谱(KG)中的已有三元组进行比对、匹配或补全,形成一致的语义结构。
2.语义歧义:
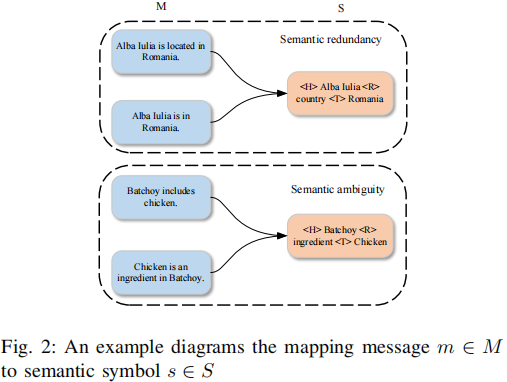
m到s是三元组映射是多对一,当多个不同的句子,在语义上表达的是同一个事实关系,因此它们会被映射到同一个三元组。
| 自然语言文本 | 对应的语义三元组 |
|---|---|
| “Batchoy里有鸡肉。” | (Batchoy, includes, chicken) |
| “Batchoy包含鸡。” | (Batchoy, includes, chicken) |
| “鸡肉是Batchoy的配料之一。” | (Batchoy, includes, chicken) |
| “Batchoy的主要成分之一是鸡肉。” | (Batchoy, includes, chicken) |
而语义信息三元组又一种语义的抽象表达, 舍弃了完整句子中的细节,导致语义压缩时会丢失部分上下文信息。最后导致句子里的内容三元组阐述不明确。比如“chicken” 是“鸡肉”还是“动物鸡”;“Batchoy” 是“一种食物”还是“一个地方”等等。
如何解决语义歧义:
传统 NLP 模型每个任务一种结构:
-
分类 → 输出标签
-
翻译 → 输出句子
-
问答 → 输出答案
T5(Text-to-Text Transfer Transformer) 的训练流程:
输入文本 → Encoder(编码器) → 语义向量表示
↓
Decoder(解码器) → 输出文本
预训练阶段:“Span Corruption”(文本片段掩码重构)
T5 用片段掩码(span masking)方式来训练语言理解与生成。
输入文本原句:
“The quick brown fox jumps over the lazy dog.”
T5 会随机掩盖部分连续片段(spans):
“The <extra_id_0> fox jumps over the <extra_id_1>.”
模型的训练目标是:
输出被掩盖的内容:
“<extra_id_0> = quick brown”
“<extra_id_1> = lazy dog”
也就是让模型学会根据上下文,重构被隐藏的文本片段。
训练时采用标准的 交叉熵损失(Cross Entropy Loss),
目标是最小化生成文本与真实文本之间的差异。
交叉熵损失函数:
假设信源以概率 Pr(m)随机传输消息 m,因此信源的消息熵 H(M)可以表示为:
(1) 消息熵 H(M)
含义:
消息源的不确定性,也就是香农信息论中的标准熵。
它衡量“系统中消息分布的随机程度”:
-
若所有消息等概率 → 熵最大;
-
若消息确定不变 → 熵为 0。
(2) 语义符号的概率 Pr(s)
含义:
语义符号的概率是所有映射到该语义的消息的概率之和。
这是因为:
一个语义可能对应多个不同的消息(多对一映射)。
例如:
-
“The car is fast.”
-
“This vehicle runs quickly.”
→ 两条不同的消息 m1,m2,可能都对应语义符号 s=“车很快”。
所以:
(3) 语义熵 H(S)
含义:
表示“语义层面的不确定性”。
它衡量“语义空间”中平均需要多少比特来唯一标识一个语义符号。
对比:
-
H(M):消息层面的不确定性(语法层)。
-
H(S):语义层面的不确定性。
由于语义是对消息的压缩和抽象,
通常 H(S)<H(M)。
(4) 熵的分解式
解释:
| 符号 | 含义 |
|---|---|
| H(S/M) | 条件熵:在已知消息 M 的情况下,语义 S 仍然的不确定性(映射模糊度) |
| I(M;S) | 互信息:S 和 M 之间共享的信息量(即 M 中有多少信息能反映 S) |
直觉上:
-
如果映射是一对一(每个消息唯一对应一个语义),那么 H(S/M)=0,此时 H(S)=I(M;S)。
-
若映射多对一(多个消息共指一个语义),则 H(S/M)>0,存在语义歧义。
(5) 改写公式
根据互信息定义:
代入得:
含义:
语义层面的信息量 = 消息层的信息量 + 语义模糊度 − 消息的可逆性损失。
消息的可逆性损失:

(6)物理与语义解释
| 项目 | 含义 | 语义通信意义 |
|---|---|---|
| H(M) | 原始消息的不确定性 | 发射端发送的比特复杂度 |
| H(S/M) | 在已知消息下语义的不确定性 | 表示语义歧义,即同一消息对应多个语义 |
| H(M/S) | 在已知语义下消息的不确定性 | 表示冗余度,不同消息表达同一语义 |
| H(S) | 语义层面的熵 | 接收端需要理解的语义复杂度 |
(7)T5 的训练核心总结:
-
预训练:在海量文本上学习“理解与生成语言”的通用能力(Span Corruption)。
-
微调:在具体任务(如三元组到文本)上学习“特定语义表达”的规则。
因此 T5 能在语义通信中充当语义重构器,有效减少语义歧义。


















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









