




 本文详细介绍了如何使用Scrapy模拟登录一个没有严格验证的网站,包括获取登录接口、注册账号、解析js函数、模拟提交登录请求以及处理验证码识别的过程,适合爬虫初学者学习。
本文详细介绍了如何使用Scrapy模拟登录一个没有严格验证的网站,包括获取登录接口、注册账号、解析js函数、模拟提交登录请求以及处理验证码识别的过程,适合爬虫初学者学习。
1,事件的开端是这样的
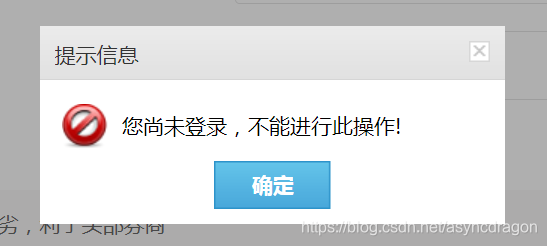
当遇到这种情况,要么跳过,要么就登陆咯。以前我们刚学爬虫的都是用selenium等工具模拟登录,今天刚好遇到一个在这方面不是很严的网站,所以可以直接接口进入。网址:aHR0cDovL3d3dy56dHNjLmNvbS5oay9ndy9pbmRleC9pbmRleC5zaHRtbA==
2,先看看登录接口页面
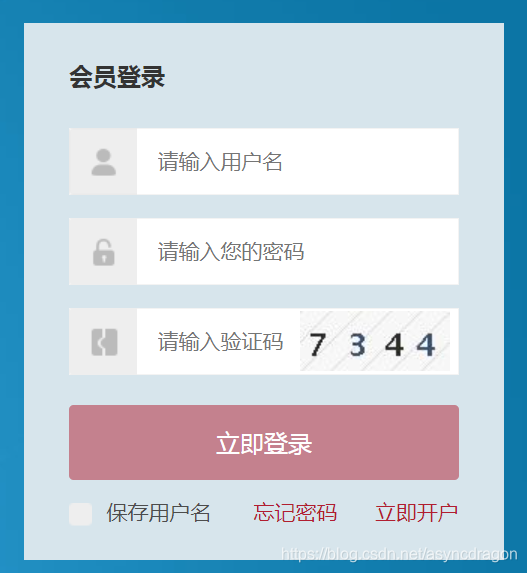
登录页面也没做隐藏,是那种一得就能得到的。
3,登录的话是需要有本网站的用户名和密码的,我之所以选择这个网站就是因为用户注册时是没有什么验证的。
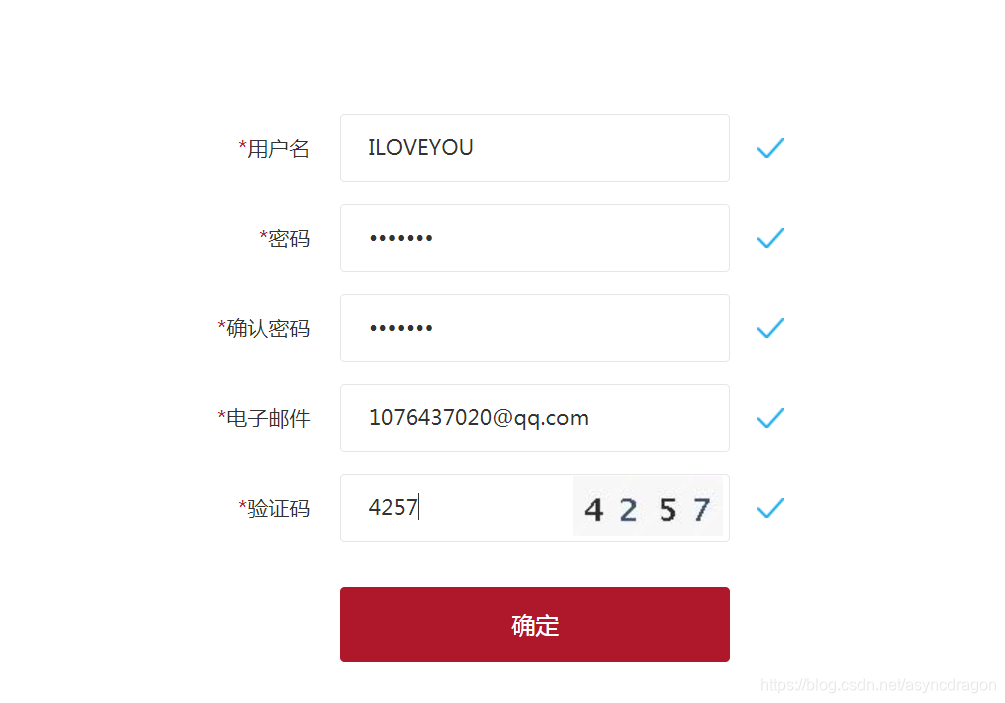
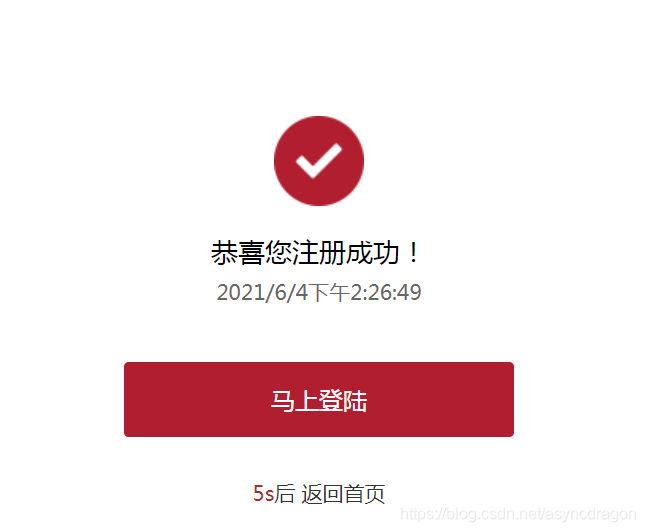
根本不需要输入真实的数据也可以注册成功,这样,我们就可以使用注册的账号密码登录了。
4,准备好了登录的账户就可以解析页面了

js函数没写出来,先搜一下。cvf
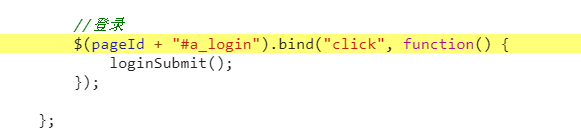
得到函数入口了,loginSubmit(),继续查找

这一串基本就是登录的发起点了
5,找到了js函数请求过程就可以模拟了,但是提交数据的时候是需要将验证码的信息带上,所以这里需要将验证码图片下载下来识别出正确数字,和账户密码一起提交。前端页面的验证码链接是这样的

但是我们请求登录页返回的页面源码是这样的

这里的区别告诉我中间少了什么步骤,所以是得去找验证码图片链接修改的地方。我们知道,验证码看不清的时候,是可以点击更换的,所以这里就根据验证码图片点击更换图片这一流程寻找思路。
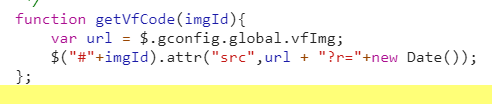
怎么找?那还是cvf,或者去调试吧。找到上面这个函数就是验证码图片修改的地方了。
6,什么都准备好了就可以写代码了吧
我使用的是scrapy,看这篇文章的伙伴可以使用其他的框架

先对登录界面来个请求,其实这一步是可以不要了,但我平时写爬虫喜欢来个起点。
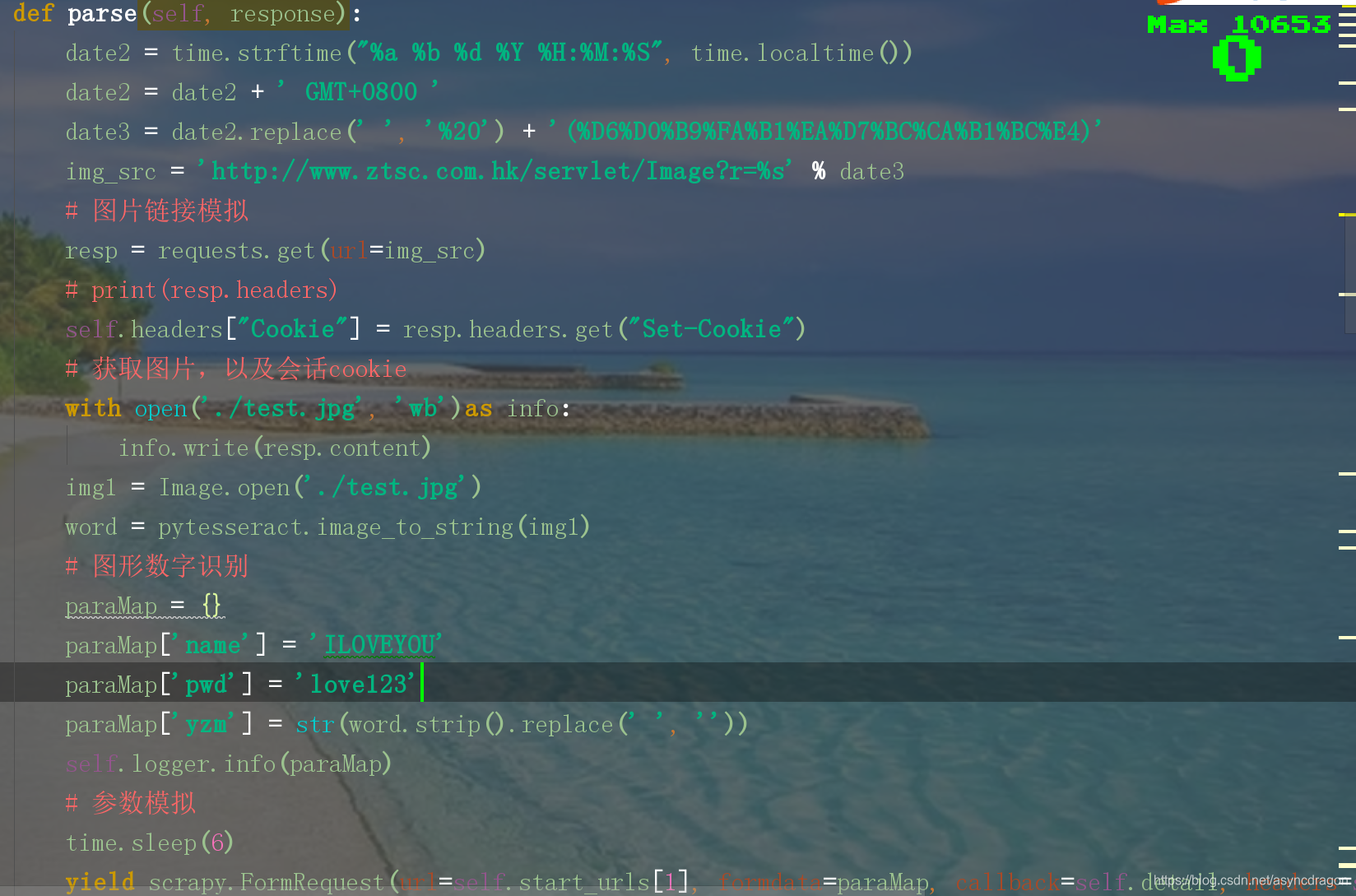
这上面的的一步可以拆分,思路是模拟图片链接,下载图片并识别,会话cookie添加,数据模拟提交
这其中的一步非常重要,有兴趣的可以去找找。
7,怎样才叫登录成功了?可以看js登录函数那里,success:后面的代码块,所以对应的可以做如下代码判断


















 318
318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









