



DPU(数据处理单元)作为继CPU和GPU之后的的第三颗主力芯片,所解决的核心问题是帮助数据中心基础设施“降本增效”——将“CPU处理效率低下、GPU处理不了”的负载卸载到DPU上。DPU不仅可以作为运算的加速引擎,还具备控制平面的功能,能够运行Hypervisor,更高效地完成网络虚拟化、IO虚拟化、存储虚拟化等任务,彻底将CPU的算力释放给应用程序,提升数据中心的有效算力。
近日,星融元数据联合智东西推出了主题为“开源DPU技术与应用场景”的技术公开课。星融元DPU技术负责人张敏以线上直播的形式,面向DPU开发从业者以及对相关技术感兴趣的各界人士,介绍了 Helium DPU产品开源的目的和进展、软硬件架构以及几大典型应用场景。现将直播要点整理如下,欢迎更多同仁与我们交流。

开源的目的与进展
构建开放网络是星融元一直坚持的理念,我们深知开源的力量。
开源模式有助于以市场自然选择的方式实现最优的发展路径:一方面广大社区里的广大开发者可以帮助检查软件代码漏洞,另一方面我们也能借助平台帮助DPU行业的技术人员快速地解决问题。
更重要的是,在创意的碰撞和交流过程中共同进步,一同探索新场景实现产品快速迭代。
目前星融元已将所有DPU产品开源到Github上,提供已验证的应用场景以及对应的软硬件技术实现,接下来也将不断更新提交,预计将于2023年11月推出下一代DPU产品。
相关阅读:这款国产高性能DPU智能网卡,即将开源!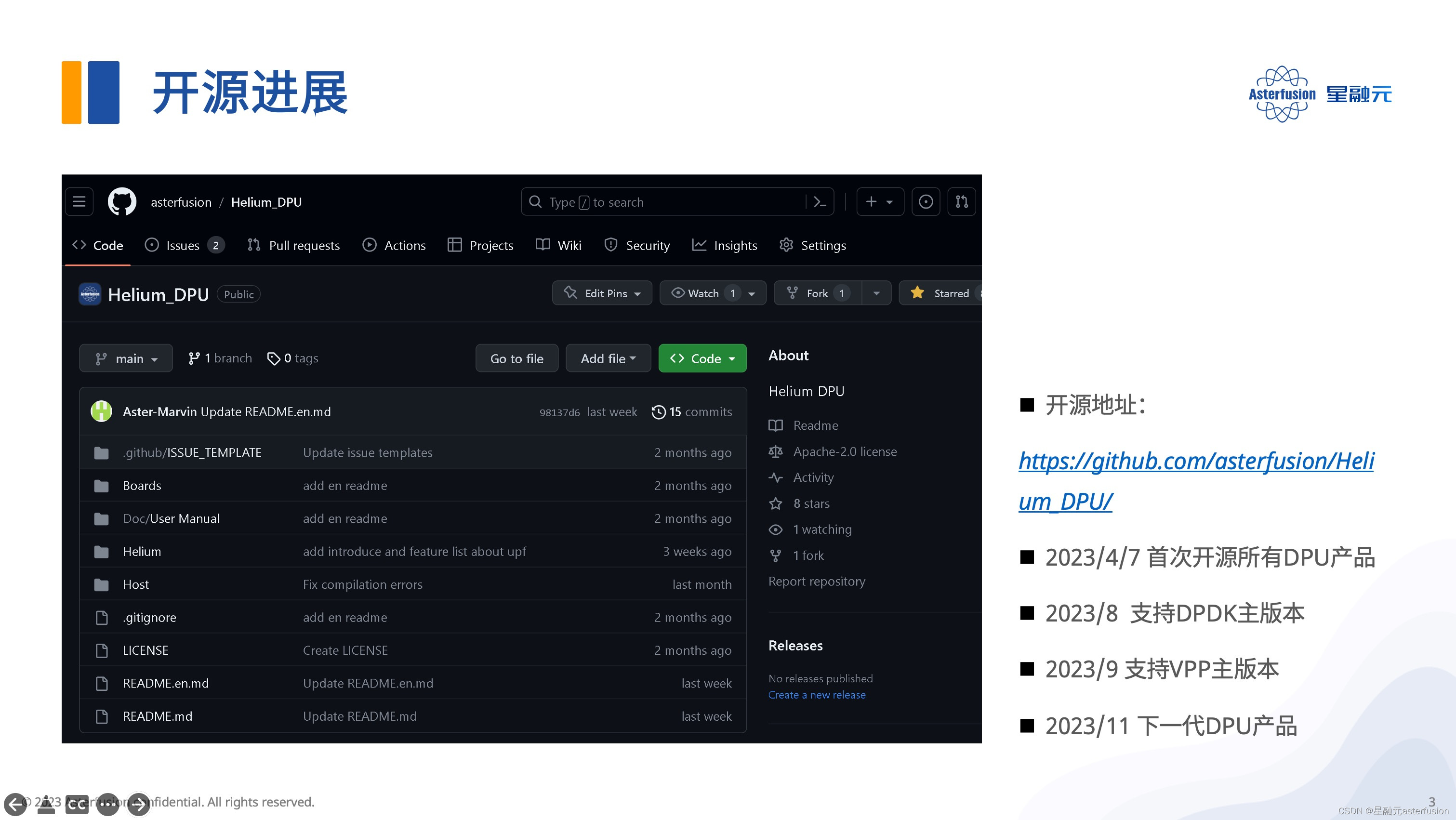
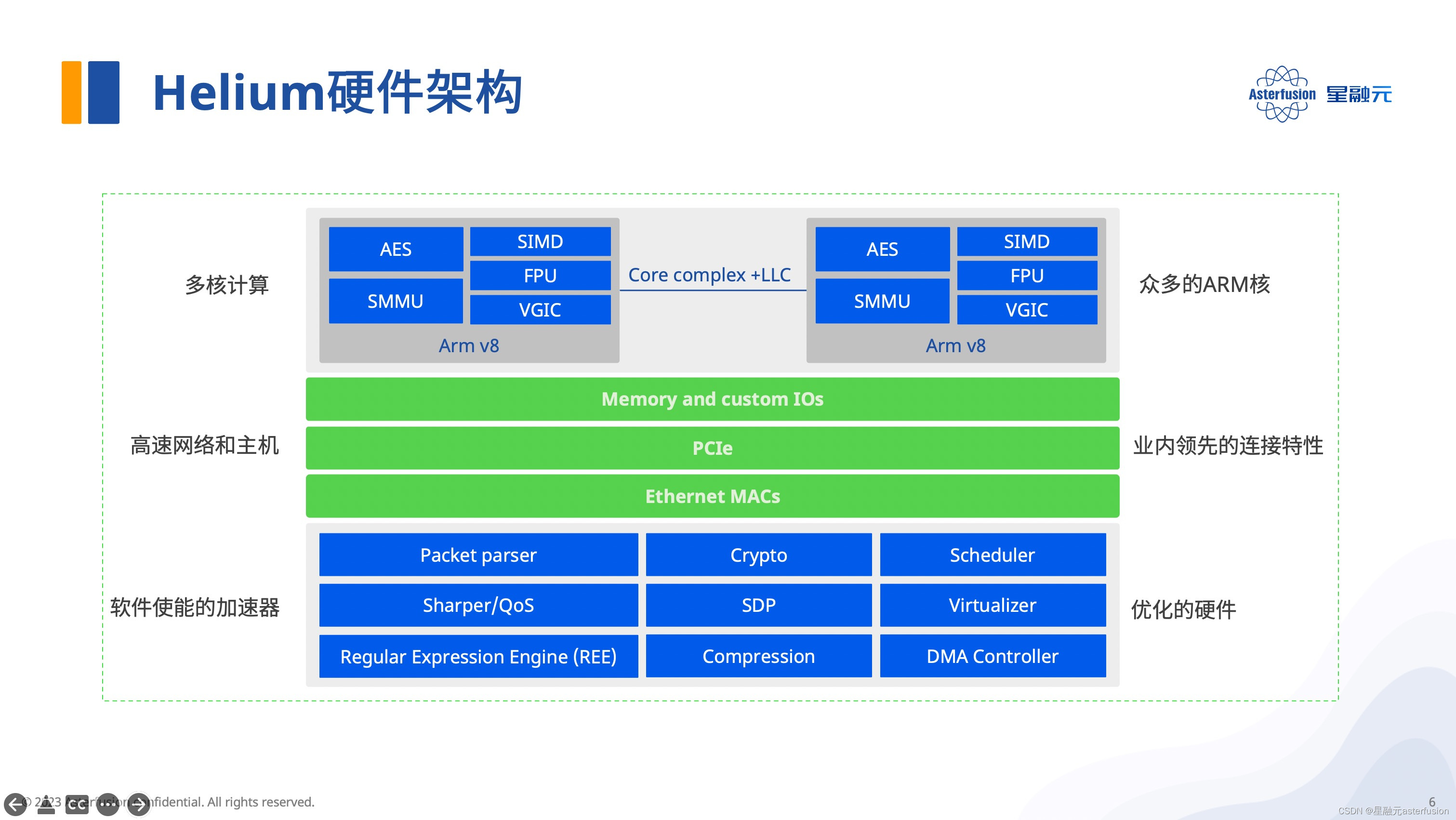
Helium DPU卡的硬件架构
我们可以结合下图来了解Helium的硬件架构,整个DPU卡是由24个ARM核和一些用于网络处理的重要硬件模块组成的。因公开课时间有限,张敏重点介绍了用于流量解析和分类的Network Parser和用于流量调度的Scheduler模块。
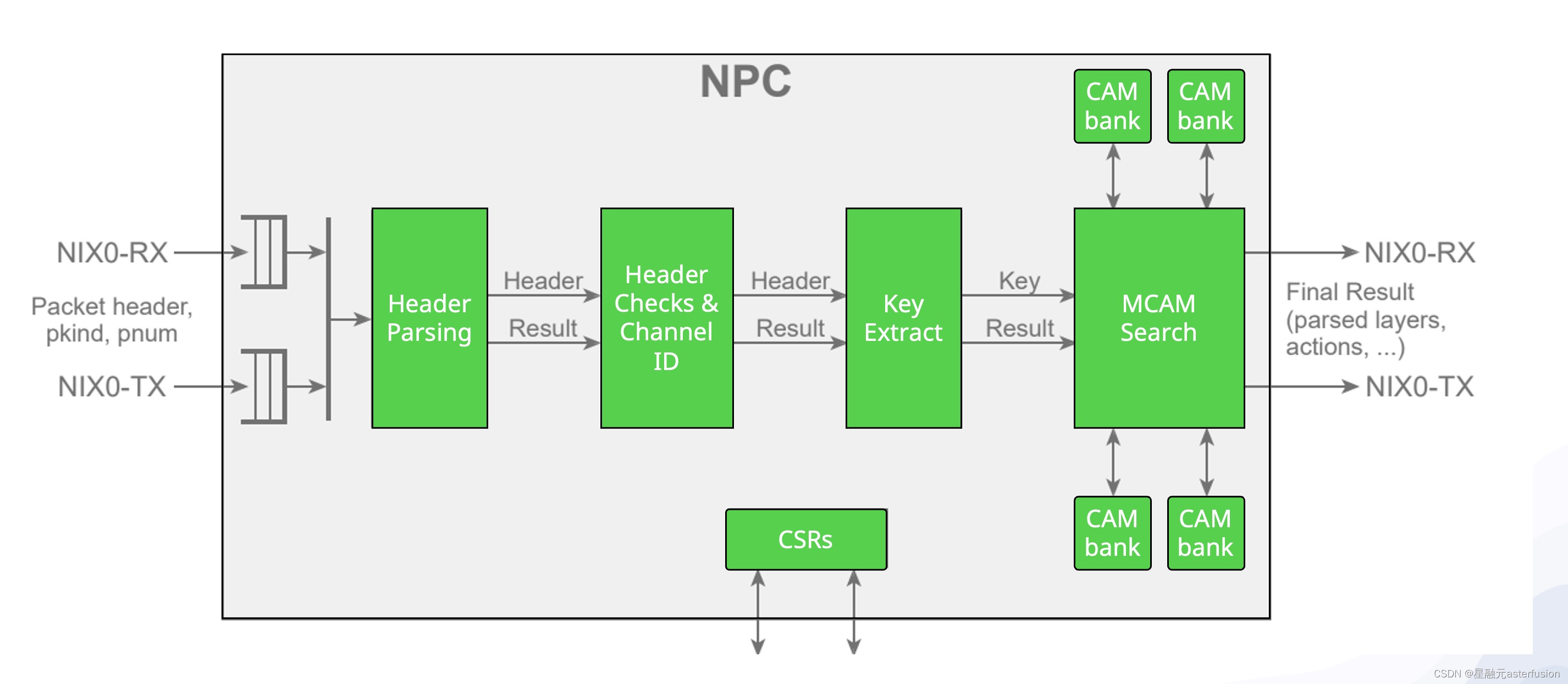
Network Parser主要实现自定义报文的快速解析和对内层复杂报文的深度解析(参考下图),而Scheduler模块的报文调度处理能力,可以将接收到的报文分配到不同的工作队列,对应到DPDK里,即是将报文分配到不同的RX queues与各个核心绑定。
 值得一提的是,Scheduler可以支持将一条五元组相同流的不同报文分发到多个核心,这种特性十分适合应对数据中心常见的"大象流"和"老鼠流"问题——在网络突发大流量情况下,"大象流"的数据仍然可以负载均衡到多核心处理,由此避免了因单核处理导致的性能瓶颈,以及"老鼠流"的丢包现象。
值得一提的是,Scheduler可以支持将一条五元组相同流的不同报文分发到多个核心,这种特性十分适合应对数据中心常见的"大象流"和"老鼠流"问题——在网络突发大流量情况下,"大象流"的数据仍然可以负载均衡到多核心处理,由此避免了因单核处理导致的性能瓶颈,以及"老鼠流"的丢包现象。
此外,Helium DPU 还有用于DPI(深度报文检测)和加速虚拟化管理的模块等等,感兴趣的读者可自行前往产品的开源页面查看。
开源地址:https://github.com/asterfusion/Helium_DPU
一站式的综合开发环境,FusionNOS-Framework
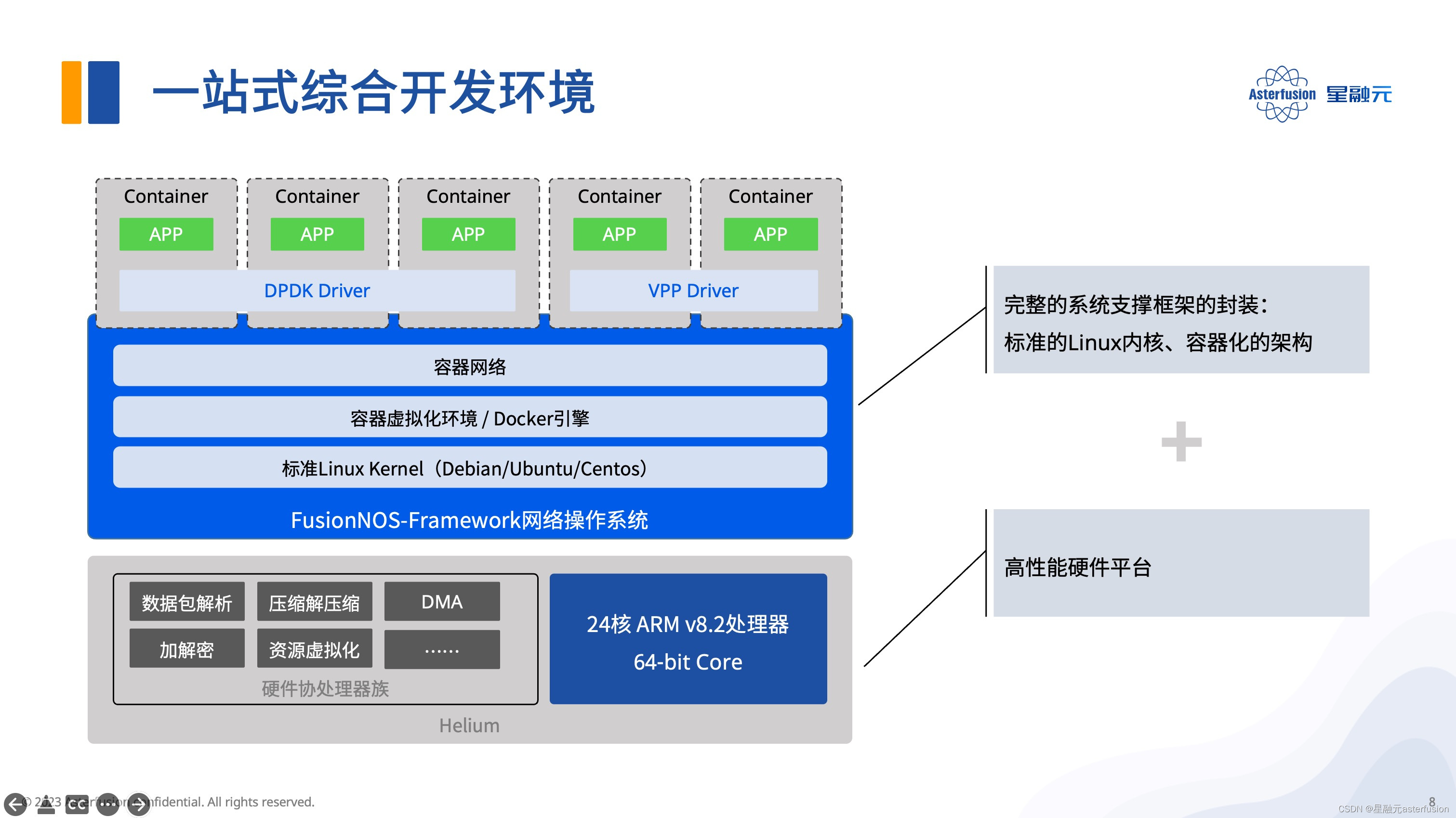
Helium 所提供的软件开发套件(FusionNOS-Framework)包括三大部分。
- 标准的Linux内核,方便开发者安装应用相关的各种依赖,并且有大量可选的软件源。
- 容器化的架构。我们可以打包运行环境和依赖到一个可移植的镜像中,实现轻量的资源隔离,做到一次编译,随处运行,并且每个实例的初始状态皆是一致的。
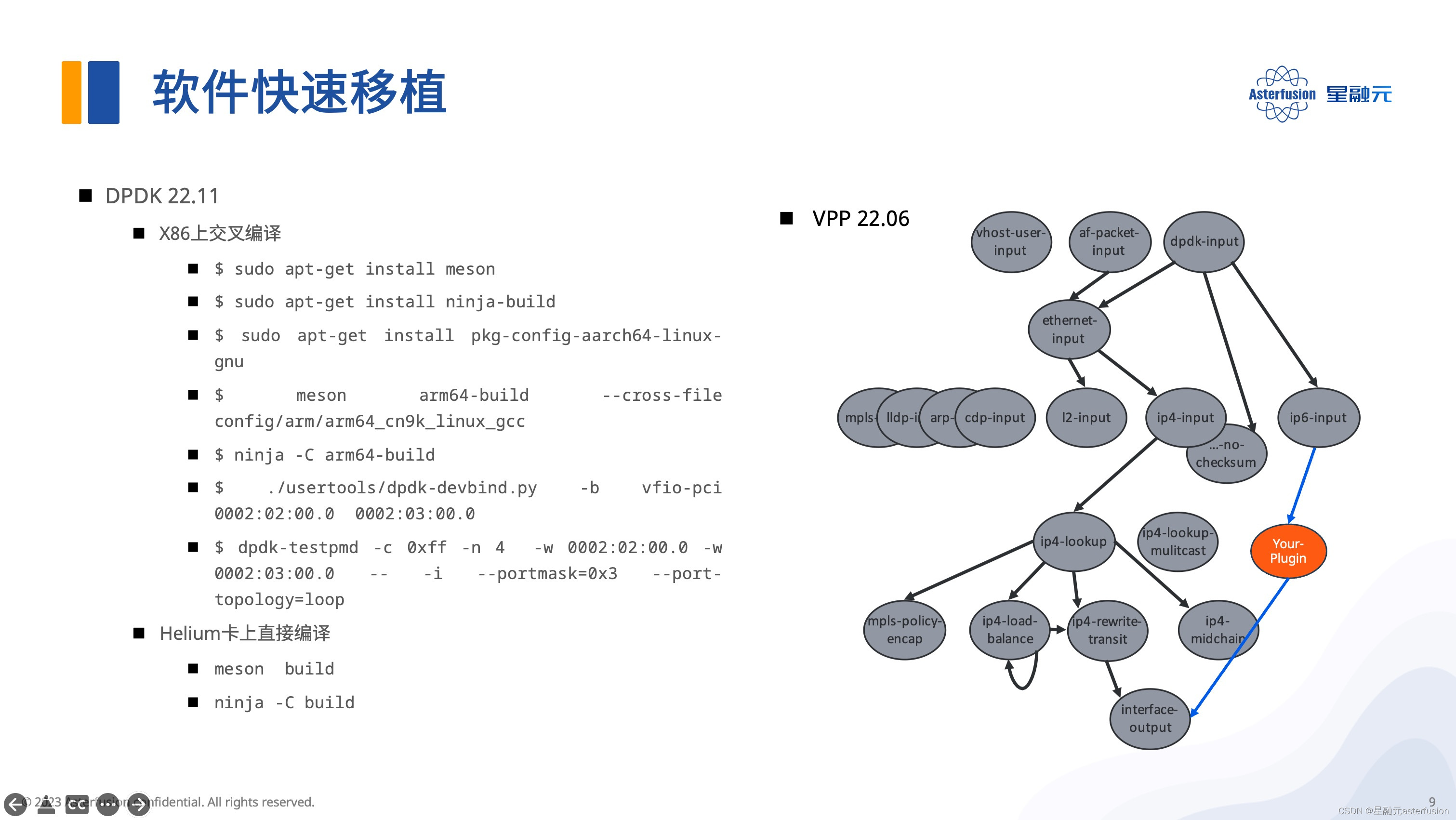
- 额外提供的DPDK和VPP开发套件,加速软件快速移植,用户也可以很方便去拓展自己的应用。
DPDK开发套件
目前星融元DPU开发团队上传在Github的是DPDK 22.11版本,它既可以在x86平台上交叉编译,也可以直接在DPU卡上编译;编译完成,只需配置大页内存并绑定接口,启动DPDK应用程序后即可开始收发包处理。
22.11以后的版本已支持P4 DPDK,这意味着Helium上完全可以运行P4程序,让交换机的流水线在DPU上跑起来。
VPP开发套件
VPP开发套件主要有以下三大特性:
- 矢量运算:单个指令,多个数据并行处理
- plugins机制:支持启动时动态加载自己开发的plugins
- node机制:支持图形化展示各个节点的处理关系
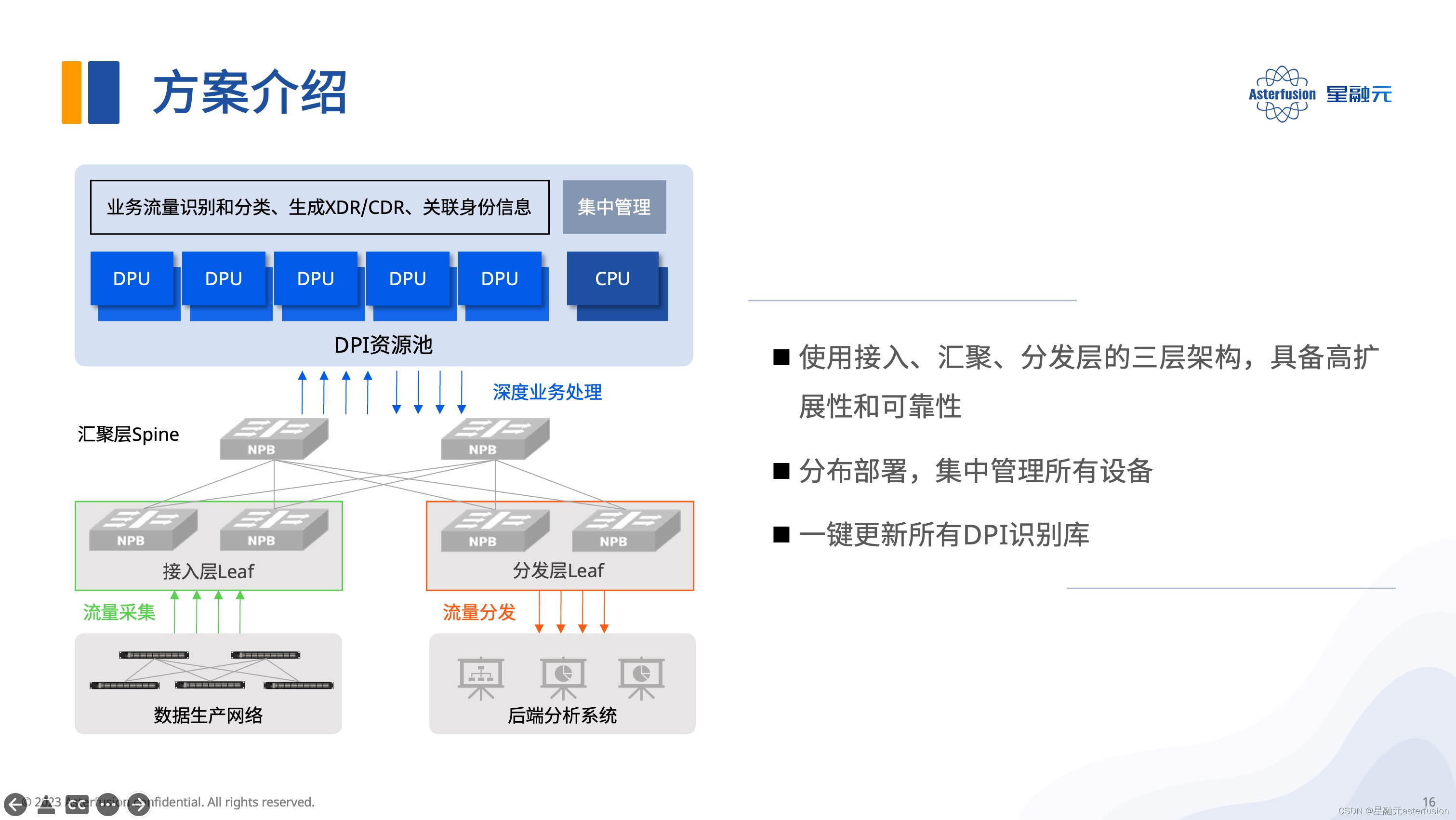
基于DPU池化方案的典型应用场景
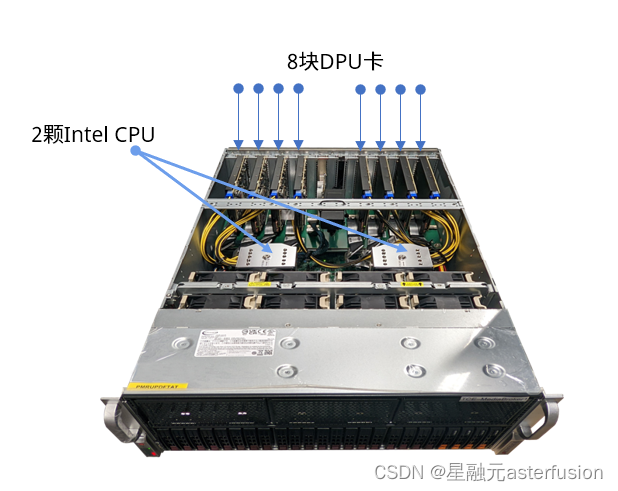
星融元DPU的算力池方案的核心思想是采用标准服务器+多块Helium DPU卡的形式,将原本独立部署在各个服务器的网络功能池化到各块DPU卡上,进而实现优化资源分配,简化运维管理的目标。
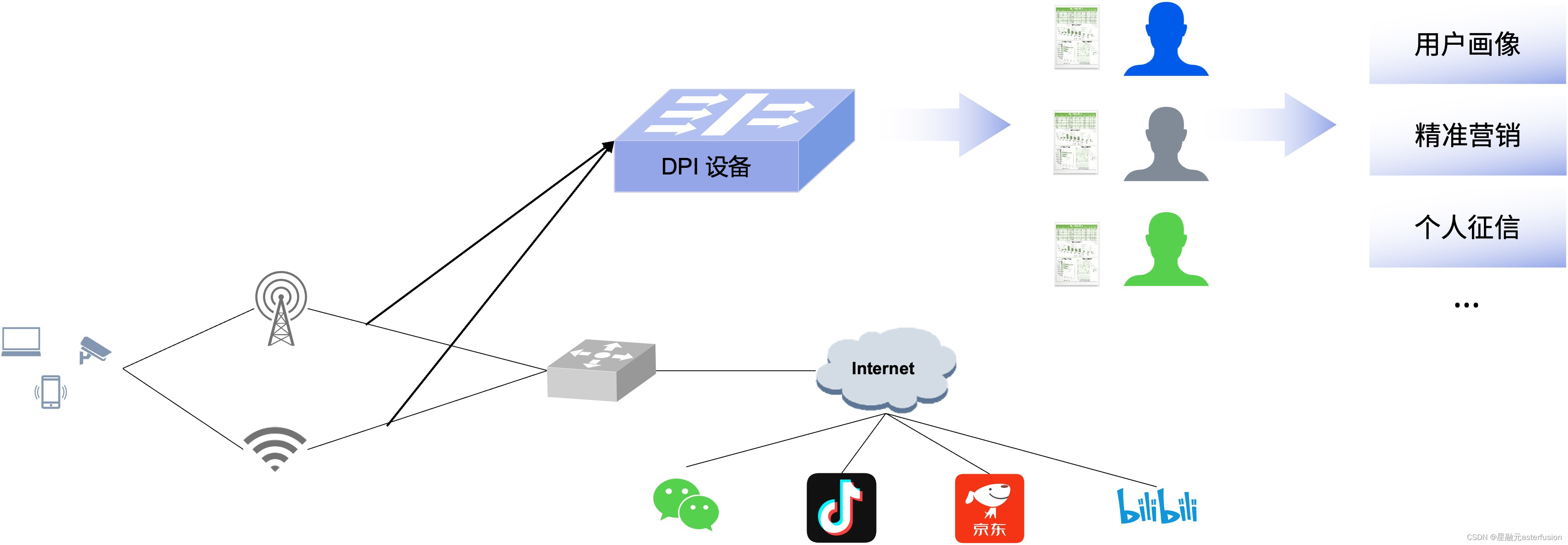
以DPI(深度报文检测)为例,通过Helium DPU资源池可以加速对业务报文的深度解析,识别出不同类型的流(视频、音频、网页流…);借助复杂的特征提取和匹配模块,这种分类可以精确到具体的应用类型(比如某平台的视频流等等)。该方案支持分布部署、集中管理,一键更新所有DPI识别库。
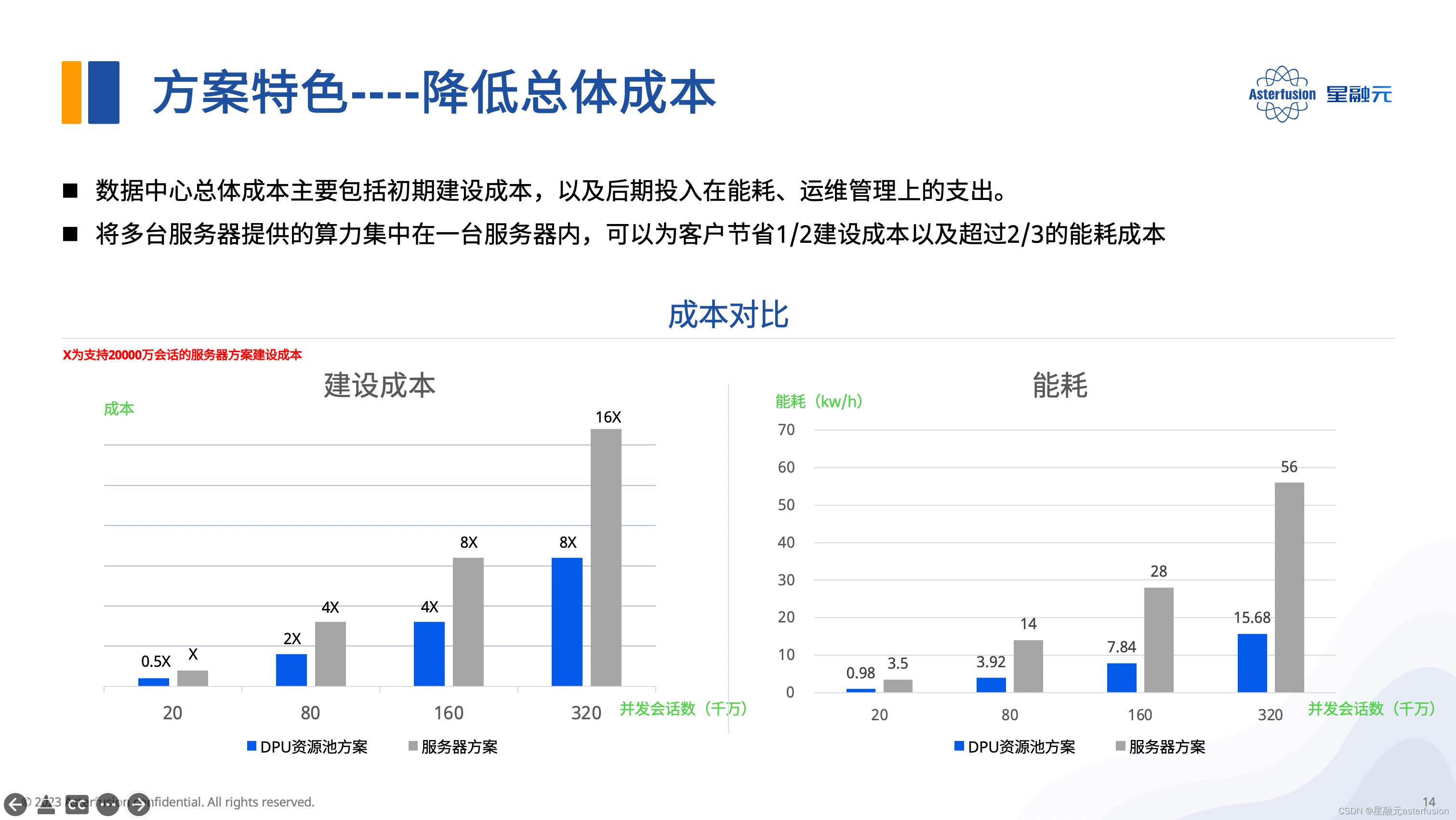
到了边缘云场景,DPU池化方案亦可帮助节约机架空间,便于机房电源管理,降低机房建设和能耗成本超50%。
关注vx公号“星融元Asterfusion”,获取更多技术分享和最新产品动态

















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









