







内版本核:4.1.15
开发板:正点原子imx6ull开发板
参考资料:
深入理解linux网络 ---张彦飞
I.MX6U嵌入式Linux驱动开发指南1.7
目录
1. 内核收包前的准备工作
1.1 创建ksoftirqd线程
// linux_4.1.15/kernel/softirq.c
/* 创建softirqd线程 */
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",
};
/* 系统初始化的时候会调用该函数创建ksoftirqd线程,ksoftirqd线程被创建出来后会执行自己的线程 *
* 循环函数ksoftirqd_should_run和run_ksoftirqd,在ksoftirqd_should_run中判断是否有pending *
* 的软中断,如果有就执行run_ksoftirqd,后者调用_do_softirq工作 */
static __init int spawn_ksoftirqd(void)
{
register_cpu_notifier(&cpu_nfb);
BUG_ON(smpboot_register_percpu_thread(&softirq_threads));
return 0;
}
early_initcall(spawn_ksoftirqd);当ksoftirqd创建出来之后,它就会进入自己的线程循环函数ksoftirqd_should_run。
1.2 注册好各协议对应的处理函数
Linux内核会通过调用subsys_initcall函数来初始化各个子系统;
// net/core/dev.c
static int __init net_dev_init(void)
{
int i, rc = -ENOMEM;
// 通过宏BUG_ON检查dev_boot_phase是否为真,如果为假,意味着不符合预期的启动阶段,触发内核bug
BUG_ON(!dev_boot_phase);
// 对proc文件系统相关初始化
if (dev_proc_init())
goto out;
// 对网络设备kobject初始化
if (netdev_kobject_init())
goto out;
// 对网络协议类型相关链表头进行初始化,这些链表通常用于管理网络协议相关的数据和操作
// ptype_base:
INIT_LIST_HEAD(&ptype_all);
for (i = 0; i < PTYPE_HASH_SIZE; i++)
INIT_LIST_HEAD(&ptype_base[i]);
INIT_LIST_HEAD(&offload_base);
// 注册网络命令空间的子系统操作,用于在网络命令空间层面进行特定的管理和操作
if (register_pernet_subsys(&netdev_net_ops))
goto out;
/*
* Initialise the packet receive queues.
*/
for_each_possible_cpu(i)
{
/* 为每个cpu申请softnet_data数据结构,*/
struct softnet_data *sd = &per_cpu(softnet_data, i);
/* 初始化softnet_data结构用于存放数据数据包队列,处理队列的队列头,以及轮询链表头 */
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
INIT_LIST_HEAD(&sd->poll_list);
// 设置输出队列的尾指针指向输出队列
sd->output_queue_tailp = &sd->output_queue;
#ifdef CONFIG_RPS //该配置用于接收数据包分流相关配置
sd->csd.func = rps_trigger_softirq;
sd->csd.info = sd;
sd->cpu = i;
#endif
// 配置backlog相关的轮询函数和权重等属性,backlog机制通常用于在网络接收处理繁重时暂存数据包
sd->backlog.poll = process_backlog;
sd->backlog.weight = weight_p;
}
dev_boot_phase = 0;
/* The loopback device is special if any other network devices
* is present in a network namespace the loopback device must
* be present. Since we now dynamically allocate and free the
* loopback device ensure this invariant is maintained by
* keeping the loopback device as the first device on the
* list of network devices. Ensuring the loopback devices
* is the first device that appears and the last network device
* that disappears.
* 环回设备是特殊的,如果网络命名空间中存在任何其他网络设备,则必须存在环回设备。
* 由于我们现在动态地分配和释放了环回设备,因此通过将环回设备作为网络设备列表中的
* 第一个设备来确保维护这个不变性。确保环回设备是第一个出现的设备,最后一个消失的
* 网络设备。
* loopback_net_ops定义在drivers/net/loopback.c文件中,应该就是创建ifconfig中
* 的lo设备;
*/
if (register_pernet_device(&loopback_net_ops))
goto out;
if (register_pernet_device(&default_device_ops))
goto out;
/* 注册接收和发送的软中断函数,分别为net_tx_action和net_rx_action函数,完成网络数据包的发送和接收 */
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
// 注册cpu相关的热插拔等通知回调函数,以便在内核感知到cpu状态变化时能够进行相应的处理
hotcpu_notifier(dev_cpu_callback, 0);
dst_init();
rc = 0;
out:
return rc;
}
subsys_initcall(net_dev_init);在这段代码里面,会为每个cpu申请一个softnet_data数据结构,这个数据结构里面的poll_list用于等待驱动程序把poll函数注册进来。
// include/linux/netdevice.h
struct softnet_data {
/* poll_list变量很重要,每当收到数据包时网络设备驱动会把自己的的napi_struct *
* 挂到softnet_data->poll_list上,这样软中断时net_rx_action会遍历cpu私有 *
* 变量softnet_data->poll_list,执行上面所挂的napi_struct结构的poll钩子函数 *
* 将数据包从驱动传到网络协议栈中 */
struct list_head poll_list;
}
for_each_possible_cpu(i)
{
/* 为每个cpu申请softnet_data数据结构,*/
struct softnet_data *sd = &per_cpu(softnet_data, i);
/* 初始化softnet_data结构用于存放数据数据包队列,处理队列的队列头,以及轮询链表头 */
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
INIT_LIST_HEAD(&sd->poll_list);
// 设置输出队列的尾指针指向输出队列
sd->output_queue_tailp = &sd->output_queue;
#ifdef CONFIG_RPS //该配置用于接收数据包分流相关配置
sd->csd.func = rps_trigger_softirq;
sd->csd.info = sd;
sd->cpu = i;
#endif
// 配置backlog相关的轮询函数和权重等属性,backlog机制通常用于在网络接收处理繁重时暂存数据包
sd->backlog.poll = process_backlog;
sd->backlog.weight = weight_p;
}open_softirq为每一个软中断都注册一个处理函数,注册的软中断函数都记录到全局变量softirq_vec中,后面ksoftirq线程收到软中断的时候,会在这个变量中找到对应的软中断处理函数。
// kernel/softirq.c
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
softirq_vec[nr].action = action;
}
/* 内核为软中断创建了一个全局数组,softirq_vec相当于一个向量数组,根据数组下标 *
* 就可以找到对应的action回调函数;
* include/linux/interrupt.h
*/
struct softirq_action
{
void (*action)(struct softirq_action *);
};
// kernel/softirq.c
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;接下来看注册协议函数部分。
内核通过fs_initcall(inet_init)来注册网络协议函数,通过inet_init将这些函数注册到inet_protos和ptype_base里面。
inet_init函数是linux内核网络协议栈中internet协议族初始化的核心函数,它在系统启动阶段执行众多关键操作,涵盖传输层协议(tcp udp等)的注册、网络层协议(icmp igmp等)的注册与初始化、各种协议相关的数据结构及功能模块(协议切换表 ARP IP模块 内存管理模块等)的初始化工作,旨在构建起完整且正常运行的internet协议网络环境,为网络通信奠定基础。
代码如下:
// net/ipv4/af_inet.c
static int __init inet_init(void)
{
struct inet_protosw *q;
struct list_head *r;
int rc = -EINVAL;
// 该函数用于检查struct inet_skb_parm结构体大小是否符合预期,确保后续的数据包处理中涉及该结构体的相关操作不会因为大小问题出现内存越界等错误;
sock_skb_cb_check_size(sizeof(struct inet_skb_parm));
/* tcp_prot定义在linux_4.1.15\net\ipv4\tcp_ipv4.c文件中,
*
* struct proto tcp_prot = {
* .name = "TCP",
* .owner = THIS_MODULE,
* .close = tcp_close,
* .connect = tcp_v4_connect,
* .disconnect = tcp_disconnect,
* .accept = inet_csk_accept,
* .ioctl = tcp_ioctl,
* .init = tcp_v4_init_sock,
* .destroy = tcp_v4_destroy_sock,
* .shutdown = tcp_shutdown,
* .setsockopt = tcp_setsockopt,
* .getsockopt = tcp_getsockopt,
* .recvmsg = tcp_recvmsg,
* .sendmsg = tcp_sendmsg,
* .sendpage = tcp_sendpage,
* .backlog_rcv = tcp_v4_do_rcv,
* .release_cb = tcp_release_cb,
* .hash = inet_hash,
* .unhash = inet_unhash,
* .get_port = inet_csk_get_port,
* .enter_memory_pressure = tcp_enter_memory_pressure,
* .stream_memory_free = tcp_stream_memory_free,
* .sockets_allocated = &tcp_sockets_allocated,
* .orphan_count = &tcp_orphan_count,
* .memory_allocated = &tcp_memory_allocated,
* .memory_pressure = &tcp_memory_pressure,
* .sysctl_mem = sysctl_tcp_mem,
* .sysctl_wmem = sysctl_tcp_wmem,
* .sysctl_rmem = sysctl_tcp_rmem,
* .max_header = MAX_TCP_HEADER,
* .obj_size = sizeof(struct tcp_sock),
* .slab_flags = SLAB_DESTROY_BY_RCU,
* .twsk_prot = &tcp_timewait_sock_ops,
* .rsk_prot = &tcp_request_sock_ops,
* .h.hashinfo = &tcp_hashinfo,
* .no_autobind = true,
* #ifdef CONFIG_COMPAT
* .compat_setsockopt = compat_tcp_setsockopt,
* .compat_getsockopt = compat_tcp_getsockopt,
* #endif
* #ifdef CONFIG_MEMCG_KMEM
* .init_cgroup = tcp_init_cgroup,
* .destroy_cgroup = tcp_destroy_cgroup,
* .proto_cgroup = tcp_proto_cgroup,
* #endif
* };
*/
/* tcp 协议注册(传输层) 注册传输层tcp协议,tcp协议是一个定义好的struct proto结构体;
其中包含众多TCP协议操作相关的函数指针(如发送 接收 连接 关闭等),以及相关属性(内存相关 协议相关的哈希表等信息)
*/
rc = proto_register(&tcp_prot, 1);
if (rc)
goto out;
/*
* udp_prot定义在linux_4.1.15\net\ipv4\udp.c文件中
* struct proto udp_prot = {
* .name = "UDP",
* .owner = THIS_MODULE,
* .close = udp_lib_close,
* .connect = ip4_datagram_connect,
* .disconnect = udp_disconnect,
* .ioctl = udp_ioctl,
* .destroy = udp_destroy_sock,
* .setsockopt = udp_setsockopt,
* .getsockopt = udp_getsockopt,
* .sendmsg = udp_sendmsg,
* .recvmsg = udp_recvmsg,
* .sendpage = udp_sendpage,
* .backlog_rcv = __udp_queue_rcv_skb,
* .release_cb = ip4_datagram_release_cb,
* .hash = udp_lib_hash,
* .unhash = udp_lib_unhash,
* .rehash = udp_v4_rehash,
* .get_port = udp_v4_get_port,
* .memory_allocated = &udp_memory_allocated,
* .sysctl_mem = sysctl_udp_mem,
* .sysctl_wmem = &sysctl_udp_wmem_min,
* .sysctl_rmem = &sysctl_udp_rmem_min,
* .obj_size = sizeof(struct udp_sock),
* .slab_flags = SLAB_DESTROY_BY_RCU,
* .h.udp_table = &udp_table,
* #ifdef CONFIG_COMPAT
* .compat_setsockopt = compat_udp_setsockopt,
* .compat_getsockopt = compat_udp_getsockopt,
* #endif
* .clear_sk = sk_prot_clear_portaddr_nulls,
* };
*/
// 注册UDP协议
rc = proto_register(&udp_prot, 1);
if (rc)
goto out_unregister_tcp_proto;
rc = proto_register(&raw_prot, 1);
if (rc)
goto out_unregister_udp_proto;
// 对ping协议进行注册
rc = proto_register(&ping_prot, 1);
if (rc)
goto out_unregister_raw_proto;
/*
* Tell SOCKET that we are alive...
* socket套接字协议簇注册,将协议簇添加到net_families中
注册inet_family_ops,该协议族(IPV4相关)的套接字操作
*/
(void)sock_register(&inet_family_ops);
// 如果开启CONFIG_SYSCTL,将可以通过proc接口动态调整网络相关配置
#ifdef CONFIG_SYSCTL
ip_static_sysctl_init();
#endif
/* 上面是网络层协议函数注册,下面是传输层协议注册 */
/*
* Add all the base protocols.
*/
/* 注册icmp协议 IPPROTO_ICMP是对应的协议号 */
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
/* 注册udp协议 */
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
/* 注册tcp协议 */
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
// 如果支持多播,则注册IGMP
#ifdef CONFIG_IP_MULTICAST
if (inet_add_protocol(&igmp_protocol, IPPROTO_IGMP) < 0)
pr_crit("%s: Cannot add IGMP protocol\n", __func__);
#endif
/* Register the socket-side information for inet_create. */
/* 初始化inet switch链表, inetsw链表用于在不同套接字类型下切换不同的协议实现 */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
/* 注册协议切换表到全局变量inetsw中 调用inet_register_protosw将这些协议切换相关信息注册到全局变量
inetsw中,构建完整的协议切换体系,便于根据不同的条件进行协议相关操作的切换和调用 */
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
/*
* Set the ARP module up
对地址解析协议ARP模块进行初始化,ARP协议主要用于将IP解析为对应的MAC地址,初始化操作会
设置好相关的数据结构,缓存机制,保障网络通信中的IP地址与物理地址的映射功能正常运行
*/
arp_init();
/*
* Set the IP module up
* ip层初始化,主要是路由器模块,包括路由表的初始化 IP数据包转发相关规则和数据结构的搭建等
确保网络层能够正确的处理和转发IP数据包
*/
ip_init();
/* tcp相关初始化 */
tcp_v4_init();
/* Setup TCP slab cache for open requests. */
tcp_init();
/* Setup UDP memory threshold udp相关初始化
涉及UDP协议的内存管理 端口配置等相关机制的初始化工作,确保UDP协议能正常处理发送和接收数据报等
*/
udp_init();
/* Add UDP-Lite (RFC 3828) */
/* 使其能够在内核中被识别和处理,用于满足特定的轻量级UDP通信场景需求 */
udplite4_register();
/* icmp初始化 */
/* 设置ping协议相关操作函数,使得能够通过ping命令等方式进行网络连通性测试 */
ping_init();
/*
* Set the ICMP layer up
ICMP控制套接字对于网络管理 错误反馈等功能非常重要
*/
if (icmp_init() < 0)
panic("Failed to create the ICMP control socket.\n");
/*
* Initialise the multicast router
CONFIG_IP_MROUTE:IP多播路由功能
多播路由对于实现网络中的多播数据转发功能至关重要
*/
#if defined(CONFIG_IP_MROUTE)
if (ip_mr_init())
pr_crit("%s: Cannot init ipv4 mroute\n", __func__);
#endif
// 初始化internet协议族,这些操作对于在不同网络命名空间下正确处理Internet协议族的通信很重要
if (init_inet_pernet_ops())
pr_crit("%s: Cannot init ipv4 inet pernet ops\n", __func__);
/*
* Initialise per-cpu ipv4 mibs
* mibs初始化
mibs:IPV4的信息管理库,MIBS通常用于统计网络相关的各种指标(如收发包数量 错误数量等)
*/
if (init_ipv4_mibs())
pr_crit("%s: Cannot init ipv4 mibs\n", __func__);
/* proc文件系统初始化,通过proc文件系统可以方便的查看和调整IPV4网络相关的一些参数、状态等
初始化操作会创建对应的文件节点等内容
*/
ipv4_proc_init();
/* ip碎片,在网络传输过程中,IP数据包会过大需要分片传输时,该机制能正确的处理分片组装、缓存
超时等管理工作,保障数据的完整性和正确性。
*/
ipfrag_init();
/* 注册ip_rcv函数,ip_packet_type涉及具体协议的入口
注册ip_packet_type相关处理函数,使得网络设备在接收IP数据报时能够找到对应的处理入口,进入内核协议栈
中正确的处理流程进行后续的解包 路由 转发等操作。
*/
dev_add_pack(&ip_packet_type);
rc = 0;
out:
return rc;
out_unregister_raw_proto:
proto_unregister(&raw_prot);
out_unregister_udp_proto:
proto_unregister(&udp_prot);
out_unregister_tcp_proto:
proto_unregister(&tcp_prot);
goto out;
}
/* 网络协议栈初始化的入口,该宏和module_init函数功能一样,*
* 就是给内核添加一个功能函数 */
fs_initcall(inet_init);proto_register函数将网络层协议函数添加到proto_list链表中,inet_add_protocol函数将传输层协议(tcp、udp等)注册到inet_protos链表中。
软中断会通过proto_list找到ip_rcv函数地址,进而将IP数据包正确的送到ip_rcv函数中处理,ip_rcv函数中通过inet_protos找到TCP或者UDP的处理函数,再将包转发给udp_rcv或者tcp_v4_rcv函数。
1.3 初始化网卡并启动
下面是正点原子IMX6ULL开发板网卡驱动部分。首先,根据设备树中的compatiable属性找到对应的驱动文件为drivers/net/ethernet/freescale/fec_main.c
fec2: ethernet@020b4000 {
compatible = "fsl,imx6ul-fec", "fsl,imx6q-fec";
...
}
// drivers/net/ethernet/freescale/fec_main.c
static const struct of_device_id fec_dt_ids[] = {
{ .compatible = "fsl,imx25-fec", .data = &fec_devtype[IMX25_FEC], },
{ .compatible = "fsl,imx27-fec", .data = &fec_devtype[IMX27_FEC], },
{ .compatible = "fsl,imx28-fec", .data = &fec_devtype[IMX28_FEC], },
{ .compatible = "fsl,imx6q-fec", .data = &fec_devtype[IMX6Q_FEC], },
{ .compatible = "fsl,mvf600-fec", .data = &fec_devtype[MVF600_FEC], },
{ .compatible = "fsl,imx6sx-fec", .data = &fec_devtype[IMX6SX_FEC], },
{ .compatible = "fsl,imx6ul-fec", .data = &fec_devtype[IMX6UL_FEC], },
{ /* sentinel */ }
};
static struct platform_driver fec_driver = {
.driver = {
.name = DRIVER_NAME,
.pm = &fec_pm_ops,
.of_match_table = fec_dt_ids,
},
.id_table = fec_devtype,
.probe = fec_probe,
.remove = fec_drv_remove,
};根据设备树中的fsl,imx6ul-fec,匹配到驱动为,然后执行fec_probe函数。
// drivers/net/ethernet/freescale/fec_main.c
static int fec_probe(struct platform_device *pdev)
{
struct fec_enet_private *fep;
struct fec_platform_data *pdata;
struct net_device *ndev;
int i, irq, ret = 0;
struct resource *r;
const struct of_device_id *of_id;
static int dev_id;
struct device_node *np = pdev->dev.of_node, *phy_node;
int num_tx_qs;
int num_rx_qs;
/* 设置 MX6UL_PAD_ENET1_TX_CLK 和 MX6UL_PAD_ENET2_TX_CLK
* 这两个 IO 的复用寄存器的 SION 位为 1
*/
void __iomem *IMX6U_ENET1_TX_CLK;
void __iomem *IMX6U_ENET2_TX_CLK;
IMX6U_ENET1_TX_CLK = ioremap(0X020E00DC, 4);
writel(0X14, IMX6U_ENET1_TX_CLK);
IMX6U_ENET2_TX_CLK = ioremap(0X020E00FC, 4);
writel(0X14, IMX6U_ENET2_TX_CLK);
/*==========================================*/
/* 从设备树获取fsl,num-tx-queues和fsl,num-rx-queues的属性值 *
* 这两个值也就是发送队列和接收队列的大小,设备树中这两个属性都配置的1;
*/
fec_enet_get_queue_num(pdev, &num_tx_qs, &num_rx_qs);
/* Init network device 申请net_device(很重要的数据结构) */
ndev = alloc_etherdev_mqs(sizeof(struct fec_enet_private), num_tx_qs, num_rx_qs);
if (!ndev)
return -ENOMEM;
SET_NETDEV_DEV(ndev, &pdev->dev);
/* setup board info structure 获取私有数据空间首地址 */
fep = netdev_priv(ndev);
of_id = of_match_device(fec_dt_ids, &pdev->dev);
if (of_id)
pdev->id_entry = of_id->data;
fep->quirks = pdev->id_entry->driver_data;
fep->netdev = ndev;
fep->num_rx_queues = num_rx_qs;
fep->num_tx_queues = num_tx_qs;
#if !defined(CONFIG_M5272)
/* default enable pause frame auto negotiation */
if (fep->quirks & FEC_QUIRK_HAS_GBIT)
fep->pause_flag |= FEC_PAUSE_FLAG_AUTONEG;
#endif
/* Select default pin state */
pinctrl_pm_select_default_state(&pdev->dev);
/* 做虚拟地址转换 */
r = platform_get_resource(pdev, IORESOURCE_MEM, 0);
/* 将转换后的ENET虚拟地址起始地址保存到hwp成员中 */
/* hwp: Hardware registers of the FEC device */
fep->hwp = devm_ioremap_resource(&pdev->dev, r);
if (IS_ERR(fep->hwp)) {
ret = PTR_ERR(fep->hwp);
goto failed_ioremap;
}
fep->pdev = pdev;
fep->dev_id = dev_id++;
platform_set_drvdata(pdev, ndev);
/* 解析设备树中关于ENET的停止模式属性值 stop-mode = <&gpr 0x10 4>;*/
fec_enet_of_parse_stop_mode(pdev);
/* 解析是否支持魔术包 */
if (of_get_property(np, "fsl,magic-packet", NULL))
fep->wol_flag |= FEC_WOL_HAS_MAGIC_PACKET;
/* 获取phy_handle属性,phy_handle属性指定了网络外设所对应获取PHY的设备节点;phy-handle = <ðphy1>; */
phy_node = of_parse_phandle(np, "phy-handle", 0);
if (!phy_node && of_phy_is_fixed_link(np))
{
ret = of_phy_register_fixed_link(np);
if (ret < 0)
{
dev_err(&pdev->dev,
"broken fixed-link specification\n");
goto failed_phy;
}
phy_node = of_node_get(np);
}
fep->phy_node = phy_node;
/* 获取设备树中的 phy-mode = "rmii"; */
ret = of_get_phy_mode(pdev->dev.of_node);
if (ret < 0)
{
pdata = dev_get_platdata(&pdev->dev);
if (pdata)
fep->phy_interface = pdata->phy;
else
fep->phy_interface = PHY_INTERFACE_MODE_MII;
}
else
{
fep->phy_interface = ret;
}
fep->clk_ipg = devm_clk_get(&pdev->dev, "ipg");
if (IS_ERR(fep->clk_ipg)) {
ret = PTR_ERR(fep->clk_ipg);
goto failed_clk;
}
fep->clk_ahb = devm_clk_get(&pdev->dev, "ahb");
if (IS_ERR(fep->clk_ahb)) {
ret = PTR_ERR(fep->clk_ahb);
goto failed_clk;
}
fep->itr_clk_rate = clk_get_rate(fep->clk_ahb);
/* enet_out is optional, depends on board */
fep->clk_enet_out = devm_clk_get(&pdev->dev, "enet_out");
if (IS_ERR(fep->clk_enet_out))
fep->clk_enet_out = NULL;
fep->ptp_clk_on = false;
mutex_init(&fep->ptp_clk_mutex);
/* clk_ref is optional, depends on board */
fep->clk_ref = devm_clk_get(&pdev->dev, "enet_clk_ref");
if (IS_ERR(fep->clk_ref))
fep->clk_ref = NULL;
fep->bufdesc_ex = fep->quirks & FEC_QUIRK_HAS_BUFDESC_EX;
fep->clk_ptp = devm_clk_get(&pdev->dev, "ptp");
if (IS_ERR(fep->clk_ptp)) {
fep->clk_ptp = NULL;
fep->bufdesc_ex = false;
}
// 电源管理,并使能以太网时钟
pm_runtime_enable(&pdev->dev);
ret = fec_enet_clk_enable(ndev, true);
if (ret)
goto failed_clk;
fep->reg_phy = devm_regulator_get(&pdev->dev, "phy");
if (!IS_ERR(fep->reg_phy)) {
ret = regulator_enable(fep->reg_phy);
if (ret) {
dev_err(&pdev->dev,
"Failed to enable phy regulator: %d\n", ret);
goto failed_regulator;
}
} else {
fep->reg_phy = NULL;
}
/* 复位phy */
fec_reset_phy(pdev);
if (fep->bufdesc_ex)
fec_ptp_init(pdev);
/* 申请队列和DMA,设置MAC地址,初始化NAPI机制 */
ret = fec_enet_init(ndev);
if (ret)
goto failed_init;
for (i = 0; i < FEC_IRQ_NUM; i++)
{
/* 从设备树中获取中断号 */
irq = platform_get_irq(pdev, i);
if (irq < 0)
{
if (i)
break;
ret = irq;
goto failed_irq;
}
/* 申请中断,中断处理函数是fec_enet_interrupt */
ret = devm_request_irq(&pdev->dev, irq, fec_enet_interrupt,
0, pdev->name, ndev);
if (ret)
goto failed_irq;
fep->irq[i] = irq;
}
/* 唤醒中断 */
ret = of_property_read_u32(np, "fsl,wakeup_irq", &irq);
if (!ret && irq < FEC_IRQ_NUM)
fep->wake_irq = fep->irq[irq];
else
fep->wake_irq = fep->irq[0];
init_completion(&fep->mdio_done);
/* 注册MDIO总线、注册phy_device
* 完成MII/RMII接口的初始化工作,读写PHY芯片的寄存器
*/
ret = fec_enet_mii_init(pdev);
if (ret)
goto failed_mii_init;
/* Carrier starts down, phylib will bring it up */
netif_carrier_off(ndev);
fec_enet_clk_enable(ndev, false); //使能网络相关时钟
pinctrl_pm_select_sleep_state(&pdev->dev);
/* 注册net_device结构体 */
ret = register_netdev(ndev);
if (ret)
goto failed_register;
device_init_wakeup(&ndev->dev, fep->wol_flag &
FEC_WOL_HAS_MAGIC_PACKET);
if (fep->bufdesc_ex && fep->ptp_clock)
netdev_info(ndev, "registered PHC device %d\n", fep->dev_id);
fep->rx_copybreak = COPYBREAK_DEFAULT;
INIT_WORK(&fep->tx_timeout_work, fec_enet_timeout_work);
return 0;
failed_register:
fec_enet_mii_remove(fep);
failed_mii_init:
failed_irq:
failed_init:
if (fep->reg_phy)
regulator_disable(fep->reg_phy);
failed_regulator:
fec_enet_clk_enable(ndev, false);
failed_clk:
failed_phy:
of_node_put(phy_node);
failed_ioremap:
free_netdev(ndev);
return ret;
}从设备树中获取fsl,num-tx-queues和fsl,num-rx-queues节点信息,这两个节点信息设备树中都配置的是1。
fec2: ethernet@020b4000 {
fsl,num-tx-queues=<1>;
fsl,num-rx-queues=<1>;
}
static void fec_enet_get_queue_num(struct platform_device *pdev, int *num_tx, int *num_rx)
{
...
/* parse the num of tx and rx queues */
err = of_property_read_u32(np, "fsl,num-tx-queues", num_tx);
if (err)
*num_tx = 1;
err = of_property_read_u32(np, "fsl,num-rx-queues", num_rx);
if (err)
*num_rx = 1;
...
}接下来申请net_device结构体,并根据入参赋值接受和发送队列长度,以及device的名字等。
// net/core/dev.c
alloc_etherdev_mqs()
-> alloc_netdev_mqs()
struct net_device *alloc_netdev_mqs(int sizeof_priv, const char *name,
unsigned char name_assign_type,
void (*setup)(struct net_device *),
unsigned int txqs, unsigned int rxqs)
{
...
alloc_size = sizeof(struct net_device);
if (sizeof_priv) {
/* ensure 32-byte alignment of private area */
alloc_size = ALIGN(alloc_size, NETDEV_ALIGN);
alloc_size += sizeof_priv;
}
p = kzalloc(alloc_size, GFP_KERNEL | __GFP_NOWARN | __GFP_REPEAT);
dev->num_tx_queues = txqs;
...
#ifdef CONFIG_SYSFS
dev->num_rx_queues = rxqs;
dev->real_num_rx_queues = rxqs;
if (netif_alloc_rx_queues(dev))
goto free_all;
#endif
strcpy(dev->name, name);
...
}接下来获取phy-handle节点信息。
&fec2 {
phy-handle = <ðphy1>;
mdio {
ethphy1: ethernet-phy@1 {
compatible = "ethernet-phy-ieee802.3-c22";
smsc,disable-energy-detect;
reg = <1>;
};
}
}
/* 获取phy_handle属性,phy_handle属性指定了网络外设所对应获取PHY的设备节点;phy-handle = <ðphy1>; */
phy_node = of_parse_phandle(np, "phy-handle", 0);
if (!phy_node && of_phy_is_fixed_link(np))
{
ret = of_phy_register_fixed_link(np);
if (ret < 0)
{
dev_err(&pdev->dev,
"broken fixed-link specification\n");
goto failed_phy;
}
phy_node = of_node_get(np);
}
fep->phy_node = phy_node; 获取phy的模式,即 PHY 是 RMII 还是 MII, IMX6ULL 中的 PHY 工作在
RMII 模式,
&fec2 {
phy-mode = "rmii";
}
/* 获取设备树中的 phy-mode = "rmii"; */
ret = of_get_phy_mode(pdev->dev.of_node);调用fec_reset_phy(pdev);复位phy。
调用fec_enet_init函数,设置MAC地址,netdev_ops和ethtool_ops等,fec_enet_init函数还会通过netif_napi_add接口注册poll接口为fec_enet_rx_napi函数。
static int fec_enet_init(struct net_device *ndev)
{
...
/* 分配发送和接收队列 */
fec_enet_alloc_queue(ndev);
...
/* Get the Ethernet address 获取并设置mac地址 */
fec_get_mac(ndev);
/* make sure MAC we just acquired is programmed into the hw */
fec_set_mac_address(ndev, NULL);
...
/* 注册netdev_ops,设置网卡驱动的netdev_ops操作集 */
ndev->netdev_ops = &fec_netdev_ops;
/* 实现ethtool所需接口 */
ndev->ethtool_ops = &fec_enet_ethtool_ops;
/* 注册NAPI机制所需的poll,兼容NAPI机制;
* fec_enet_rx_napi就是poll机制要用到的轮询接收数据函数;
* 软中断通过此函数接收数据包;
*/
netif_napi_add(ndev, &fep->napi, fec_enet_rx_napi, NAPI_POLL_WEIGHT);
...
fec_restart(ndev);
}接下来是注册中断,先获取中断号,申请中断并注册中断函数为fec_enet_interrupt。
for (i = 0; i < FEC_IRQ_NUM; i++)
{
/* 从设备树中获取中断号 */
irq = platform_get_irq(pdev, i);
if (irq < 0)
{
if (i)
break;
ret = irq;
goto failed_irq;
}
/* 申请中断,中断处理函数是fec_enet_interrupt */
ret = devm_request_irq(&pdev->dev, irq, fec_enet_interrupt,
0, pdev->name, ndev);
if (ret)
goto failed_irq;
fep->irq[i] = irq;
}
/* 唤醒中断 */
ret = of_property_read_u32(np, "fsl,wakeup_irq", &irq);调用fec_enet_mii_init函数,完成MII/RMII接口初始化,这块会注册读写phy的接口,分别为fec_enet_mdio_read和fec_enet_mdio_write函数。这两个函数也就是soc读写phy寄存器的接口。最后通过mdiobus_register函数向Linux内核注册MDIO总线。
/* 注册MDIO总线、注册phy_device
* 完成MII/RMII接口的初始化工作,读写PHY芯片的寄存器
*/
ret = fec_enet_mii_init(pdev);
if (ret)
goto failed_mii_init;
/* MII/RMII总线是用来驱动phy芯片的 */
static int fec_enet_mii_init(struct platform_device *pdev)
{
...
fep->mii_bus->name = "fec_enet_mii_bus"; // 总线名字
fep->mii_bus->read = fec_enet_mdio_read; // 总线读,是用来读phy芯片寄存器的;
fep->mii_bus->write = fec_enet_mdio_write; // 总线写,是用来写phy芯片寄存器的;
...
/* 从设备树里面获取mdio节点信息 */
node = of_get_child_by_name(pdev->dev.of_node, "mdio");
if (node)
{
/* 向linux内核注册MDIO节点 */
err = of_mdiobus_register(fep->mii_bus, node);
of_node_put(node);
}
else
{
err = mdiobus_register(fep->mii_bus);
}
}
fec_probe函数讲完了,接下来看下MDIO总线注册。
1.3.1 MDIO总线注册
Linux内核使用MDIO总线来管理Phy设备,在内核中定义了mii_bus结构体来表示。
/*
* The Bus class for PHYs. Devices which provide access to
* PHYs should register using this structure
include/linux/phy.h
*/
struct mii_bus {
const char *name; // 总线名字
char id[MII_BUS_ID_SIZE];
void *priv; // 私有数据
/* 这两个函数指针就是读写phy芯片用的 */
int (*read)(struct mii_bus *bus, int phy_id, int regnum);
int (*write)(struct mii_bus *bus, int phy_id, int regnum, u16 val);
int (*reset)(struct mii_bus *bus); // 复位
/*
* A lock to ensure that only one thing can read/write
* the MDIO bus at a time
*/
struct mutex mdio_lock;
struct device *parent; // 父设备
enum {
MDIOBUS_ALLOCATED = 1,
MDIOBUS_REGISTERED,
MDIOBUS_UNREGISTERED,
MDIOBUS_RELEASED,
} state; // 总线状态
struct device dev; // 设备文件
/* list of all PHYs on bus */
struct phy_device *phy_map[PHY_MAX_ADDR]; // PHY设备数组
/* PHY addresses to be ignored when probing */
u32 phy_mask;
/*
* Pointer to an array of interrupts, each PHY's
* interrupt at the index matching its address
*/
int *irq; // 中断
};其中read和write指针就是操作phy的操作函数,前面在分析fec_probe接口时有提到,在fec_probe接口中调用fec_enet_mii_bus接口注册这两个指针分别是fec_enet_mdio_read和fec_enet_mdio_write。
最终通过of_midobus_register或者mibus_register函数将初始化以后的mii_bus注册到Linux内核。
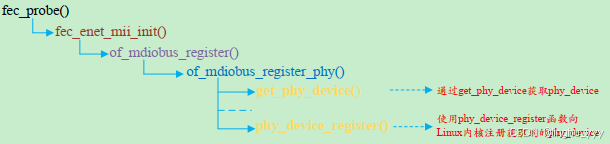
在fec_enet_init函数中会设置net_dev_ops操作集fec_netdev_ops,该结构体中包含网络的操作函数。
// drivers/net/ethernet/freescale/fec_main.c
static int fec_enet_init(struct net_device *ndev)
{
...
/* 注册netdev_ops,设置网卡驱动的netdev_ops操作集 */
ndev->netdev_ops = &fec_netdev_ops;
...
}
static const struct net_device_ops fec_netdev_ops = {
.ndo_open = fec_enet_open, //打开网络设备
.ndo_stop = fec_enet_close, //关闭网络设备
.ndo_start_xmit = fec_enet_start_xmit, //发送函数
.ndo_select_queue = fec_enet_select_queue, //设备支持多传输队列的时候选择使用哪个队列
.ndo_set_rx_mode = set_multicast_list, /*改变地址过滤列表,根据net_device结构体中的flag成员 *
* 变量来设置soc的网络外设寄存器,比如可以设置网卡为混杂模式 单播模式 或者多播模式 */
.ndo_change_mtu = eth_change_mtu, /* 改变mtu大小 */
.ndo_validate_addr = eth_validate_addr, /* 验证mac地址合法性 */
.ndo_tx_timeout = fec_timeout, /* 发送超时时此函数会执行 */
.ndo_set_mac_address = fec_set_mac_address, /* 修改网卡的mac地址 */
.ndo_do_ioctl = fec_enet_ioctl, /* 用户调用ioctl的时候的此函数会执行 */
#ifdef CONFIG_NET_POLL_CONTROLLER
.ndo_poll_controller = fec_poll_controller,
#endif
.ndo_set_features = fec_set_features, /* 设置feature属性,设置硬件相关属性 */
};当打开一个网卡设备时,fec_enet_open函数就会执行,
// drivers/net/ethernet/freescale/fec_main.c
static int fec_enet_open(struct net_device *ndev)
{
struct fec_enet_private *fep = netdev_priv(ndev);
const struct platform_device_id *id_entry =
platform_get_device_id(fep->pdev);
int ret;
pinctrl_pm_select_default_state(&fep->pdev->dev);
ret = fec_enet_clk_enable(ndev, true); //使能enet时钟
if (ret)
return ret;
/* I should reset the ring buffers here, but I don't yet know
* a simple way to do that.
* 我应该在这里重置环缓冲区,但我还不知道一个简单的方法。
*/
/* 分配传输和接收缓存区 */
ret = fec_enet_alloc_buffers(ndev);
if (ret)
goto err_enet_alloc;
/* Init MAC prior to mii bus probe */
fec_restart(ndev);
/* Probe and connect to PHY when open the interface */
ret = fec_enet_mii_probe(ndev);
if (ret)
goto err_enet_mii_probe;
/* 使能NAPI调度 */
napi_enable(&fep->napi);
/* 开启PHY设备 */
phy_start(fep->phy_dev);
/* 激活发送队列 */
netif_tx_start_all_queues(ndev);
pm_runtime_get_sync(ndev->dev.parent);
if ((id_entry->driver_data & FEC_QUIRK_BUG_WAITMODE) &&
!fec_enet_irq_workaround(fep))
pm_qos_add_request(&fep->pm_qos_req,
PM_QOS_CPU_DMA_LATENCY,
0);
else
pm_qos_add_request(&fep->pm_qos_req,
PM_QOS_CPU_DMA_LATENCY,
PM_QOS_DEFAULT_VALUE);
device_set_wakeup_enable(&ndev->dev, fep->wol_flag &
FEC_WOL_FLAG_ENABLE);
fep->miibus_up_failed = false;
return 0;
err_enet_mii_probe:
fec_enet_free_buffers(ndev);
err_enet_alloc:
fep->miibus_up_failed = true;
if (!fep->mii_bus_share)
pinctrl_pm_select_sleep_state(&fep->pdev->dev);
return ret;
}
static int fec_enet_alloc_buffers(struct net_device *ndev)
{
struct fec_enet_private *fep = netdev_priv(ndev);
unsigned int i;
/* 分配接收对接缓冲区 */
for (i = 0; i < fep->num_rx_queues; i++)
if (fec_enet_alloc_rxq_buffers(ndev, i))
return -ENOMEM;
/* 分配发送队列缓冲区 */
for (i = 0; i < fep->num_tx_queues; i++)
if (fec_enet_alloc_txq_buffers(ndev, i))
return -ENOMEM;
return 0;
}
总结下来,在网卡驱动中主要完成:
- 注册ndev->netdev_ops = &fec_netdev_ops;
-
注册ethool工具接口ndev->ethtool_ops = &fec_enet_ethtool_ops;
-
注册NAPI机制所需要的poll接口:netif_napi_add(ndev, &fep->napi, fec_enet_rx_napi, NAPI_POLL_WEIGHT);
-
申请中断并注册中断处理函数:ret = devm_request_irq(&pdev->dev, irq, fec_enet_interrupt, 0, pdev->name, ndev);
-
注册MDIO总线,完成MII/RMII接口的初始化,ret = fec_enet_mii_init(pdev);
fep->mii_bus->name = "fec_enet_mii_bus"; // 总线名字
fep->mii_bus->read = fec_enet_mdio_read; // 总线读,是用来读phy芯片寄存器的;
fep->mii_bus->write = fec_enet_mdio_write; // 总线写,是用来写phy芯片寄存器的;-
注册net_device结构体,ret = register_netdev(ndev)
2 准备接收数据
2.1 硬中断处理
首先,数据帧从网线到达网卡上的时候,第一站就是网卡的接收队列。网卡在分配给自己的RingBuferr中寻找可用的内存位置,当RingBuffer中保存数据之后会向cpu发起一个硬中断,通知cpu有数据到达。
前面网卡驱动部分讲到网卡注册的中断处理函数是fec_enet_interrupt函数,在该函数中会启动NAPI调度。__napi_schedule() -> ____napi_schedule() 。
// drivers/net/ethernet/freescale/fec_main.c
/* 中断处理函数 */
static irqreturn_t fec_enet_interrupt(int irq, void *dev_id)
{
struct net_device *ndev = dev_id;
struct fec_enet_private *fep = netdev_priv(ndev);
uint int_events;
irqreturn_t ret = IRQ_NONE;
/* 获取中断状态寄存器 */
int_events = readl(fep->hwp + FEC_IEVENT);
writel(int_events, fep->hwp + FEC_IEVENT);
/* 统计中断信息,发生了哪些中断 */
fec_enet_collect_events(fep, int_events);
/* */
if ((fep->work_tx || fep->work_rx) && fep->link)
{
ret = IRQ_HANDLED;
/* 检查NAPI是否可以调度 */
if (napi_schedule_prep(&fep->napi))
{
/* Disable the NAPI interrupts */
writel(FEC_ENET_MII, fep->hwp + FEC_IMASK);
//linux_4.1.15/net/core/dev.c
__napi_schedule(&fep->napi); //启动NAPI调度,这是napi的poll(fec_enet_rx_napi)函数就会执行;
}
}
if (int_events & FEC_ENET_MII) {
ret = IRQ_HANDLED;
complete(&fep->mdio_done);
}
if (fep->ptp_clock)
fec_ptp_check_pps_event(fep);
return ret;
}在____napi_schedule函数中会将napi中的poll_list挂到softnet_data的poll_list上,softnet_list是一个双向链表,其中的设备都带有输入帧等待被处理,而softnet_data就是在1.2小节提到的net_dev_init函数中会申请softnet_data数据结构。
// net/core/dev.c
/* Called with irq disabled 这块是硬中断执行的函数,在硬中断中发出一个软中断 */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
/* 将napi->poll_list挂到softnet_data的poll_list上,napi中的poll_list带有等待处理的帧 */
list_add_tail(&napi->poll_list, &sd->poll_list);
/* 触发一个软中断 NET_RX_SOFTIRQ */
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
// net/core/dev.c
static int __init net_dev_init(void)
{
...
for_each_possible_cpu(i)
{
/* 为每个cpu申请softnet_data数据结构,*/
struct softnet_data *sd = &per_cpu(softnet_data, i);
/* 初始化softnet_data结构用于存放数据数据包队列,处理队列的队列头,以及轮询链表头 */
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
}
...
}紧接着__raise_softirq_irqoff函数会触发一个软中断NET_RX_SOFTIRQ,这里所谓的触发过程只是对一个变量进行一次或运算而已。
// kernel/softirq.c
void __raise_softirq_irqoff(unsigned int nr)
{
trace_softirq_raise(nr);
or_softirq_pending(1UL << nr);
}
// include/linux/interrupt.h
#define or_softirq_pending(x) (local_softirq_pending() |= (x))
// include/linux/irq_cpustat.h
#define local_softirq_pending() \
__IRQ_STAT(smp_processor_id(), __softirq_pending)
#define __IRQ_STAT(cpu, member) (irq_stat[cpu].member)之前讲过,Linux中硬中断里只是完成简单必要的工作,剩下的大部分处理都是交给软中断的。通过以上代码可以看到,硬中断处理过程真的很短,只是将做了两件事:1、将napi->poll_list添加到softnet_data上,第二标记软中断。剩下的工作就是等待cpu调度,然后进入软中断完成繁重的数据接收处理工作。
2.2 ksoftirqd内核线程处理软中断
网络数据包的接收处理过程主要都是在ksoftirqd内核线程中完成的,软中断都是在这里处理的。
前面在介绍内核创建了ksoftirqd线程,该线程会执行run_ksoftirqd函数,在该函数中会判断__softirq_pending表示是否置位,如果置位表示有软中断发生,就会执行到__do_softirq函数中。
// kernel/softirq.c
/* 创建softirqd线程 */
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",
};
static void run_ksoftirqd(unsigned int cpu)
{
local_irq_disable();
/* 判断是否存在软中断 */
if (local_softirq_pending())
{
/*
* We can safely run softirq on inline stack, as we are not deep
* in the task stack here.因为我们没有深入到任务堆栈中。
*/
__do_softirq();
local_irq_enable();
cond_resched_rcu_qs();
return;
}
local_irq_enable();
}而__softirq_pending标志就是在硬中断中写入的,接下来看__do_softirq函数中是如何处理的。在该函数中会执行到注册的软中断处理函数里面h->action(h);
// kernel/softirq.c
asmlinkage __visible void __do_softirq(void)
{
...
h = softirq_vec;
while ((softirq_bit = ffs(pending)))
{
h += softirq_bit - 1;
/* 执行软中断注册的action函数 *
* 网络接收注册的软中断函数是net_rx_action函数 */
h->action(h);
}
...
}而在net/core/dev.c文件中,会注册数据接收的中断处理函数为net_rx_action函数,也就是这块h->action(h)会执行到的函数实体。
// net/core/dev.c
static int __init net_dev_init(void)
{
...
/* 注册接收和发送的软中断函数,分别为net_tx_action和net_rx_action函数,完成网络数据包的发送和接收 */
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
...
}接下来让我们看一下net_rx_action函数,该函数中会获取当前cpu变量softnet_data,对其poll_list进行遍历,然后执行网卡驱动注册的poll函数。
// net/core/dev.c
/* 网络数据包接收函数 */
static void net_rx_action(struct softirq_action *h)
{
local_irq_disable(); /* 关闭硬中断,防止重复添加poll_list */
list_splice_init(&sd->poll_list, &list);
for (;;)
{
struct napi_struct *n;
...
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
...
}
}
static int napi_poll(struct napi_struct *n, struct list_head *repoll)
{
...
if (test_bit(NAPI_STATE_SCHED, &n->state))
{
/* 调用napi注册的poll函数,也就是fec_enet_rx_napi函数 */
work = n->poll(n, weight);
trace_napi_poll(n);
}
...
}而这块的这块网卡注册的poll函数就是在fec_enet_init中注册的fec_enet_rx_napi函数。在fec_enet_rx_napi函数中会完成数据包的接收。
// drivers/net/ethernet/freescale/fec_main.c
static int fec_enet_init(struct net_device *ndev)
{
...
/* 注册NAPI机制所需的poll,兼容NAPI机制;
* fec_enet_rx_napi就是poll机制要用到的轮询接收数据函数;
* 软中断通过此函数接收数据包;
*/
netif_napi_add(ndev, &fep->napi, fec_enet_rx_napi, NAPI_POLL_WEIGHT);
...
}
/* NAPI的poll函数,软中断中通过这个函数来接收数据包 */
static int fec_enet_rx_napi(struct napi_struct *napi, int budget)
{
struct net_device *ndev = napi->dev;
struct fec_enet_private *fep = netdev_priv(ndev);
int pkts;
/* 进行数据接收 */
pkts = fec_enet_rx(ndev, budget);
/* 进行数据发送 */
fec_enet_tx(ndev);
if (pkts < budget)
{
/* 宣布一次轮询结束 */
napi_complete(napi);
/* 重新使能中断 */
writel(FEC_DEFAULT_IMASK, fep->hwp + FEC_IMASK);
}
return pkts;
}接下来看一下数据包接收函数fec_enet_rx_queue,该函数会从ndev->rx_skbuff中获取数据包。
static int fec_enet_rx_queue(struct net_device *ndev, int budget, u16 queue_id)
{
...
while (!((status = bdp->cbd_sc) & BD_ENET_RX_EMPTY))
{
/* 调用fec_enet_get_bd_index函数得到rx_skbuff中的数据包索引值 */
index = fec_enet_get_bd_index(rxq->rx_bd_base, bdp, fep);
skb = rxq->rx_skbuff[index]; /* 取下数据包 */
}
...
/* 该函数代表网卡的GRO特性,可以理解为把相关的小包合并为一个打包,目的是减少传送网络栈的包数 */
napi_gro_receive(&fep->napi, skb);
}在fec_enet_rx_queue函数中通过napi_gro_receive函数调用napi_skb_finish将数据包送往协议栈中。
// net/core/dev.c
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
/* 这个函数代表网卡GRO特性 可以简单理解成把相关小包合并成一个大包 减少传送网络栈的报数 */
trace_napi_gro_receive_entry(skb);
skb_gro_reset_offset(skb);
/* 通过该函数会将网络数据包送给协议栈处理 */
return napi_skb_finish(dev_gro_receive(napi, skb), skb);
}
// net/core/dev.c
static gro_result_t napi_skb_finish(gro_result_t ret, struct sk_buff *skb)
{
switch (ret)
{
// 通过netif_receive_skb_internal函数将数据包发送到协议栈中处理
case GRO_NORMAL:
if (netif_receive_skb_internal(skb))
ret = GRO_DROP;
break;
case GRO_DROP:
kfree_skb(skb);
break;
case GRO_MERGED_FREE:
if (NAPI_GRO_CB(skb)->free == NAPI_GRO_FREE_STOLEN_HEAD)
kmem_cache_free(skbuff_head_cache, skb);
else
__kfree_skb(skb);
break;
case GRO_HELD:
case GRO_MERGED:
break;
}
return ret;
}2.3 网络协议栈处理
在netif_receive_skb_internal函数中会根据数据包的协议类型进行处理,加入是udp数据包,将数据包依次发送到ip_rcv和udp_rcv等协议处理函数中进行处理。
netif_receive_skb_internal
-> __netif_receive_skb
-> __netif_receive_skb_core
在__netif_receive_skb_core函数中,
// net/core/dev.c
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
{
...
/* pacp逻辑,这里会将数据送入抓包点,tcpdump就是从这个入口获取数据包的 *
* tcpdump通过虚拟协议的工作方式,将抓包函数以协议的形式挂到type_all上 *
* 设备遍历所有协议,这样就能抓到数据包 */
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
...
}
static inline int deliver_skb(struct sk_buff *skb,
struct packet_type *pt_prev,
struct net_device *orig_dev)
{
if (unlikely(skb_orphan_frags(skb, GFP_ATOMIC)))
return -ENOMEM;
atomic_inc(&skb->users);
/* 这块就调用到协议层注册的处理函数中了,通过pt_prev->func函数
调用协议层之前注册的处理函数,传入当前的数据包skb,数据包所在的
skb->dev,当前协议类型结构体指针pt_prev以及数据包最初接收的网络
设备指针orig_dev等参数 */
/* 不同的的协议会处理各自的处理函数,这些函数会根据协议的具体规范
和逻辑来对数据包进行进一步的解析和处理或者转发等操作 */
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}deliver_skb函数是内核网络协议栈中一个关键的桥梁,它将底层接收到的数据包安全的传递到上层各个协议对应的处理函数中,协调数据包的流转,保证整个整个网络数据包处理流程的正常进行。
而这块的func指针就是在net/ipv4/af_inet.c文件中的inet_init函数中进行注册的,对于arp协议会传到arp_rcv函数,对于udp和tcp协议会传到ip_rcv函数。
// net/ipv4/af_inet.c
static int __init inet_init(void)
{
...
/*
* Set the ARP module up
对地址解析协议ARP模块进行初始化,ARP协议主要用于将IP解析为对应的MAC地址,初始化操作会
设置好相关的数据结构,缓存机制,保障网络通信中的IP地址与物理地址的映射功能正常运行
*/
arp_init();
/* 注册ip_rcv函数,ip_packet_type涉及具体协议的入口
注册ip_packet_type相关处理函数,使得网络设备在接收IP数据报时能够找到对应的处理入口,进入内核协议栈
中正确的处理流程进行后续的解包 路由 转发等操作。
*/
dev_add_pack(&ip_packet_type);
...
}
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
};
static struct packet_type arp_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_ARP),
.func = arp_rcv,
};2.4 IP层处理
在ip_rcv函数中,重点看一下NF_HOOK()函数,该函数是一个钩子函数,是和iptables_netifilter相关。当执行完钩子函数之后就会执行到ip_rcv_finish()函数中。
// net/ipv4/ip_input.c
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
const struct iphdr *iph;
u32 len;
/* When the interface is in promisc. mode, drop all the crap
* that it receives, do not try to analyse it.
*/
if (skb->pkt_type == PACKET_OTHERHOST)
goto drop;
IP_UPD_PO_STATS_BH(dev_net(dev), IPSTATS_MIB_IN, skb->len);
// 对数据包进行共享检查
skb = skb_share_check(skb, GFP_ATOMIC);
if (!skb) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INDISCARDS);
goto out;
}
if (!pskb_may_pull(skb, sizeof(struct iphdr)))
goto inhdr_error;
// 获取数据包的头部,通过ip_hdr(skb)宏获取指向的数据包IP头部
/* 结构体的指针并赋值给iph变量 */
iph = ip_hdr(skb);
/*
* RFC1122: 3.2.1.2 MUST silently discard any IP frame that fails the checksum.
*
* Is the datagram acceptable?
*
* 1. Length at least the size of an ip header
* 2. Version of 4
* 3. Checksums correctly. [Speed optimisation for later, skip loopback checksums]
* 4. Doesn't have a bogus length
*/
/* 数据包头部20字节,并且处理的的ipv4,如果不满足条件则报错 */
if (iph->ihl < 5 || iph->version != 4)
goto inhdr_error;
BUILD_BUG_ON(IPSTATS_MIB_ECT1PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_1);
BUILD_BUG_ON(IPSTATS_MIB_ECT0PKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_ECT_0);
BUILD_BUG_ON(IPSTATS_MIB_CEPKTS != IPSTATS_MIB_NOECTPKTS + INET_ECN_CE);
IP_ADD_STATS_BH(dev_net(dev),
IPSTATS_MIB_NOECTPKTS + (iph->tos & INET_ECN_MASK),
max_t(unsigned short, 1, skb_shinfo(skb)->gso_segs));
if (!pskb_may_pull(skb, iph->ihl*4))
goto inhdr_error;
iph = ip_hdr(skb);
if (unlikely(ip_fast_csum((u8 *)iph, iph->ihl)))
goto csum_error;
len = ntohs(iph->tot_len);
if (skb->len < len) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INTRUNCATEDPKTS);
goto drop;
} else if (len < (iph->ihl*4))
goto inhdr_error;
/* Our transport medium may have padded the buffer out. Now we know it
* is IP we can trim to the true length of the frame.
* Note this now means skb->len holds ntohs(iph->tot_len).
*/
if (pskb_trim_rcsum(skb, len)) {
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INDISCARDS);
goto drop;
}
skb->transport_header = skb->network_header + iph->ihl*4;
/* Remove any debris in the socket control block */
memset(IPCB(skb), 0, sizeof(struct inet_skb_parm));
/* Must drop socket now because of tproxy. */
skb_orphan(skb);
/* netfilter框架
IPV4协议相关的网络过滤操作,标志IP层进行路由查找之前的处理阶段,
意味着数据包在进入IP层常规的决策等流程之前,先经过netfilter在
这个阶段设置的各种规则(如防火墙 网络地址转换规则等)和检查和处理
不同的钩子点对应不同的网络处理阶段和功能 */
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, NULL, skb,
dev, NULL,
ip_rcv_finish);
csum_error:
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_CSUMERRORS);
inhdr_error:
IP_INC_STATS_BH(dev_net(dev), IPSTATS_MIB_INHDRERRORS);
drop:
kfree_skb(skb);
out:
return NET_RX_DROP;
}
static int ip_rcv_finish(struct sock *sk, struct sk_buff *skb)
{
/* 获取IP头部指针 */
const struct iphdr *iph = ip_hdr(skb);
/* 获取路由表项结构体指针rt */
struct rtable *rt;
if (sysctl_ip_early_demux && !skb_dst(skb) && !skb->sk)
{
const struct net_protocol *ipprot;
int protocol = iph->protocol;
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot && ipprot->early_demux)
{
ipprot->early_demux(skb);
/* must reload iph, skb->head might have changed */
iph = ip_hdr(skb);
}
}
/*
* Initialise the virtual path cache for the packet. It describes
* how the packet travels inside Linux networking.
*/
if (!skb_dst(skb))
{
/* 当数据包的目录缓存skb_dst还未初始化,调用ip_route_input_noref
函数进行路由查找和初始化 */
int err = ip_route_input_noref(skb, iph->daddr, iph->saddr,
iph->tos, skb->dev);
if (unlikely(err)) {
if (err == -EXDEV)
NET_INC_STATS_BH(dev_net(skb->dev),
LINUX_MIB_IPRPFILTER);
goto drop;
}
}
/* 如果ip头部长度大于5字节,意味着存在ip选项,调用ip_rcv_options
来处理ip选项 */
if (iph->ihl > 5 && ip_rcv_options(skb))
goto drop;
/* 首先获取数据包路由表项rt,然后根据路由类型进行处理 */
rt = skb_rtable(skb);
/* 如果路由类型是多播 */
if (rt->rt_type == RTN_MULTICAST)
{
/* 更新内核网络统计中关于输入多播数据包的相关统计信息 */
IP_UPD_PO_STATS_BH(dev_net(rt->dst.dev), IPSTATS_MIB_INMCAST,
skb->len);
}
else if (rt->rt_type == RTN_BROADCAST) /* 如果路由类型是广播 */
IP_UPD_PO_STATS_BH(dev_net(rt->dst.dev), IPSTATS_MIB_INBCAST,
skb->len); /* 更新输入广播数据包的统计信息 */
/* 将数据包传递给上层协议进行进一步的处理,比如传给传输层协议(tcp udp)处理对应的数据内容 */
return dst_input(skb);
drop:
kfree_skb(skb);
return NET_RX_DROP;
}在函数ip_route_input_mc函数中会将函数ip_local_deliver函数赋值给dst.input指针。返回ip_rcv_finish函数中会返回dst_input函数。
// net/ipv4/ip_input.c
ip_route_input_noref()
-> ip_route_input_mc()
{
rth->dst.output = ip_rt_bug;
rth->dst.input= ip_local_deliver;
}
/* Input packet from network to transport. 输入数据包从网络传输 */
// include/net/dst.h
static inline int dst_input(struct sk_buff *skb)
{
return skb_dst(skb)->input(skb);
}ip_local_deliver() -> ip_local_deliver_finish(),在ip_local_deliver_finish函数中,当直行到ret = ipprot->handler(skb);时表示这块的handler函数就表示要将数据包传给上层协议进行处理操作了。
// net/ipv4/ip_input.c
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
/* 通过ip_is_fragment函数判断接受到的ip数据包skb是否为ip分片
这里通过ip_hdr函数获取ip数据包头部指针 */
if (ip_is_fragment(ip_hdr(skb))) {
if (ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
/* 这是netfilter框架定义的一个钩子函数,对应数据包进入本地协议栈的这个阶段
也就是在ip层准备向更高层协议交付时的这个环节,在这里可以定义各种规则来决定
是否允许数据继续传递已经进行一些修改等操作 */
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, NULL, skb,
skb->dev, NULL,
ip_local_deliver_finish);
}
static int ip_local_deliver_finish(struct sock *sk, struct sk_buff *skb)
{
/* 依据接收数据包的网络设备skb->dev来获取对应的网络命名空间net
网络命令空间用于隔离不同网络环境下的网络资源配置等信息 */
struct net *net = dev_net(skb->dev);
/* 使用__skb_pull来调整数据包sdk的指针,使其跳过ip数据包头部,业就是
将数据包指针指向ip数据部分,方便后续上层协议处理模块直接获取到属于自己
协议的有效数据内筒 */
__skb_pull(skb, skb_network_header_len(skb));
/* 读临界区 */
rcu_read_lock();
{
/* 获取ip数据包头部中的协议字段protocol, 其值表示该数据包上层承载
的是那种协议(tcp udp)*/
int protocol = ip_hdr(skb)->protocol;
const struct net_protocol *ipprot;
int raw;
resubmit:
/* 调用raw变量,它会判断数据包是否要以原始的形式进行交付等操作 */
raw = raw_local_deliver(skb, protocol);
/* */
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot)
{
int ret;
/* 安全策略检查 */
if (!ipprot->no_policy)
{
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb))
{
kfree_skb(skb);
goto out;
}
nf_reset(skb);
}
/* 这块的handler函数就对应上层协议真正该处理数据包的函数 */
ret = ipprot->handler(skb);
if (ret < 0)
{
protocol = -ret;
goto resubmit;
}
/* 如果协议处理函数正常执行,则调用IP_INC_STATS_BH函数更新
网络空间net下的ip统计信息,表示成功接收并向本地交付了一个ip
数据包 */
IP_INC_STATS_BH(net, IPSTATS_MIB_INDELIVERS);
}
else
{
/* 该分支用于处理异常情况,当ipprot等于0,表示接收到了未知
协议的ip数据包,此时通过icmp_send函数发生一个icmp目录不可达消息 */
if (!raw)
{
if (xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
IP_INC_STATS_BH(net, IPSTATS_MIB_INUNKNOWNPROTOS);
icmp_send(skb, ICMP_DEST_UNREACH,
ICMP_PROT_UNREACH, 0);
}
kfree_skb(skb);
}
else
{
IP_INC_STATS_BH(net, IPSTATS_MIB_INDELIVERS);
consume_skb(skb);
}
}
}
out:
rcu_read_unlock();
return 0;
}
















 2746
2746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









