






 本文探讨了SQL编译器如何在输入错误时提供精准反馈,包括错误类型的判断及建议修复,通过具体案例分析,展示了如何优化错误信息,使之更符合用户直觉。
本文探讨了SQL编译器如何在输入错误时提供精准反馈,包括错误类型的判断及建议修复,通过具体案例分析,展示了如何优化错误信息,使之更符合用户直觉。
1 引言

编译器除了生成语法树之外,还要在输入出现错误时给出恰当的提示。
比如当用户输入 select (name,这是个未完成的 SQL 语句,我们的目标是提示出这个语句未完成,并给出后续的建议: ) - + % / * . ( 。
2 精读
分析一个 SQL 语句,现将 query 字符串转成 Token 数组,再构造文法树解析,那么可能出现错误的情况有两种:
语句错误。
文法未完成。
给出错误提示的第一步是判断错误发生。
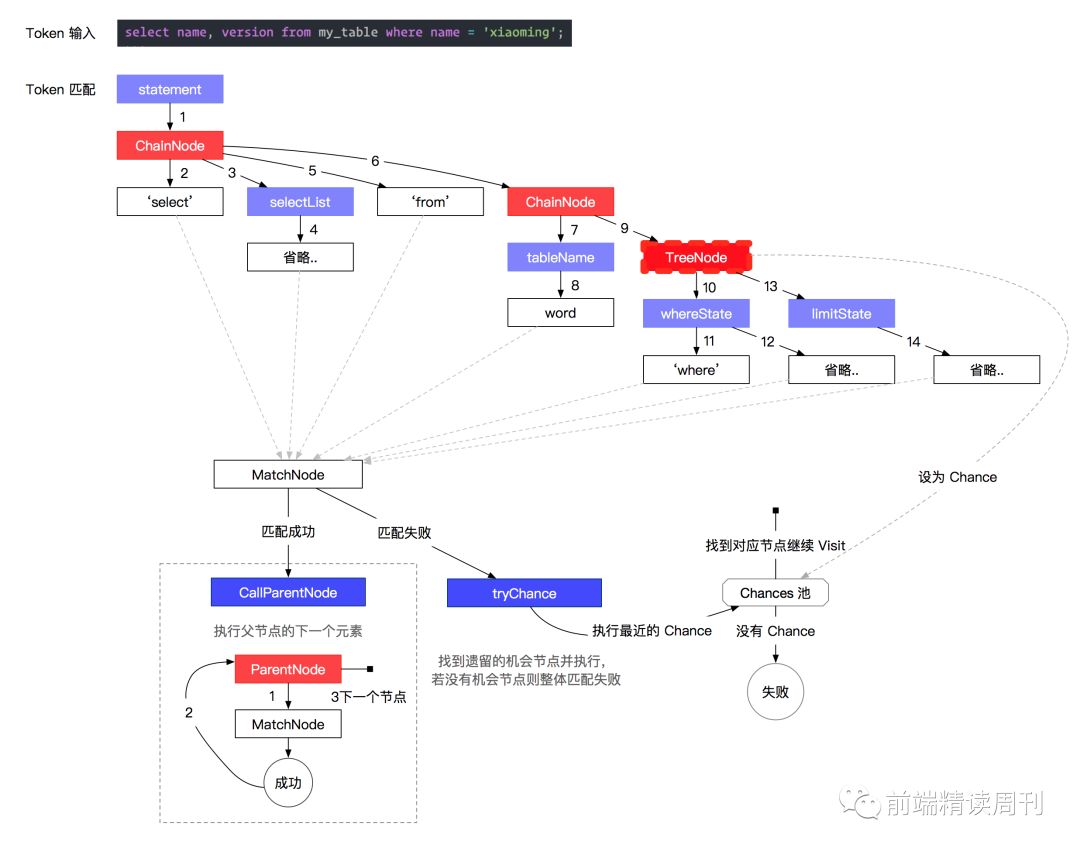
通过这张 Token 匹配过程图可以发现,当深度优先遍历文法节点时,匹配成功后才会返回父元素继续往下走。而当走到父元素没有根节点了才算匹配成功;当尝试 Chance 时没有机会了,就是错误发生的时机。
所以我们只要找到最后一个匹配成功的节点,再根据最后成功与否,以及搜索出下一个可能节点,就能知道错误类型以及给出建议了。
所以在运行语法分析器时,在遇到匹配节点(MatchNode)时,如果匹配成功,就记录下这个节点,这样我们最终会找到最后一个匹配成功的节点:lastMatch。
之后通过 findNextMatchNodes 函数找到下一个可能的推荐节点列表,作为错误恢复的建议。
findNextMatchNodes函数会根据某个节点,找出下一节点所有可能 Tokens 列表,这个函数后面文章再专门介绍,或者你也可以先阅读 源码.
语句错误
也就是任何一个 Token 匹配失败。比如:
这里 error_string 就是冗余的语句。
通过语法解析器分析,可以得到执行失败的结果,然后通过 findNextMatchNodes 函数,我们可以得到下面分析结果:

可以看到,程序判断出了 error_string 这个 Token 属于错误类型,同时给出建议,可以将 error_string 替换成这 14 个建议字符串中任意一个,都能使语句正确。
之所以失败类型判断为错误类型,是因为查找了这个正确 Token table1 后面还有一个没有被使用的 error_string,所以错误归类是 wrong。
注意,这里给出的是下一个 Token 建议,而不是全部 Token 建议,因此推荐了 where 表示 “或者后面跟一个完整的 where 语句”。
文法未完成
和语句错误不同,这种错误所有输入的单词都是正确的,但却没有写完。比如:
通过语法解析器分析,可以得到执行失败的结果,然后通过 findNextMatchNodes 函数,我们可以得到下面分析结果:

可以看到,程序判断出了 * 这个 Token 属于未完成的错误类型,建议在后面补全这 14 个建议字符串中任意一个。比较容易联想到的是 where,但也可以是任意子文法的未完成状态,比如后面补充 , 继续填写字段,或者直接跟一个单词表示别名,或者先输入 as 再跟别名。
之所以失败类型判断为未完成,是因为最后一个正确 Token * 之后没有 Token 了,但语句解析失败,那只有一个原因,就是语句为写完,因此错误归类是 inComplete。
找到最易读的错误类型
在一开始有提到,我们只要找到最后一个匹配成功的节点,就可以顺藤摸瓜找到错误原因以及提示,但最后一个成功的节点可能和我们人类直觉相违背。举下面这个例子:
正常情况,我们都认为错误点在 ~,而最后一个正确输入是 '1'。但词法解析器可不这么想,在我初版代码里,判断出错误是这样的:

提示是 where 错了,而且提示是 .,有点摸不着头脑。
读者可能已经想到了,这个问题与文法结构有关,我们看 fromClause 的文法描述:
虽然实际传入的 where 语句多了一个 ~ 符号,但由于文法认为整个 whereStatement 是可选的,因此出错后会跳出,跳到 b 的位置继续匹配,而 显然 groupByStatement 与 havingStatement 都不能匹配到 where,因此编译器认为 “不会从 b where a = '1' ~” 开始就有问题吧?因此继续往回追溯,从 tableName 开始匹配:
此时第一次走的 b where a = '1' ~ 路线对应 matchWord,因此尝试第二条路线,所以认为 where 应该换成 .。
要解决这个问题,首先要 承认这个判断是对的,因为这是一种 错误提前的情况,只是人类理解时往往只能看到最后几步,所以我们默认用户想要的错误信息,是 正确匹配链路最长的那条,并对 onMatchNode 作出下面优化:
将 lastMatch 对象改为 lastMatchUnderShortestRestToken:
也就是每次匹配到正确字符,都获取剩余 Token 数量,只保留最后一匹配正确 且剩余 Token 最少的那个。
3 总结
做语法解析器错误提示功能时,再次刷新了笔者三观,原来我们以为的必然,在编译器里对应着那么多 “可能”。
当我们遇到一个错误 SQL 时,错误原因往往不止一个,你可以随便截取一段,说是从这一步开始就错了。语法解析器为了让报错符合人们的第一直觉,对错误信息做了 过滤,只保留剩余 Token 数最短的那条错误信息。
4 更多讨论
讨论地址是:精读《手写 SQL 编译器 - 错误提示》 · Issue #101 · dt-fe/weekly
如果你想参与讨论,请点击这里,每周都有新的主题,周末或周一发布。

以下是我个人微信,欢迎交流!
(如想获得阿里内推机会,也可以联系我)

还没关注本公众号好的朋友们,可以扫码关注哈

平时工作繁忙,写文实在不易,欢迎大家"转发"+"在看",你们的支持是我继续写下去的动力,感谢!
???点击“在看”

















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









