




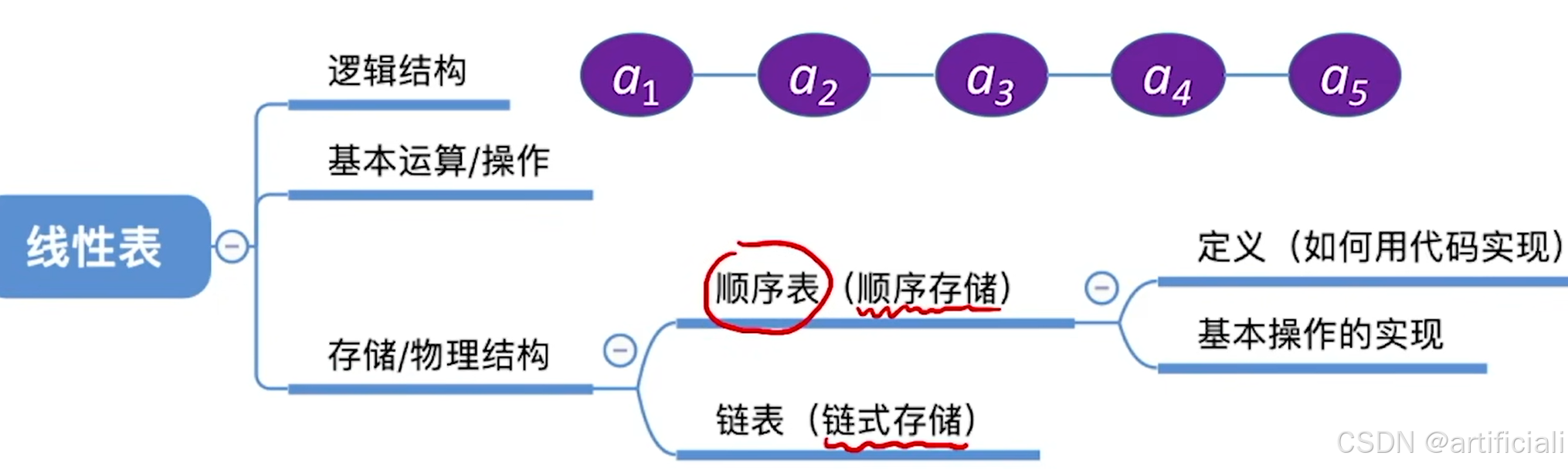
线性表是一种常见的数据结构,具有以下特点:
-
数据元素有限:线性表中的数据元素数量是有限的,可以是空表,也可以包含多个元素。
-
顺序:线性表中的元素是按照一定的顺序排列的,每个元素都有一个确定的位置(称为“位序”),通常从1开始编号。
-
类型相同:线性表中的所有元素属于同一数据类型,例如整数、字符或自定义结构体等。
-
抽象性:线性表是一种抽象的数据结构,定义了数据的逻辑关系,而不关心具体的存储方式。线性表可以通过顺序存储(如数组)或链式存储(如链表)来实现。
-
每个元素是单个元素:线性表中的每个元素都是独立的个体,不包含子结构。例如,一个整数线性表中的每个元素都是一个整数,而不是一个数组或另一个线性表。
线性表的顺序表示
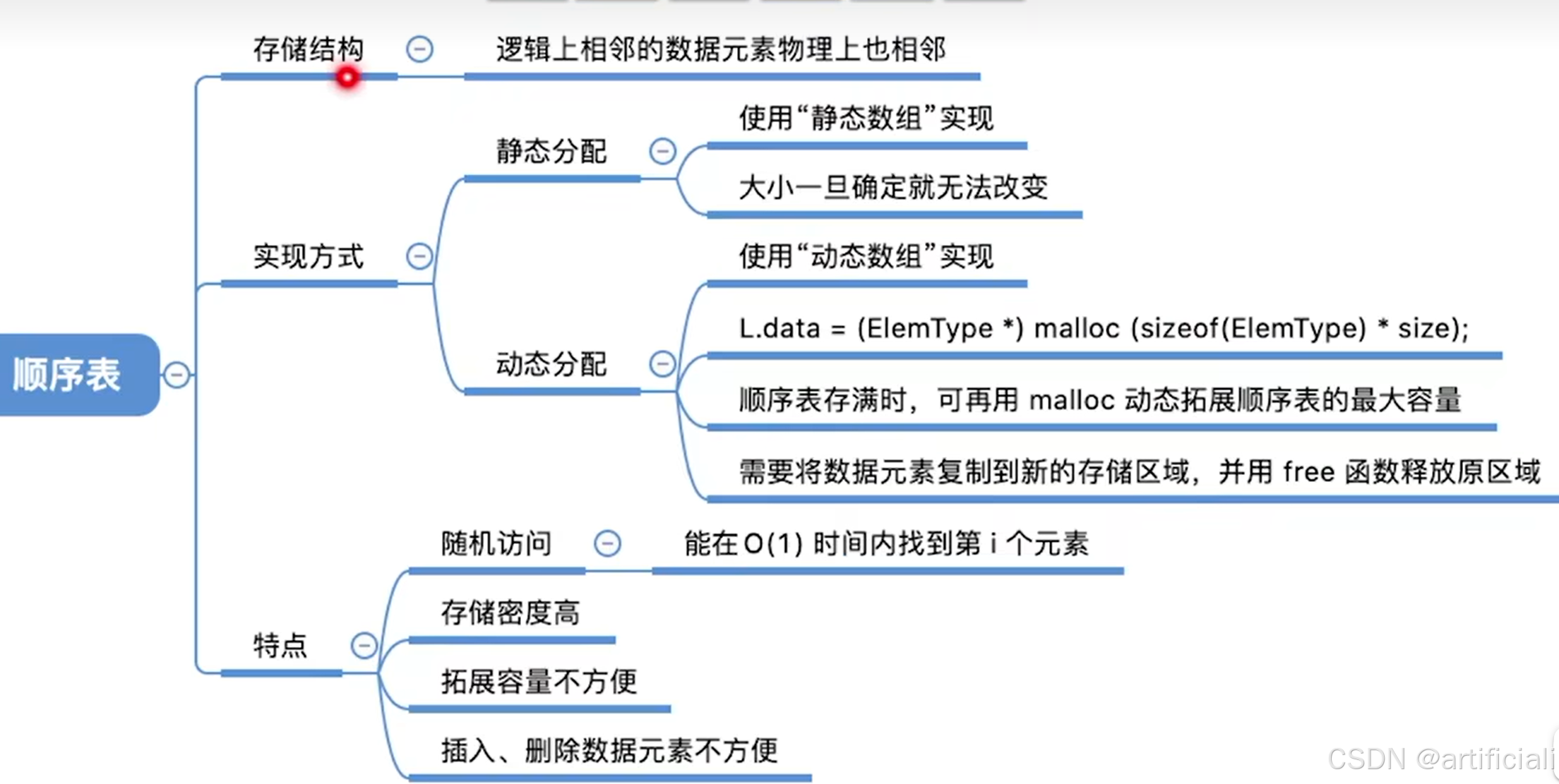

静态分配
//顺序表的实现--静态分配
#include<stdio.h>
#define MaxSize 10 //定义表的最大长度
typedef struct {
int data[MaxSize]; //用静态的"数组"存放数据元素
int length; //顺序表的当前长度
}SqList; //顺序表的类型定义(静态分配方式)
void InitList(SqList &L) {
for (int i = 0; i < MaxSize; i++) {
L.data[i] = 0; //将所有数据元素设置为默认初始值
}
L.length = 0;
}
int main() {
SqList L; //声明一个顺序表
InitList(L); //初始化一个顺序表
for (int i = 0; i < L.length; i++) { //顺序表的打印
printf("data[%d]=%d\n", i, L.data[i]);
}
return 0;
}
插入

#include<stdio.h>
#define MaxSize 10 //定义最大长度
typedef struct {
int data[MaxSize]; //用静态的数组存放数据
int length; //顺序表的当前长度
}SqList; //顺序表的类型定义
void InitList(SqList &L) {
for (int i = 0; i < MaxSize; i++) {
L.data[i] = 0; //将所有数据元素设置为默认初始值
}
L.length = 0;
}
bool ListInsert(SqList &L, int i, int e) {
if (i<1 || i>L.length + 1) { //判断i的范围是否有效
printf("范围无效\n"); return false;
}
if (L.length >= MaxSize) { //当前存储空间已满,不能插入
printf("储空间已满\n"); return false;
}
for (int j = L.length; j >= i; j--) { //将第i个元素及其之后的元素后移
L.data[j] = L.data[j - 1];
}
L.data[i - 1] = e; //在位置i处放入e
L.length++; //长度加1
return true;
}
// 打印顺序表中的元素
void PrintList(SqList &L) {
printf("顺序表元素: ");
for (int i = 0; i < L.length; i++) {
printf("%d ", L.data[i]);
}
printf("\n");
}
int main() {
SqList L; //声明一个顺序表
InitList(L);//初始化顺序表
//...此处省略一些代码;插入几个元素
ListInsert(L, 1, 3); //再顺序表L的第三行插入3
PrintList(L);
return 0;
}删除

// 删除顺序表i位置的数据并存入e
bool ListDelete(SqList &L, int i, int &e) {
if (i < 1 || i > L.length) // 判断i的范围是否有效
return false;
e = L.data[i-1]; // 将被删除的元素赋值给e
for (int j = i; j < L.length; j++) //将第i个位置后的元素前移
L.data[j-1] = L.data[j];
L.length--;
return true;
}
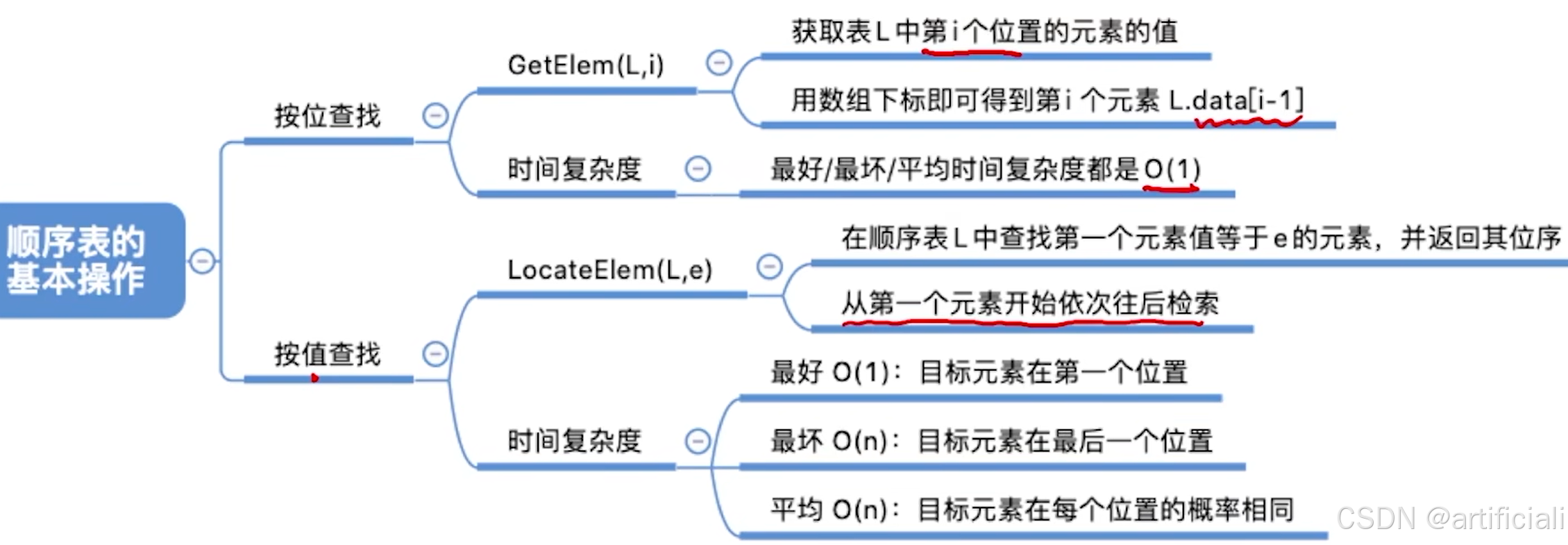
按位查找
// 静态分配的按位查找
#define MaxSize 10
typedef struct {
ElemType data[MaxSize];
int length;
}SqList;
ElemType GetElem(SqList L, int i) {
return L.data[i-1];
}按值查找
#define InitSize 10 //定义最大长度
typedef struct{
ElemTyp *data; //用静态的“数组”存放数据元素
int Length; //顺序表的当前长度
}SqList;
//在顺序表L中查找第一个元素值等于e的元素,并返回其位序
int LocateElem(SqList L, ElemType e){
for(int i=0; i<L.lengthl i++)
if(L.data[i] == e)
return i+1; //数组下标为i的元素值等于e,返回其位序i+1
return 0; //推出循环,说明查找失败
}
//调用LocateElem(L,9)动态分配

#include <stdio.h>
#include <stdlib.h>
#define InitSize 5 // 默认的最大长度
typedef struct {
int *data; // 指示动态分配数组的指针
int MaxSize; // 顺序表的最大容量
int length; // 顺序表的当前长度
} SeqList;
// 初始化顺序表
void InitList(SeqList &L) {
L.data = (int *)malloc(InitSize * sizeof(int));
//if (L.data == NULL) {
// printf("内存分配失败\n");
// exit(1);
//}
L.length = 0;
L.MaxSize = InitSize;
}
// 增加动态数组的长度
void IncreaseSize(SeqList &L, int len) {
int *p = L.data;
L.data = (int *)malloc((L.MaxSize + len) * sizeof(int));
//if (L.data == NULL) {
// printf("内存分配失败\n");
// exit(1);
//}
for (int i = 0; i < L.length; i++) {
L.data[i] = p[i];
}
L.MaxSize = L.MaxSize + len;
free(p);
}
// 在顺序表的指定位置插入元素
int ListInsert(SeqList &L, int index, int element) {
if (index < 1 || index > L.length + 1) {
printf("插入位置不合法\n");
return 0;
}
if (L.length >= L.MaxSize) {
printf("顺序表已满,正在扩容...\n");
IncreaseSize(L, 5); // 扩容5个元素
}
for (int i = L.length; i >= index; i--) {
L.data[i] = L.data[i - 1];
}
L.data[index - 1] = element;
L.length++;
return 1;
}
// 打印顺序表中的元素
void PrintList(SeqList &L) {
printf("顺序表元素: ");
for (int i = 0; i < L.length; i++) {
printf("%d ", L.data[i]);
}
printf("\n");
}
int main() {
SeqList L;
InitList(L); // 初始化顺序表
// 往顺序表中插入元素
ListInsert(L, 1, 10);
ListInsert(L, 2, 20);
ListInsert(L, 3, 30);
ListInsert(L, 4, 40);
ListInsert(L, 5, 50);
ListInsert(L, 6, 60); // 触发扩容
ListInsert(L, 7, 70);
ListInsert(L, 8, 80);
ListInsert(L, 9, 90);
ListInsert(L, 10, 100);
ListInsert(L, 11, 110); // 再次触发扩容
// 打印顺序表
PrintList(L);
// 释放动态分配的内存
free(L.data);
return 0;
}线性表的链式表示

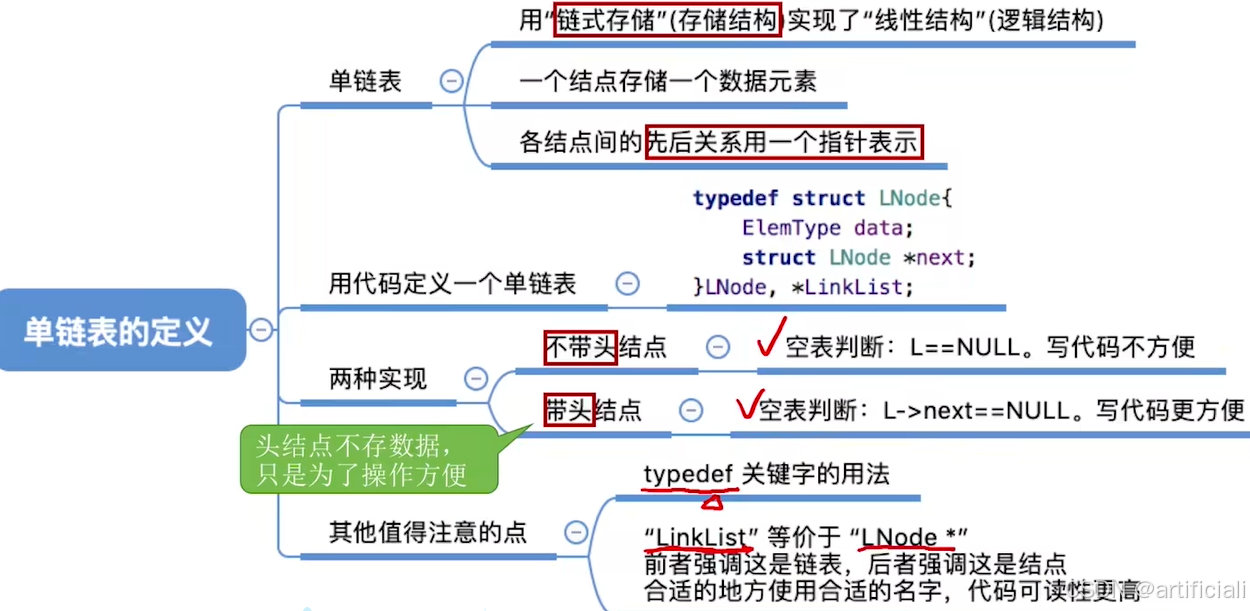
单链表:用链式存储实现了线性结构。一个结点存储一个数据元素,各结点间的前后关系用一个指针表示。
特点:
- 优点:不要求大片连续空间,改变容量方便。
- 缺点:不可随机存取,要耗费一定空间存放指针。
两种实现方式:
带头结点,写代码更方便。头结点不存储数据,头结点指向的下一个结点才存放实际数据。
不带头结点,麻烦。对第一个数据结点与后续数据结点的处理需要用不同的代码逻辑,对空表和非空表的处理需要用不同的代码逻辑。
struct LNode {
ElemType data; // 数据域,存放一个数据元素
struct LNode *next; // 指针域,指向下一个结点
};
typedef struct LNode LNode; // 定义 LNode 为 struct LNode 的别名
typedef struct LNode *LinkList; // 定义 LinkList 为 struct LNode* 的别名
//可以直接
typedef struct LNode {
ElemType data; // 数据域,存放一个数据元素
struct LNode *next; // 指针域,指向下一个结点
}LNode,*LinkList;-
原本需要写
struct LNode,现在可以直接写LNode。 -
原本需要写
struct LNode *,现在可以直接写LinkList。
- 强调这是一个单链表--使用 LinkList
- 强调这是一个结点--使用 LNode*
不带头初始化
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
//初始化一个空的单链表
bool InitList(LinkList &L){
L = NULL; //空表,暂时还没有任何结点
return true;
}
void test(){
LinkList L; //声明一个指向单链表的头指针
//初始化一个空表
InitList(L);
...
}
//判断单链表是否为空
bool Empty(LinkList L){
return (L==NULL)
}带头初始化
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
//初始化一个单链表(带头结点)
bool InitList(LinkList &L)
{
L = (LNode*) malloc(sizeof(LNode)); //头指针指向的结点——分配一个头结点(不存储数据)
if (L == NULL) //内存不足,分配失败
return false;
L -> next = NULL; //头结点之后暂时还没有结点
return true;
}
void test()
{
LinkList L; //声明一个指向单链表的指针: 头指针
//初始化一个空表
InitList(L);
//...
}
//判断单链表是否为空(带头结点)
bool Empty(LinkList L)
{
if (L->next == NULL)
return true;
else
return false;
}单链表的插入
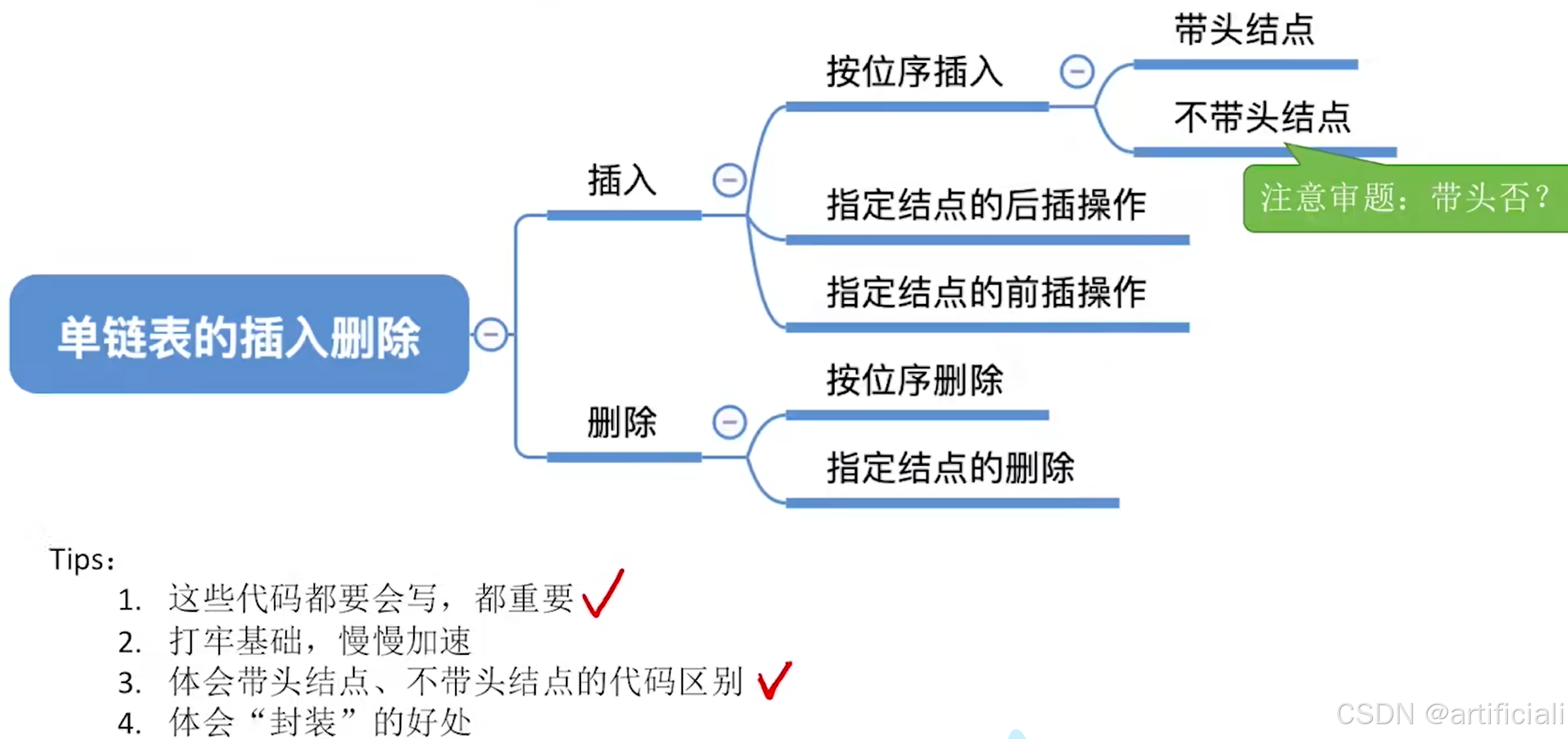
按位序插入(带头结点)
Listlnsert(&Li,e): 插入操作。在表L中的第i个位置上插入指定元素e
找到第i-1个结点(前驱结点),将新结点插入其后;其中头结点可以看作第0个结点,故i=1时也适用。
平均时间复杂度:O(n)
假设位置3图示:
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
//在第i个位置插入元素e(带头结点)
bool ListInsert(LinkList &L, int i, ElemType e)
{
//判断i的合法性, i是位序号(从1开始)
if(i<1)
return False;
LNode *p; //指针p指向当前扫描到的结点
int j=0; //当前p指向的是第几个结点
p = L; //L指向头结点,头结点是第0个结点(不存数据)
//循环找到第i-1个结点
while(p!=NULL && j<i-1){ //如果i>lengh, p最后会等于NULL
p = p->next; //p指向下一个结点
j++;
}
if (p==NULL) //如果p指针知道最后再往后就是NULL
return false;
//在第i-1个结点后插入新结点
LNode *s = (LNode *)malloc(sizeof(LNode)); //申请一个结点
s->data = e;
s->next = p->next;
p->next = s; //将结点s连到p后,后两步千万不能颠倒qwq
return true;
}按位序插入(不带头结点)
Listlnsert(&L,i,e): 插入操作。在表L中的第i个位置上插入指定元素e。将新结点插入其后;
因为不带头结点,所以不存在“第0个”结点,因此!i=1 时,需要特殊处理——插入(删除)第1个元素时,需要更改头指针L;
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool ListInsert(LinkList &L, int i, ElemType e)
{
if(i<1)
return false;
//插入到第1个位置时的操作有所不同!
if(i==1){
LNode *s = (LNode *)malloc(size of(LNode));
s->data =e;
s->next =L;
L=s; //头指针指向新结点
return true;
}
//i>1的情况与带头结点一样!唯一区别是j的初始值为1
LNode *p; //指针p指向当前扫描到的结点
int j=1; //当前p指向的是第几个结点
p = L; //L指向头结点,头结点是第0个结点(不存数据)
//循环找到第i-1个结点
while(p!=NULL && j<i-1){ //如果i>lengh, p最后会等于NULL
p = p->next; //p指向下一个结点
j++;
}
if (p==NULL) //i值不合法
return false;
//在第i-1个结点后插入新结点
LNode *s = (LNode *)malloc(sizeof(LNode)); //申请一个结点
s->data = e;
s->next = p->next;
p->next = s;
return true;
}
指定结点的后插操作
InsertNextNode(LNode *p, ElemType e);
给定一个结点p,在其之后插入元素e; 根据单链表的链接指针只能往后查找,故给定一个结点p,那么p之后的结点我们都可知,但是p结点之前的结点无法得知
typedef struct LNode
{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool InsertNextNode(LNode *p, ElemType e)
{
if(p==NULL){
return false;
}
LNode *s = (LNode *)malloc(sizeof(LNode));
//某些情况下分配失败,比如内存不足
if(s==NULL)
return false;
s->data = e; //用结点s保存数据元素e
s->next = p->next;
p->next = s; //将结点s连到p之后
return true;
} //平均时间复杂度 = O(1)
//有了后插操作,那么在第i个位置上插入指定元素e的代码可以改成:
bool ListInsert(LinkList &L, int i, ElemType e)
{
if(i<1)
return False;
LNode *p; //指针p指向当前扫描到的结点
int j=0; //当前p指向的是第几个结点
p = L; //L指向头结点,头结点是第0个结点(不存数据)
//循环找到第i-1个结点
while(p!=NULL && j<i-1){ //如果i>lengh, p最后4鸟会等于NULL
p = p->next; //p指向下一个结点
j++;
}
return InsertNextNode(p, e)
}
指定结点的前插操作
如何实现方法1:传入头指针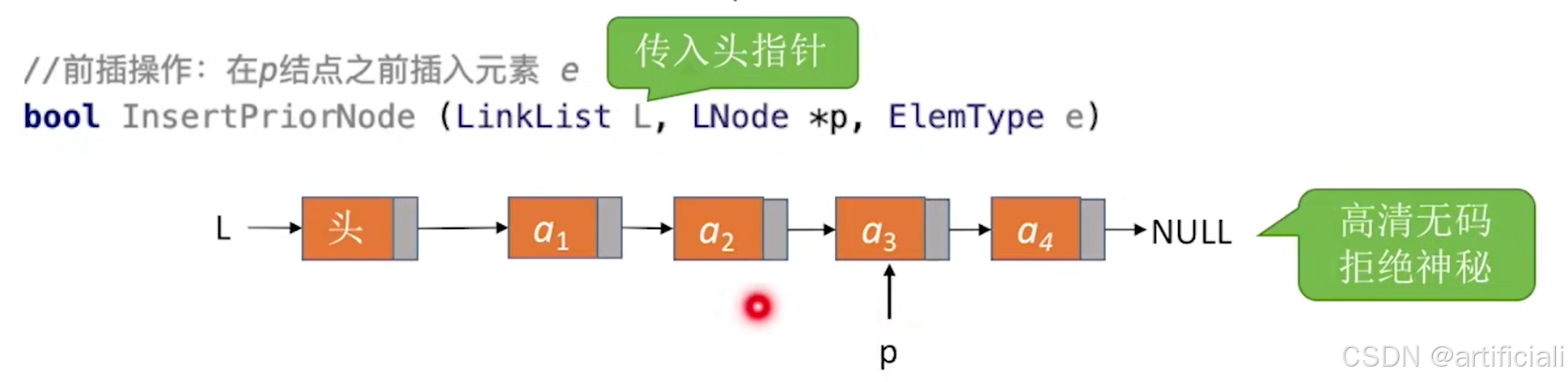
方法二:设待插入结点是s,将s插入到p的前面。我们仍然可以将s插入到*p的后面。然后将p->data与s->data交换,这样既能满足了逻辑关系,又能是的时间复杂度为O(1)
一句话:就是在p后插入s,然后交换数值p和s的数值,相对位置就是s在p前。
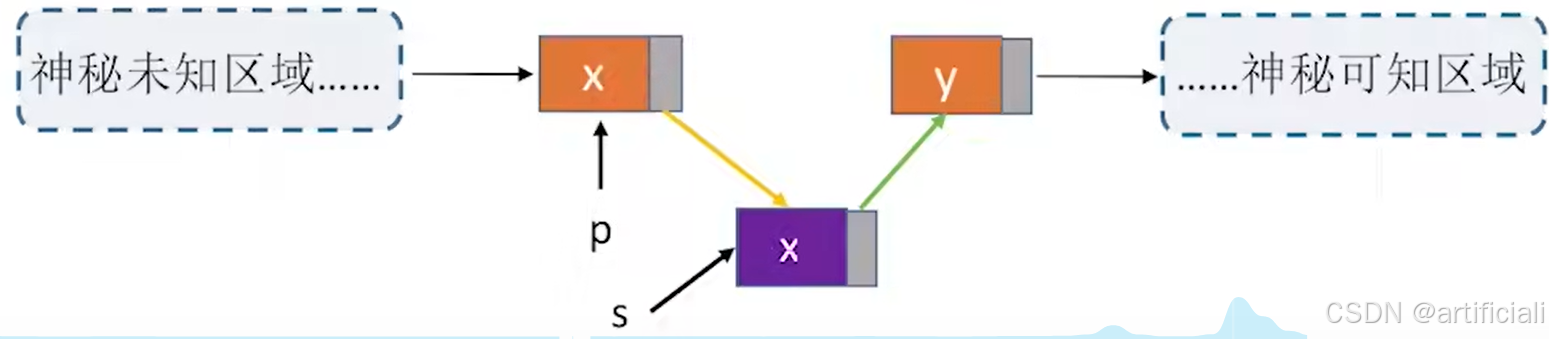
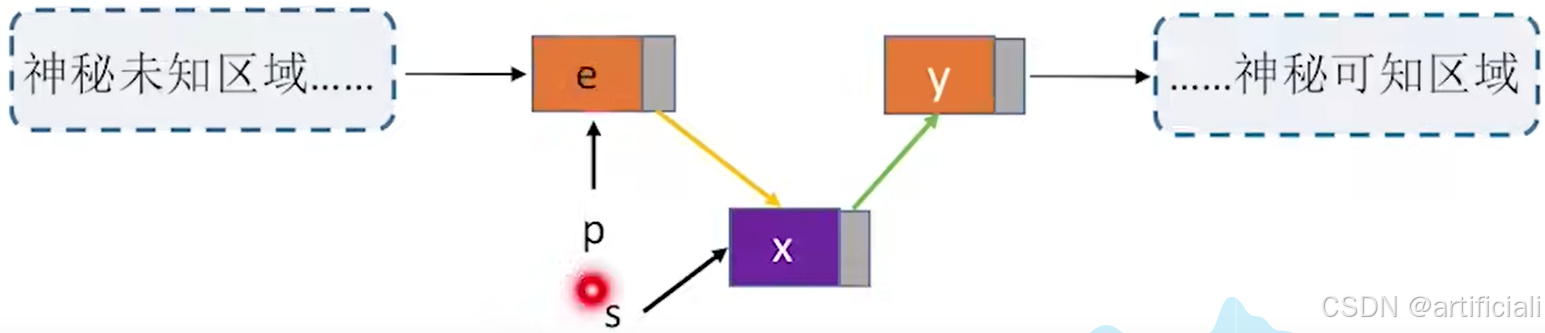
//前插操作:在p结点之前插入元素e
bool InsertPriorNode(LNode *p, ElenType e){
if(p==NULL)
return false;
LNode *s = (LNode *)malloc(sizeof(LNode));
if(s==NULL) //内存分配失败
return false;
//重点来了!
s->next = p->next;
p->next = s; //新结点s连到p之后
s->data = p->data; //将p中元素复制到s
p->data = e; //p中元素覆盖为e
return true;
} 单链表的删除
按位序删除节点
ListDelete(&L, i, &e): 删除操作,删除表L中第i个位置的元素,并用e返回删除元素的值;头结点视为“第0个”结点;
思路:找到第i-1个结点,将其指针指向第i+1个结点,并释放第i个结点
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool ListDelete(LinkList &L, int i, ElenType &e){
if(i<1) return false;
LNode *p; //指针p指向当前扫描到的结点
int j=0; //当前p指向的是第几个结点
p = L; //L指向头结点,头结点是第0个结点(不存数据)
//循环找到第i-1个结点
while(p!=NULL && j<i-1){ //如果i>lengh, p最后会等于NULL
p = p->next; //p指向下一个结点
j++;
}
if(p==NULL)
return false;
if(p->next == NULL) //第i-1个结点之后已无其他结点
return false;
LNode *q = p->next; //令q指向被删除的结点
e = q->data; //用e返回被删除元素的值
p->next = q->next; //将*q结点从链中“断开”
free(q) //释放结点的存储空间
return true;
}
书上代码:
typedef struct LNode{
ElemType data;
struct LNode *next;
}LNode, *LinkList;
bool ListDelete(LinkList &L, int i, ElenType &e){
LNode *p; //指针p指向当前扫描到的结点
int j=0; //当前p指向的是第几个结点
p = L; //L指向头结点,头结点是第0个结点(不存数据)
//循环找到第i-1个结点
while(p->next!=NULL && j<i-1){ //如果i>lengh, p最后会等于NULL
p = p->next; //p指向下一个结点
j++;
}
if(p->next == NULL || j>i-1) //第i-1个结点之后已无其他结点
return false;
LNode *q = p->next; //令q指向被删除的结点
e = q->data; //用e返回被删除元素的值
p->next = q->next; //将*q结点从链中“断开”
free(q) //释放结点的存储空间
return true;
}
如果不带头结点,删除第1个元素,是否需要特殊处理?
bool ListDelete(LinkList &L, int i, ElemType &e) {
if (i < 1) return false;
LNode *p;
int j = 0;
// 特殊情况:删除第1个元素
if (i == 1) {
if (L == NULL) return false; // 链表为空
LNode *q = L; // q指向第1个结点
e = q->data; // 用e返回被删除元素的值
L = L->next; // 修改头指针L,指向第2个结点
free(q); // 释放第1个结点的内存
return true;
}
p = L; // p指向头结点
// 循环找到第i-1个结点
while (p != NULL && j < i - 1) {
p = p->next;
j++;
}
if (p == NULL || p->next == NULL) // 第i-1个结点之后已无其他结点
return false;
LNode *q = p->next; // 令q指向被删除的结点
e = q->data; // 用e返回被删除元素的值
p->next = q->next; // 将*q结点从链中“断开”
free(q); // 释放结点的存储空间
return true;
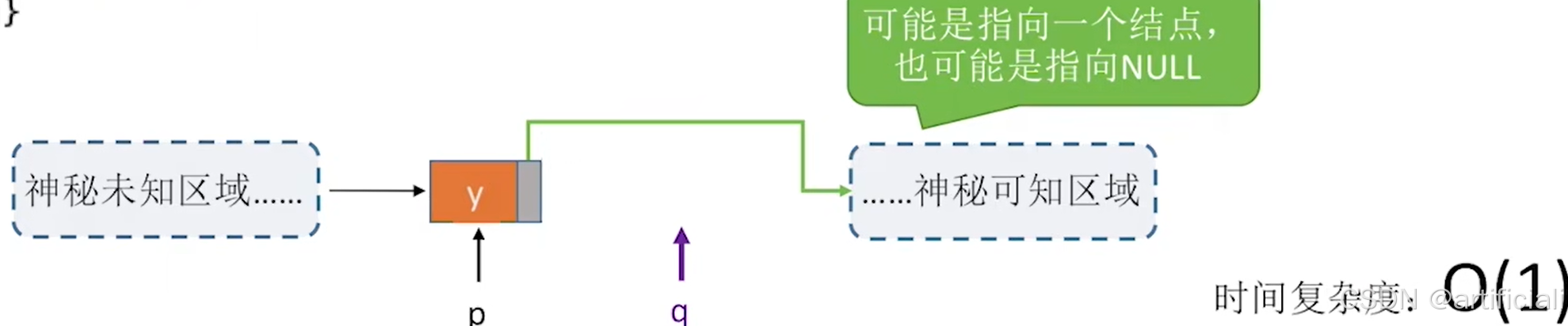
}指定结点的删除:
优点 O(1)
缺点:如果p是最后个结点,只能从表头开始依次寻找p的前驱,时间复杂度O(n)
类似前x,删除p节点,找到p后一个节点q,然后讲p=q,就是被覆盖了,然后再删除q。


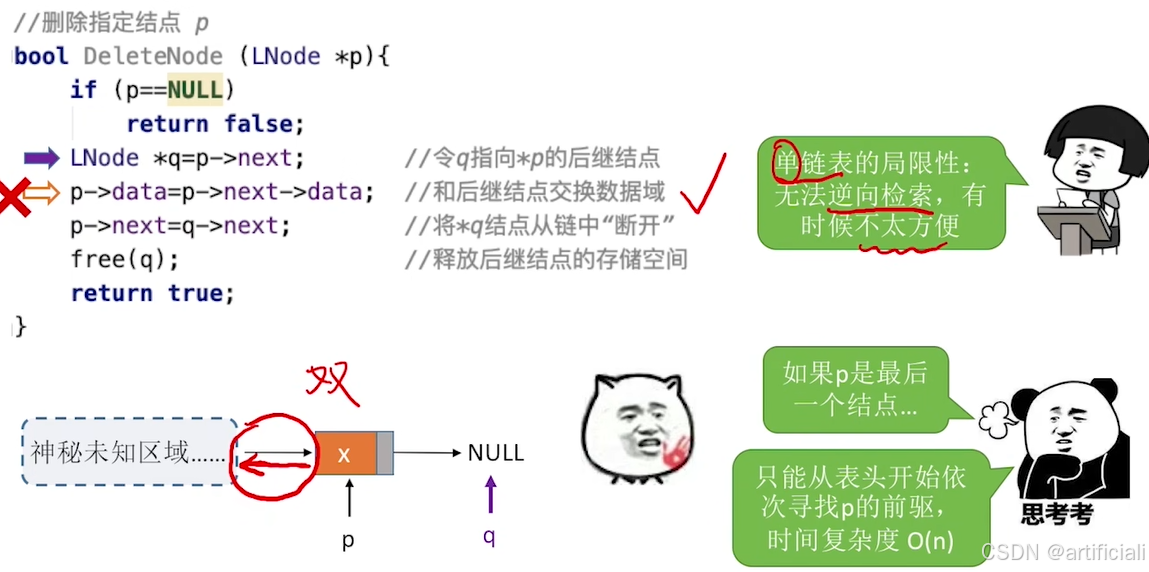
bool DeleteNode(LNode *p){
if(p==NULL)
return false;
LNode *q = p->next; //令q指向*p的后继结点
p->data = p->next->data; //让p和后继结点交换数据域
p->next = q->next; //将*q结点从链中“断开”
free(q);
return true;
} //时间复杂度 = O(1)
单链表的查找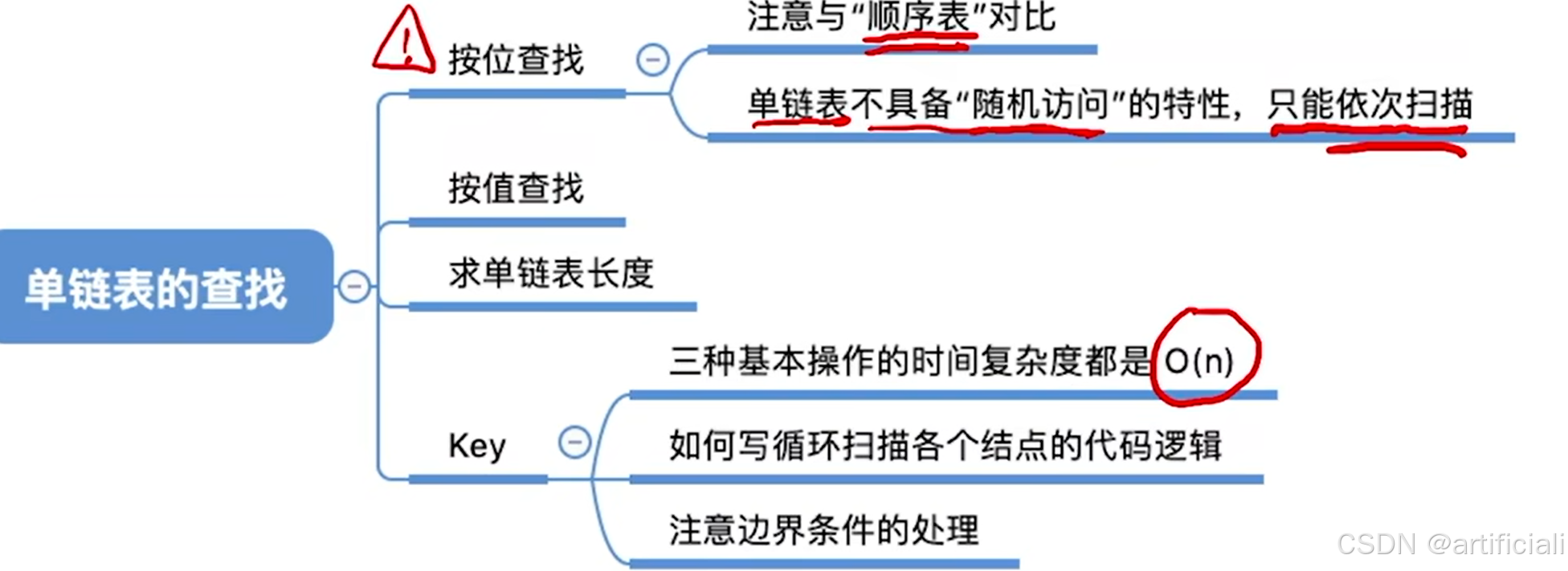
按位查找
LNode * GetElem(LinkList L, int i){
if(i<0) return NULL;
LNode *p; //指针p指向当前扫描到的结点
int j=0; //当前p指向的是第几个结点
p = L; //L指向头结点,头结点是第0个结点(不存数据)
while(p!=NULL && j<i){ //循环找到第i个结点
p = p->next;
j++;
}
return p; //返回p指针指向的值
}
按值查找
LNode * LocateElem(LinkList L, ElemType e){
LNode *P = L->next; //p指向第一个结点
//从第一个结点开始查找数据域为e的结点
while(p!=NULL && p->data != e){
p = p->next;
}
return p; //找到后返回该结点指针,否则返回NULL
}
单链表的建立
尾插法建立单链表
思路:每次将新节点插入到当前链表的表尾,所以必须增加一个尾指针r,使其始终指向当前链表的尾结点。好处:生成的链表中结点的次序和输入数据的顺序会一致。
// 使用尾插法建立单链表L
LinkList List_TailInsert(LinkList &L){
int x; //设ElemType为整型int
L = (LinkList)malloc(sizeof(LNode)); //建立头结点(初始化空表)
LNode *s, *r = L; //r为表尾指针
scanf("%d", &x); //输入要插入的结点的值
while(x!=9999){ //输入9999表示结束
s = (LNode *)malloc(sizeof(LNode));
s->data = x;
r->next = s;
r = s; //r指针指向新的表尾结点
scanf("%d", &x);
}
r->next = NULL; //尾结点指针置空
return L;
}头插法建立单链表
这个可以做链表逆置
LinkList List_HeadInsert(LinkList &L){ //逆向建立单链表
LNode *s;
int x;
L = (LinkList)malloc(sizeof(LNode)); //建立头结点
L->next = NULL; //初始为空链表,这步不能少!
scanf("%d", &x); //输入要插入的结点的值
while(x!=9999){ //输入9999表结束
s = (LNode *)malloc(sizeof(LNode)); //创建新结点
s->data = x;
s->next = L->next;
L->next = s; //将新结点插入表中,L为头指针
scanf("%d", &x);
}
return L;
}
链表的逆置
算法思想:逆置链表初始为空,原表中结点从原链表中依次“删除”,再逐个插入逆置链表的表头(即“头插”到逆置链表中),使它成为逆置链表的“新”的第一个结点,如此循环,直至原链表为空;
就是一个头断开,然后再次头插法
LNode *Inverse(LNode *L)
{
LNode *p, *q;
p = L->next; //p指针指向第一个结点
L->next = NULL; //头结点指向NULL
while (p != NULL){
q = p;
p = p->next;
q->next = L->next;
L->next = q;
}
return L;
}双链表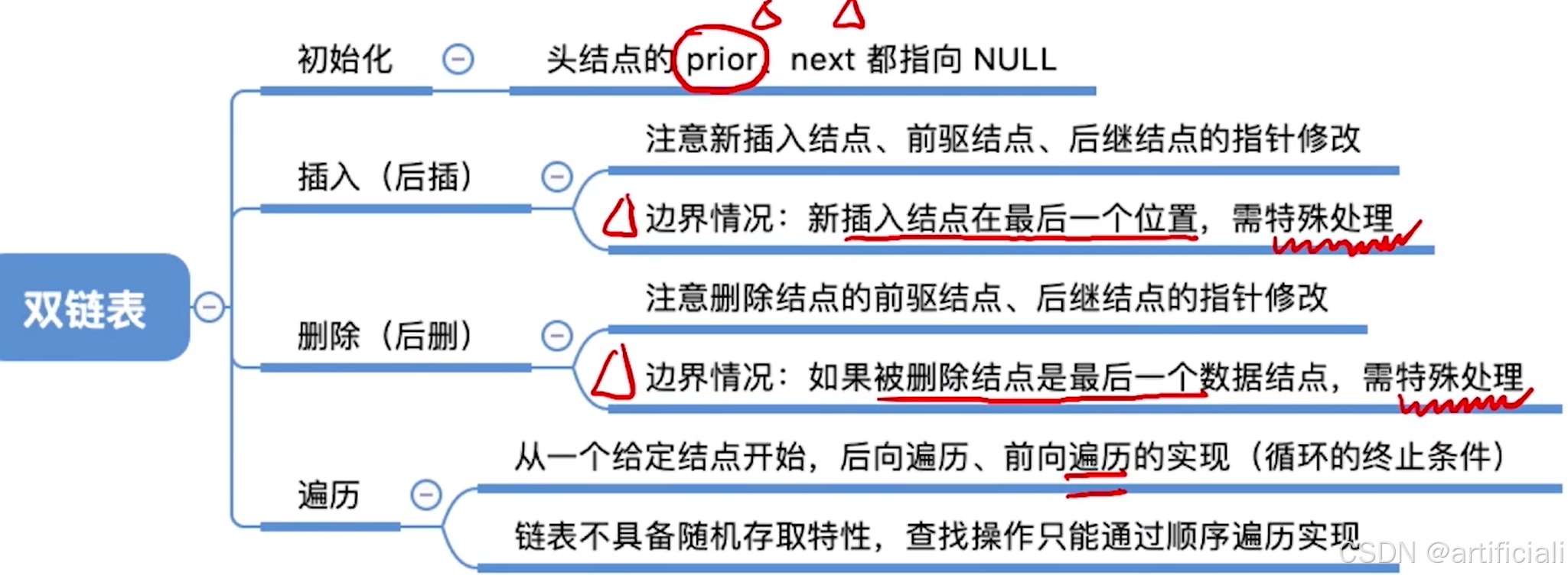
初始化
节点类型的描述
typedef struct DNode{ //定义双链表结点类型
ElemType data; //数据域
struct DNode *prior, *next; //前驱和后继指针
}DNode, *DLinklist;

双链表的初始化(带头结点)
typedef struct DNode{ //定义双链表结点类型
ElemType data; //数据域
struct DNode *prior, *next; //前驱和后继指针
}DNode, *DLinklist;
//初始化双链表
bool InitDLinkList(Dlinklist &L){
L = (DNode *)malloc(sizeof(DNode)); //分配一个头结点
if(L==NULL) //内存不足,分配失败
return false;
L->prior = NULL; //头结点的prior指针永远指向NULL
L->next = NULL; //头结点之后暂时还没有结点
return true;
}
void testDLinkList(){
//初始化双链表
DLinklist L; // 定义指向头结点的指针L
InitDLinkList(L); //申请一片空间用于存放头结点,指针L指向这个头结点
//...
}
//判断双链表是否为空
bool Empty(DLinklist L){
if(L->next == NULL) //判断头结点的next指针是否为空
return true;
else
return false;
}后插操作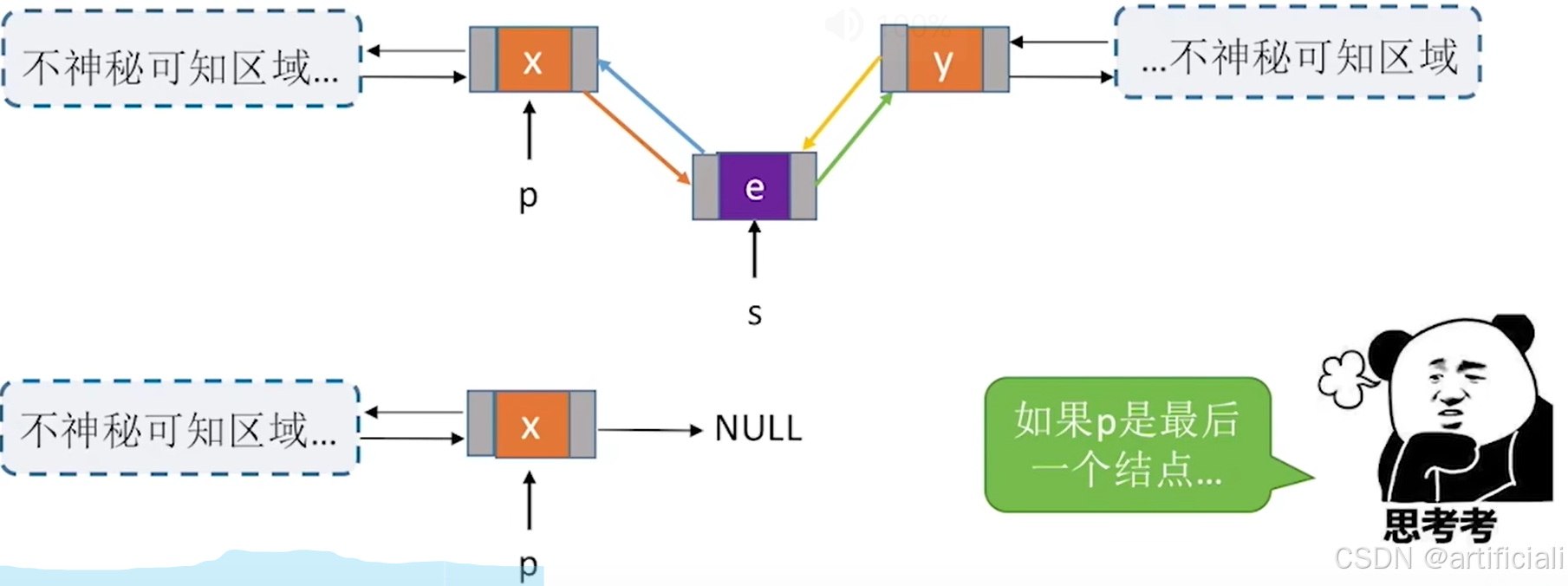
排除最后一个节点的潜在错误,直接指向p
InsertNextDNode(p, s): 在p结点后插入s结点
bool InsertNextDNode(DNode *p, DNode *s){ //将结点 *s 插入到结点 *p之后
if(p==NULL || s==NULL) //非法参数
return false;
s->next = p->next;
if (p->next != NULL) //p不是最后一个结点=p有后继结点
p->next->prior = s;
s->prior = p;
p->next = s;
return true;
}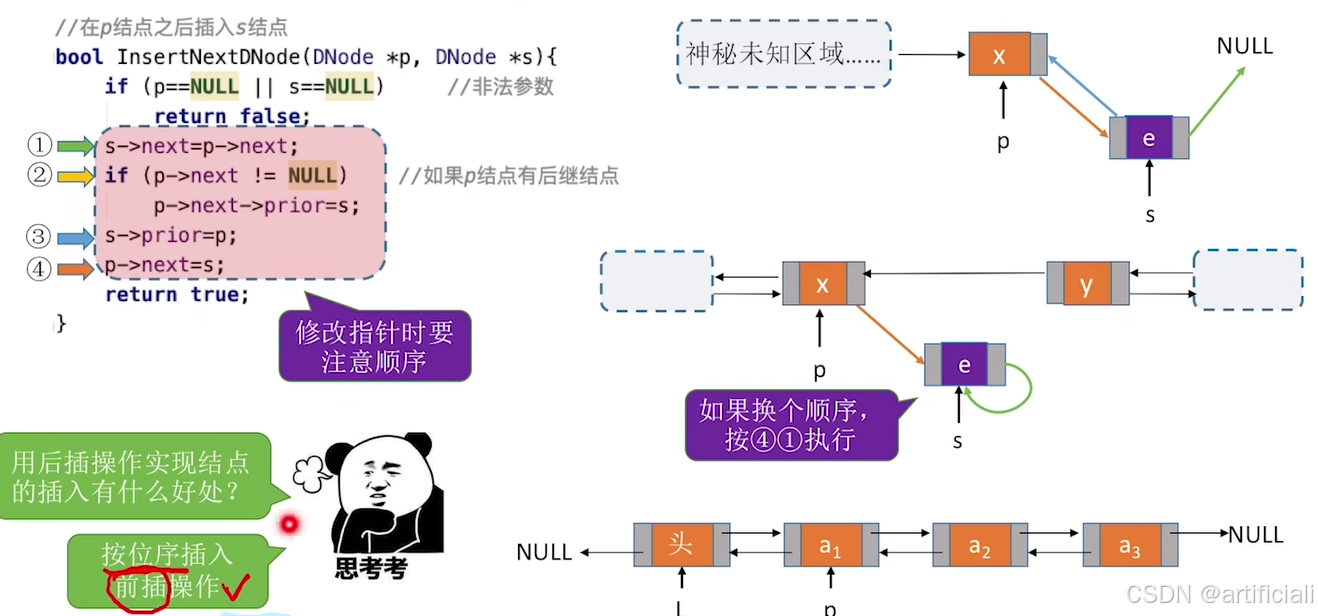
这个1、4不能颠倒
删除p节点的后继节点

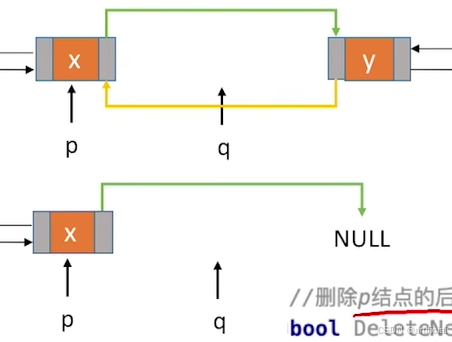
//删除p结点的后继结点
bool DeletNextDNode(DNode *p){
if(p==NULL) return false;
DNode *q =p->next; //找到p的后继结点q
if(q==NULL) return false; //p没有后继结点;
p->next = q->next;
if(q->next != NULL) //q结点不是最后一个结点
q->next->prior=p;
free(q);
return true;
}
//销毁一个双链表
bool DestoryList(DLinklist &L){
//循环释放各个数据结点
while(L->next != NULL){
DeletNextDNode(L); //删除头结点的后继结点
free(L); //释放头结点
L=NULL; //头指针指向NULL
}
}
遍历
前向遍历
while(p!=NULL){
//对结点p做相应处理,eg打印
p = p->prior;
}前向遍历跳过头节点:
从某个节点开始,向前遍历链表,但不处理头节点。因为这个头的前置节点是null
while (p-> prior != NULL)
//对结点p做相应处理
p = p->prior;
后向遍历
while(p!=NULL){
//对结点p做相应处理,eg打印
p = p->next;
}循环单链表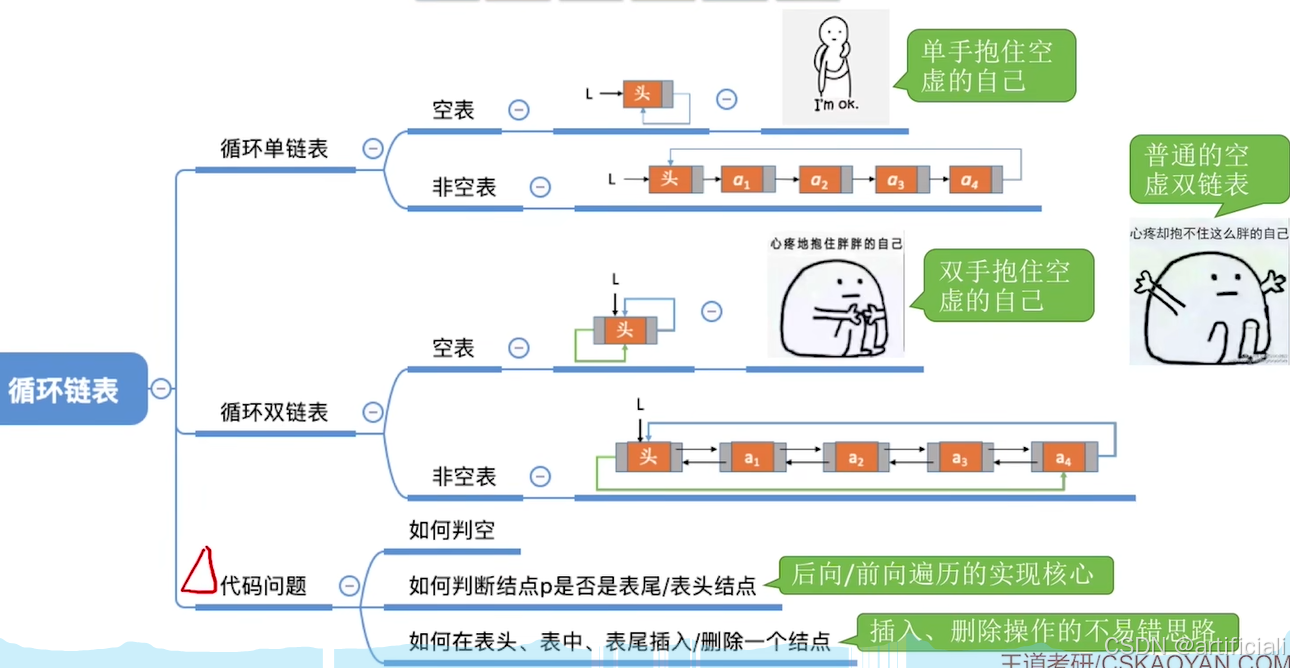
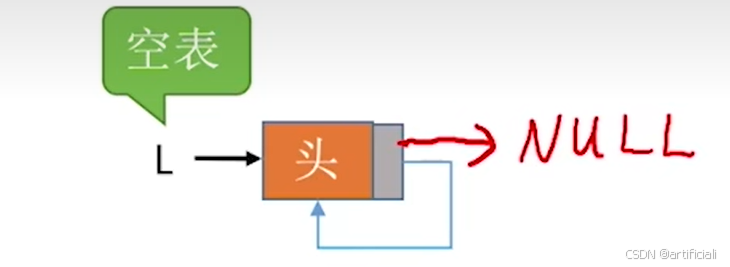
最后一个结点的指针不是NULL,而是指向头结点
typedef struct LNode{
ElemType data;
struct LNode *next;
}DNode, *Linklist;
//初始化一个循环单链表
bool InitList(LinkList &L){
L = (LNode *)malloc(sizeof(LNode)); //分配一个头结点
if(L==NULL) //内存不足,分配失败
return false;
L->next = L; //头结点next指针指向头结点
return true;
}
//判断循环单链表是否为空(终止条件为p或p->next是否等于头指针)
bool Empty(LinkList L){
if(L->next == L)
return true; //为空
else
return false;
}
//判断结点p是否为循环单链表的表尾结点
bool isTail(LinkList L, LNode *p){
if(p->next == L)
return true;
else
return false;
}| 特性 | 单链表 | 循环单链表 |
|---|---|---|
| 定义 | 每个节点包含数据和指向下一个节点的指针,最后一个节点指向 NULL。 | 每个节点包含数据和指向下一个节点的指针,最后一个节点指向头节点,形成闭环。 |
| 遍历方向 | 只能从头节点开始,向后遍历到尾节点。 | 可以从任意节点开始,遍历整个链表(闭环结构)。 |
| 头指针 vs 尾指针 | 通常只设置头指针,从头节点到尾节点需要遍历整个链表。 | 通常设置尾指针,通过尾指针可以直接访问头节点和尾节点,操作效率更高。 |
| 时间复杂度 | - 访问头节点:O(1) - 访问尾节点:O(n) - 插入/删除头节点:O(1) - 插入/删除尾节点:O(n) | - 访问头节点:O(1) - 访问尾节点:O(1) - 插入/删除头节点:O(1) - 插入/删除尾节点:O(1) |
| 优点 | - 结构简单,易于实现。 - 适合只需要单向遍历的场景。 | - 可以从任意节点遍历整个链表。 - 对表头和表尾的操作效率高(O(1))。 |
| 缺点 | - 无法从尾节点快速访问头节点。 - 对表尾的操作效率低(O(n))。 | - 实现稍微复杂,需要处理闭环逻辑。 - 如果不小心处理,可能导致死循环。 |
| 适用场景 | - 只需要单向遍历的场景。 - 对表头操作频繁的场景。 | - 需要频繁操作表头和表尾的场景。 - 需要从任意节点遍历整个链表的场景。 |
循环双链表
表头结点的prior指向表尾结点,表尾结点的next指向头结点
typedef struct DNode{
ElemType data;
struct DNode *prior, *next;
}DNode, *DLinklist;
//初始化空的循环双链表
bool InitDLinkList(DLinklist &L){
L = (DNode *) malloc(sizeof(DNode)); //分配一个头结点
if(L==NULL) //内存不足,分配失败
return false;
L->prior = L; //头结点的prior指向头结点
L->next = L; //头结点的next指向头结点
}
void testDLinkList(){
//初始化循环单链表
DLinklist L;
InitDLinkList(L);
//...
}
//判断循环双链表是否为空
bool Empty(DLinklist L){
if(L->next == L)
return true;
else
return false;
}
//判断结点p是否为循环双链表的表尾结点
bool isTail(DLinklist L, DNode *p){
if(p->next == L)
return true;
else
return false;
}
插入
bool InsertNextDNode(DNode *p, DNode *s){
s->next = p->next;
p->next->prior = s;
s->prior = p;
p->next = s;删除
//删除p的后继结点q
p->next = q->next;
q->next->prior = p;
free(q);循环双链表实现约瑟夫环
有头
#include <iostream>
using namespace std;
int n, k;
typedef struct node {
struct node * next,*pr;
int data;
}Node,*Link;
bool initialize(Link &a) {
a = (Node *)malloc(sizeof(Node));
if (a == NULL) return false;
a->next = a;
a->pr = a;
return 1;
}
bool Empty(Link &L) {
if (L->next == L) return 1;
else return false;
}
//尾插
Link Insert(Link &L) {
int x;
//L = (Node *)malloc(sizeof(Node));//在同一个完整代码多余
Node *p = L;
for(int i=1;i<=n;i++){
Node * s = (Node*)malloc(sizeof(Node));
s->next =L;//最后一个指向头节点
p->next = s;
s->pr = p;
L->pr = s;//头节点指向最后一个元素
s->data = i;
//移动p
p = s;
}
return L;
}
//删除
void del(Link &L) {
Node* current = L->next;//第一个
int remaining = n;
while (remaining > 1) {
// 找到第k个节点(移动k-1次)
for (int i = 1; i < k; ++i) {
current = current->next;
if (current == L) { // 如果遇到头节点,跳过
current = current->next;
}
}
//删除
Node *temp = current;
current->next->pr = current->pr;
current->pr->next = current->next;
current = current->next;// 将 current 移动到下一个节点
if (current == L) { // 如果遇到头节点,跳过再下一个
current = current->next;
}
free(temp);//交换顺序出现错误
remaining--;
}
// 输出最后剩下的节点
cout << current->data << endl;
L = current;
}
int main()
{
cin >> n >> k;
Link L;
initialize(L);
Insert(L);
del(L);
return 0;
}无头
#include <iostream>
using namespace std;
int n, k;
typedef struct node {
struct node *next, *pr;
int data;
} Node, *Link;
bool initialize(Link &a) {
a = NULL; // 初始化为空链表
return true;
}
Link Insert(Link &L) {
if (n < 1) return L;
// 创建第一个节点
L = new Node;
L->data = 1;
L->next = L;
L->pr = L;
Node *p = L;
for (int i = 2; i <= n; i++) {
Node *s = new Node;
s->data = i;
// 将新节点插入到链表尾部
s->next = L; // 新节点的next指向头节点
s->pr = p; // 新节点的前驱指向当前尾节点p
p->next = s; // 当前尾节点的next指向新节点
L->pr = s; // 头节点的前驱指向新尾节点
p = s; // 更新尾节点指针
}
return L;
}
void josephus(Link &L) {
if (!L || n == 0) return;
Node *current = L;
int remaining = n;
while (remaining > 1) {
// 找到第k个节点(移动k-1次)
for (int i = 1; i < k; ++i) {
current = current->next;
}
// 移除当前节点
Node *prev = current->pr;
Node *nextNode = current->next;
// 调整前后节点的指针
prev->next = nextNode;
nextNode->pr = prev;
// 释放当前节点并移动到下一个节点
Node *temp = current;
current = nextNode;
delete temp;
remaining--;
}
// 输出最后剩下的节点
cout << current->data << endl;
L = current;
}
int main() {
cin >> n >> k;
Link L = NULL;
initialize(L);
Insert(L);
josephus(L);
return 0;
}静态链表
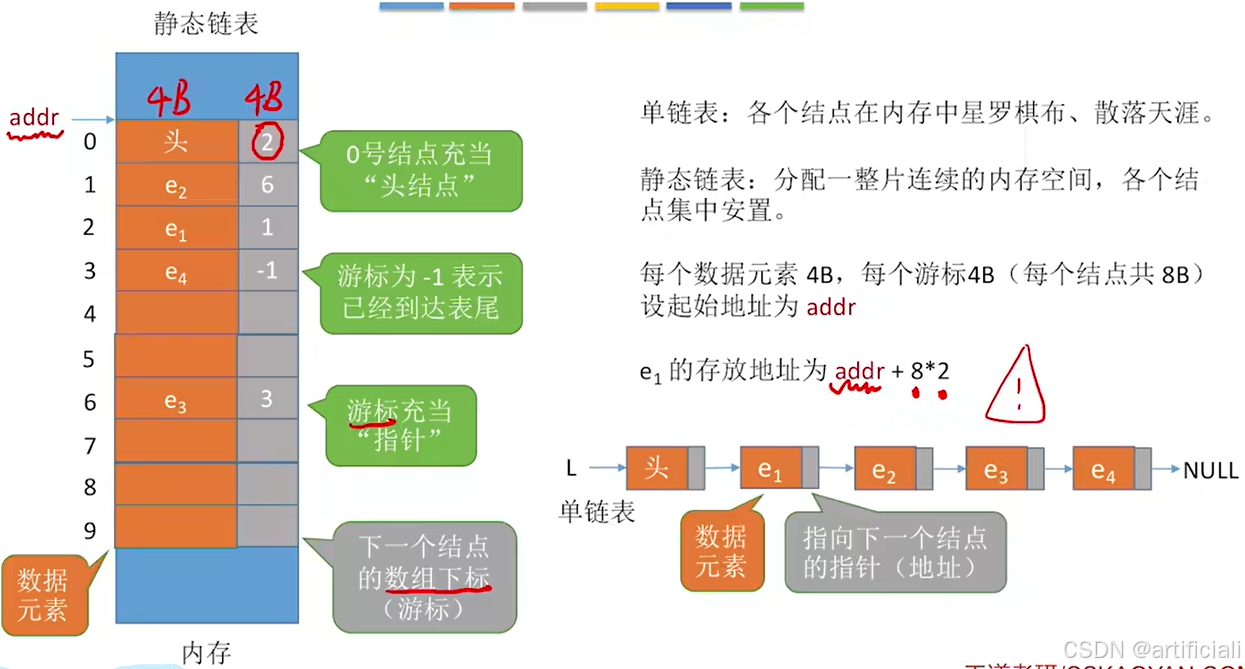
静态链表:用数组的方式实现的链表
优点:增、删操作不需要大量移动元素
缺点:不能随机存取,只能从头结点开始依次往后查找;容量固定不可变
适用场景:①不支持指针的低级语言;②数据元素数量固定不变的场景(如操作系统的文件分配表FAT)
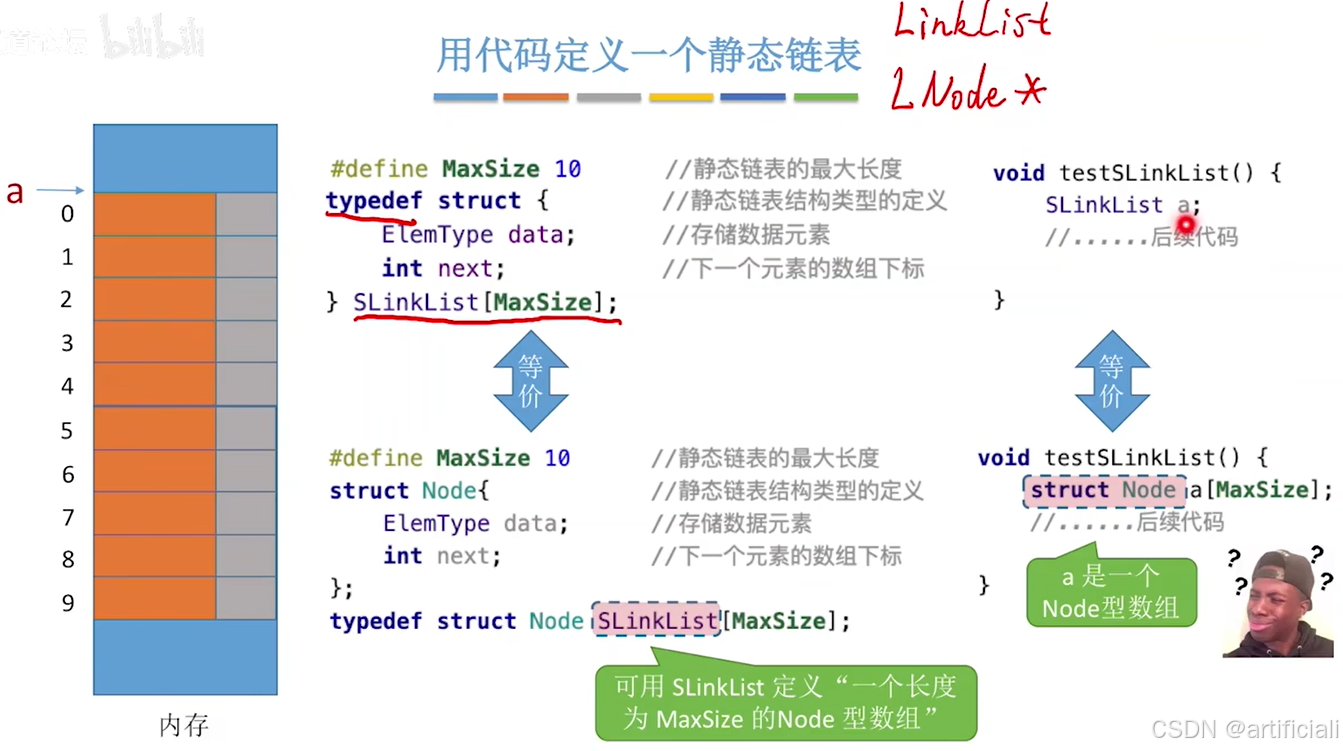
静态链表用代码表
图二实现的两种方式代码
#define MaxSize 10 //静态链表的最大长度
struct Node{ //静态链表结构类型的定义
ElemType data; //存储数据元素
int next; //下一个元素的数组下标(游标)
};
//用数组定义多个连续存放的结点
void testSLinkList(){
struct Node a[MaxSize]; //数组a作为静态链表, 每一个数组元素的类型都是struct Node
//...
}或者
#define MaxSize 10 //静态链表的最大长度
typedef struct{ //静态链表结构类型的定义
ELemType data; //存储数据元素
int next; //下一个元素的数组下标
}SLinkList[MaxSize];
void testSLinkList(){
SLinkList a;
}等价于
#define MaxSize 10 //静态链表的最大长度
struct Node{ //静态链表结构类型的定义
ElemType data; //存储数据元素
int next; //下一个元素的数组下标(游标)
};
typedef struct Node SLinkList[MaxSize]; //重命名struct Node,用SLinkList定义“一个长度为MaxSize的Node型数组;
#include <stdio.h>
#define MAX_SIZE 10
#define EMPTY -2
#define END -1
typedef struct {
int data;
int next;
} Node;
Node nodes[MAX_SIZE];
int head;
void initializeList() {
head = 0; // 头节点
nodes[head].next = END; // 初始时链表为空
for (int i = 1; i < MAX_SIZE; i++) {
nodes[i].next = EMPTY; // 标记为空节点
}
}
//找到空节点的下标
int findEmptyNode() {
for (int i = 1; i < MAX_SIZE; i++) {
if (nodes[i].next == EMPTY) {
return i;
}
}
return -1; // 没有空节点
}
//插入新节点的位置 位置从0开始
void insert(int index, int data) {
if (index < 1) {
printf("插入位置必须大于0\n");
return;
}
int emptyNode = findEmptyNode();//找到空节点的下标
if (emptyNode == -1) {
printf("链表已满,无法插入\n");
return;
}
int prev = head;//从链表的头部开始遍历
for (int i = 0; i < index - 1; i++) {//找到插入位置的前一个节点
prev = nodes[prev].next;
if (prev == END) {
printf("插入位置超出链表长度\n");
return;
}
}
nodes[emptyNode].data = data;
nodes[emptyNode].next = nodes[prev].next;
nodes[prev].next = emptyNode;
}
void deleteNode(int index) {
if (index < 1) {
printf("删除位置必须大于0\n");
return;
}
int prev = head;
for (int i = 0; i < index - 1; i++) {
prev = nodes[prev].next;
if (prev == END) {
printf("删除位置超出链表长度\n");
return;
}
}
int current = nodes[prev].next;
if (current == END) {
printf("删除位置超出链表长度\n");
return;
}
nodes[prev].next = nodes[current].next;
nodes[current].next = EMPTY; // 标记为空节点
}
void printList() {
int current = nodes[head].next;
while (current != END) {
printf("%d -> ", nodes[current].data);
current = nodes[current].next;
}
printf("NULL\n");
}
int main() {
initializeList();
insert(1, 10);
insert(2, 20);
insert(3, 30);
printList(); // 输出: 10 -> 20 -> 30 -> NULL
deleteNode(2);
printList(); // 输出: 10 -> 30 -> NULL
return 0;
}顺序表和链表的比较

可以围绕这个框架答题。比如:逻辑结构、存储结构、基本操作
| 特性 | 顺序表 | 链表 |
|---|---|---|
| 存储结构 | 顺序存储 | 链式存储 |
| 优点 | 支持随机存取,存储密度高 | 离散的小空间分配方便,容量改变方便 |
| 缺点 | 需要连续空间,容量不易扩展 | 不支持随机存取,存储密度低,操作不便 |
| 创建方式 | 静态分配(静态数组,容量不可变),动态分配(动态数组,容量可变) | 只需要分配一个头结点或声明一个头指针 |
| 销毁方式 | 静态数组系统自动回收;动态数组需要手动释放内存(free) | 需要手动释放每个节点的内存空间 |
| 增/删操作 | 时间复杂度:O(n),需要移动大量元素(后移/前移) | 时间复杂度:O(n),需要查找目标元素再修改指针 |
| 查找操作 | 按位查找:O(1),按值查找:O(n);若有序则为O(log2n) | 按位查找:O(n),按值查找:O(n) |
| 存储方式特点 | 连续存储,逻辑顺序与物理顺序一致,存储密度大,空间利用率高 | 非连续存储,通过指针连接各个节点 |
| 空间分配 | 固定大小或动态扩展(需要预留空间) | 动态分配空间,按需分配,每个节点占用不同空间 |
顺序、链式、静态、动态四种存储方式的比较
- 顺序存储的固有特点:逻辑顺序与物理顺序一直,本质上是用数组存储线性表的各个元素(即随机存取);存储密度大,存储空间利用率高。
- 静态存储的固有特点:在程序运行的过程中不要考虑追加内存的分配问题。动态存储的固有特点:
- 可动态分配内存;有效的利用内存资源,使程序具有可扩展性。
- 链式存储的固有特点:元素之间的关系采用这些元素所在的节点的“指针”信息表示(插、删不需要移动节点)。
表长难以预估、经常要增加/删除元素 一一链表
表长可预估、查询(搜索)操作较多 一一顺序表
补充
结构体比较
结构体元素的比较需要手动进行,因为结构体本身不支持直接使用 == 或 != 等运算符进行比较。
-
bool arePointsEqual(struct Point p1, struct Point p2) { return p1.x == p2.x && p1.y == p2.y; } -
struct Point { int x; int y; bool operator==(const Point& other) const { return x == other.x && y == other.y; } };
DNode L; 和 DLinklist L; 的区别
-
DNode L;:-
这里
L是一个DNode类型的变量,即一个具体的双链表结点。 -
L是一个结构体变量,它在栈上分配内存,存储的是一个结点的数据(data、prior和next)。 -
L不是一个指针,因此不能通过L来动态管理链表的内存(例如分配或释放结点)。
-
-
DLinklist L;:-
这里
L是一个DLinklist类型的变量,即一个指向DNode的指针。 -
L是一个指针变量,它可以指向动态分配的内存(例如通过malloc分配的头结点)。 -
L用于表示链表的头指针,通过它可以访问整个链表。
-
因此这里只能是
void testDLinkList() {
DLinklist L; // 定义指向头结点的指针 L
InitDLinkList(L); // 申请一片空间用于存放头结点,指针 L 指向这个头结点
// ...
}
为什么要L等于malloc,我们这个L不是初始化就分配空间了吗?
在函数 List_TailInsert 中,L 是一个指向单链表头结点的指针(即 LinkList 类型)。在调用该函数时,L 可能是一个未初始化的指针,指向一个随机的内存地址,而不是一个有效的链表头结点。因此,L = (LinkList)malloc(sizeof(LNode)); 的作用是显式地为头结点分配内存,确保 L 指向一个合法的头结点。这是初始化链表的关键步骤。
-
L = (LinkList)malloc(sizeof(LNode));的作用:-
为头结点分配内存,初始化链表。
-
确保
L是一个合法的指针,指向一个有效的头结点。
-
-
为什么需要
malloc:-
链表是动态数据结构,需要在运行时动态分配内存。
-
头结点是链表的起点,必须显式分配内存。
-
-
如果没有
malloc:-
L是未初始化的指针,访问它会导致程序崩溃。
-
双链表后插
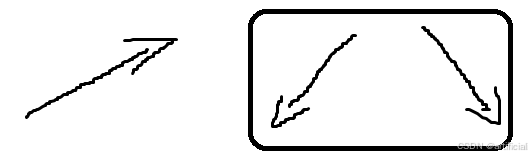 必须是这个顺序,书中的后插。题中的前插不符合
必须是这个顺序,书中的后插。题中的前插不符合
参考推荐:


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









