






 本文围绕Linux的I/O机制展开,介绍了I/O在Linux中的生命周期,包括vfs层、文件系统层等各层任务;阐述了NOOP、CFQ、Deadline等常见I/O调度器及不同磁盘的调度器选择;还提及多队列机制提升I/O处理性能,以及epoll系统调用实现I/O多路复用。
本文围绕Linux的I/O机制展开,介绍了I/O在Linux中的生命周期,包括vfs层、文件系统层等各层任务;阐述了NOOP、CFQ、Deadline等常见I/O调度器及不同磁盘的调度器选择;还提及多队列机制提升I/O处理性能,以及epoll系统调用实现I/O多路复用。
计算机从诞生之日起就和输入输出(I/O)密不可分,图灵机和冯 · 诺伊曼体系中输入与输出就是基本概念之一。图灵机是一个计算机的理论模型,本质上是状态机;冯 · 诺伊曼体系是图灵机的实现,包括运算、控制、存储、输入、输出五个部分。冯 · 诺伊曼体系相对之前的计算机最大的创新在于程序和数据的存储,以此实现机器内部编程,如图5-1所示。
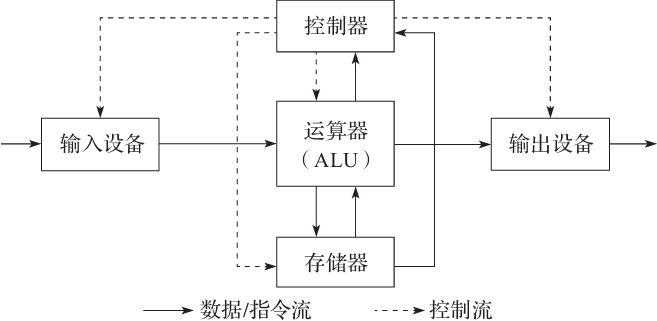
图5-1 冯 · 诺伊曼计算机体系结构
我们平时编写的应用程序除了纯粹的 CPU 密集型计算外(比如 3D 渲染等),都和 I/O 有密不可分的关系,比如数据库查询、缓存查询等,了解 Linux 对 I/O 的实现对我们编写出更好的应用程序有很大的帮助。
本章介绍的 I/O 机制,从操作系统层面来讲是广义的 I/O 架构,主要围绕 read/write 系统调用,从读写文件到最终转换成 block 块写入磁盘等设备。
本章将介绍以下内容:
I/O 在 Linux 中的生命周期,以及在如下层中完成的任务:vfs、文件系统、页面缓存、block、scsi 层等。
I/O 相关的调度器,以及不同场景应该选择哪个调度器。
多队列机制。
I/O 多路复用实现。
一些开源系统和操作系统中与 I/O 相关调用的实现。
5.1 I/O 在 Linux 中的生命周期
现在我们已经知道输入输出对计算机的重要性,那么下面就介绍 Linux 的 I/O 实现,并分析一个 I/O 是如何产生并且是如何完成使命的。
5.1.1 vfs 层
要了解 I/O 的产生,最直观的就是 read、write 等系统调用。在这里,我们需要注意一个比较重要的概念:对于 Linux 来讲,一切都是文件,所以进行 I/O 读写操作的时候,如读写磁盘或其他设备,都会和 vfs 层挂钩。
Linux 为了屏蔽底层文件系统和驱动程序等细节,对文件的操作首先通过 vfs 接口层来转发系统调用的 open、read、write、close 等请求,如图5-2所示。限于篇幅,下面仅围绕 read 和 write 请求来分析读 I/O 的来龙去脉。
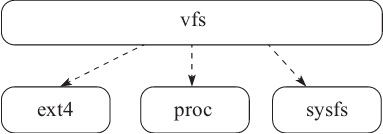
图5-2 vfs 接口层
下面是 read 调用的实现(代码详见:Linux/fs/red_write.c):
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
struct fd f = fdget_pos(fd); // 获取当前进程下指定的 fd 文件句柄
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos = file_pos_read(f.file); // 获取当前文件已经读取的位置
ret = vfs_read(f.file, buf, count, &pos);
if (ret >= 0)
file_pos_write(f.file, pos); // 保存最新的读取位置
fdput_pos(f); // 有必要的情况下释放 fd 中的 file 结构
}
return ret;
}
sys_read 执行的时候,首先获取当前文件已经读取的位置,然后调用 vfs 层的 vfs_read,在 vfs_read 中校验文件是否可读,要访问的 buf 内存块是否可用,文件读取的位置是否越界,权限检测等。然后 __vfs_read 调用真正的文件系统层进行 read 操作:
ssize_t __vfs_read(struct file *file, char __user *buf, size_t count,
loff_t *pos)
{
if (file->f_op->read)
return file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
return new_sync_read(file, buf, count, pos);
else
return -EINVAL;
}
在新版本的内核中,vfs_read 操作的逻辑在 new_sync_read 中,因为 ext4 文件系统注册的是 read_iter 方法,具体过程我们后面分析,在 new_sync_read 中最终执行了 file->f_op->read_iter,把控制权交给了 ext4 之类的文件系统。
所以可以把 vfs 理解为是 Linux 对上层提供的统一文件系统的抽象,底层有不同的实现,比如 ext4、proc、sysfs 等,这也是 Linux 一切皆是文件的原因。
5.1.2 文件系统层
通过 read 在 vfs 层中的执行,我们发现最终会调用具体文件系统的操作。这里我们以 ext4 文件系统为例,其文件操作函数在 /linux-4.5.2/fs/ext4/file.c 中注册:
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read_iter = generic_file_read_iter,
.write_iter = ext4_file_write_iter,
.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext4_compat_ioctl,
#endif
.mmap = ext4_file_mmap,
.open = ext4_file_open,
.release = ext4_release_file,
.fsync = ext4_sync_file,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = ext4_fallocate,
};
在 ext4_iget 初始化 inode 的时候会进行注册:
…
if (S_ISREG(inode->i_mode)) {
inode->i_op = &ext4_file_inode_operations;
inode->i_fop = &ext4_file_operations;
ext4_set_aops(inode);
…
然后在 vfs_open 打开文件的时候调用了 do_dentry_open:
f->f_op = fops_get(inode->i_fop);
至此彻底搞清楚了,ext4 的 read 和 write 文件最终委托给了:
.read_iter = generic_file_read_iter,
.write_iter = ext4_file_write_iter,
同理,sys_write 的系统调用过程为:sys_write->vfs_write->__vfs_write->new_sync_write,并且在 new_sync_write 函数中的 filp->f_op->write_iter 其实就是 ext4_file_write_iter。其实现为:
static ssize_t
ext4_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct file *file = iocb->ki_filp;
struct inode *inode = file_inode(iocb->ki_filp); // 获取文件的 inode
struct mutex *aio_mutex = NULL;
struct blk_plug plug;
int o_direct = iocb->ki_flags & IOCB_DIRECT; // IO Driect 标志
int overwrite = 0;
ssize_t ret;
/*
* 未对齐(针对 block)的异步 IO 必须顺序进行
*/
if (o_direct &&
ext4_test_inode_flag(inode, EXT4_INODE_EXTENTS) &&
!is_sync_kiocb(iocb) &&
(iocb->ki_flags & IOCB_APPEND ||
ext4_unaligned_aio(inode, from, iocb->ki_pos))) {
aio_mutex = ext4_aio_mutex(inode);
mutex_lock(aio_mutex);
ext4_unwritten_wait(inode); // 进入等待队列,直到 inode 的 i_unwritten 状态 // 变成0(说明前面的一个 IO 完成了)
}
inode_lock(inode);
ret = generic_write_checks(iocb, from); // 进行写入权限的校验工作
if (ret <= 0)
goto out;
if (!(ext4_test_inode_flag(inode, EXT4_INODE_EXTENTS))) { // 非 extends 类型的文件
struct ext4_sb_info *sbi = EXT4_SB(inode->i_sb);
if (iocb->ki_pos >= sbi->s_bitmap_maxbytes) { // ki_pos必须小于s_bitmap_
maxbytes
ret = -EFBIG;
goto out;
}
iov_iter_truncate(from, sbi->s_bitmap_maxbytes - iocb->ki_pos);// 如果读取的大小 count(from→count)超过了上限,count 变为:sbi->s_bitmap_maxbytes-iocb->ki_pos
}
iocb->private = &overwrite;
if (o_direct) { // 假如是 directIO 的情况
size_t length = iov_iter_count(from);
loff_t pos = iocb->ki_pos;
// 初始化 plug,blk_plug 构建了一个缓存碎片 IO 的请求队列。用于将顺序请求合并成一个大的请求。合并后请求批量从 per-task 链表移动到设备请求队列,减少了设备请求队列锁竞争,从而提高了效率。
blk_start_plug(&plug);
// 校验是否进行 Direct-IO
if (ext4_should_dioread_nolock(inode) && !aio_mutex &&
!file->f_mapping->nrpages && pos + length <= i_size_read(inode)) {
struct ext4_map_blocks map;
unsigned int blkbits = inode->i_blkbits; // 文件块位数
int err, len;
map.m_lblk = pos >> blkbits; // 右移获取起始逻辑块号,总共要读取的块的数量,并且对齐
map.m_len = (EXT4_BLOCK_ALIGN(pos + length, blkbits) >> blkbits)
\- map.m_lblk;
len = map.m_len;
err = ext4_map_blocks(NULL, inode, &map, 0); // 查找逻辑块号和物理块号之间的映射关系,该函数在文件系统中还需要详细追述
if (err == len && (map.m_flags & EXT4_MAP_MAPPED))// 所有的 block 已经初始化,并且为 EXT4_MAP_MAPPED 状态
overwrite = 1;
}
}
ret = __generic_file_write_iter(iocb, from); // 把数据写入文件
inode_unlock(inode);
if (ret > 0) {
ssize_t err;
err = generic_write_sync(file, iocb->ki_pos - ret, ret); // 同步数据到磁盘
if (err < 0)
ret = err;
}
if (o_direct)
blk_finish_plug(&plug);
…
return ret;
}
上述过程看起来很长,其实总结出来就以下几步:
1)状态、权限校验。
2)把数据写入文件。
3)同步数据到磁盘。
在上述代码中,__generic_file_write_iter 可谓承上启下,尤其重要:
ssize_t __generic_file_write_iter(struct kiocb *iocb, struct iov_iter *from)
{
struct file *file = iocb->ki_filp;
struct address_space * mapping = file->f_mapping;
struct inode *inode = mapping->host;
ssize_t written = 0;
ssize_t err;
ssize_t status;
current->backing_dev_info = inode_to_bdi(inode); // 获取设备描述信息
err = file_remove_privs(file); // 移除 SUID
…
err = file_update_time(file); // 更新文件时间
…
if (iocb->ki_flags & IOCB_DIRECT) {
loff_t pos, endbyte;
// 进行 directIO
written = generic_file_direct_write(iocb, from, iocb->ki_pos);
…
// 写页面缓存
status = generic_perform_write(file, from, pos = iocb->ki_pos);
…
endbyte = pos + status - 1;
// 把脏页写入到磁盘
err = filemap_write_and_wait_range(mapping, pos, endbyte);
…
} else {
// 非 DIO 场景,直接写 Page Cache
written = generic_perform_write(file, from, iocb->ki_pos);
if (likely(written > 0))
iocb->ki_pos += written;
}
…
return written ? written : err;
}
以上过程分为页面缓存和 DirectIO 两种场景,下面分别进行介绍。
1.页面缓存
我们先来分析上节代码中 else 部分,写页面缓存(Page Cache)。为了减少块设备层的工作压力,Linux 通过局部性原理来使用页面缓存提高性能。
下面来分析页面缓存写入过程,其实现是由 generic_perform_write 完成的,以页为单位进行 do..while 循环操作,该循环过程为:
1)计算在写入页中的 offset 和写入的字节数:
offset = (pos & (PAGE_CACHE_SIZE - 1)); // 计算在该页中的 offset
bytes = min_t(unsigned long, PAGE_CACHE_SIZE - offset,
iov_iter_count(i)); // 计算需要写入该页的字节
2)调用 a_ops->write_begin 函数准备该空间中对应 index 需要的 page,我们看 ext4 的实现 ext4_write_begin。其中,关键的一步为 grab_cache_page_write_begin,这个步骤用于查找获取一个缓存页或者创建一个缓存页,其执行过程如下:
struct page *grab_cache_page_write_begin(struct address_space *mapping,
pgoff_t index, unsigned flags)
{
struct page *page;
…
page = pagecache_get_page(mapping, index, fgp_flags,
mapping_gfp_mask(mapping));
if (page) // 等待该 page writeback 完成
wait_for_stable_page(page);
return page;
}
pagecache_get_page 最为关键,它从 mapping 的基树中查找缓存页,假如不存在,则从伙伴系统中申请一个新页插入,并且添加到 LRU 链表中:
struct page *pagecache_get_page(struct address_space *mapping, pgoff_t offset,
int fgp_flags, gfp_t gfp_mask)
{
struct page *page;
repeat:
page = find_get_entry(mapping, offset);
if (radix_tree_exceptional_entry(page)) // 改 slot 页状态异常
page = NULL;
if (!page)
goto no_page;
…
if (page && (fgp_flags & FGP_ACCESSED))
mark_page_accessed(page);
no_page:
…
page = __page_cache_alloc(gfp_mask); // 到伙伴系统中申请新的页面
if (!page)
return NULL;
…
if (fgp_flags & FGP_ACCESSED)
__SetPageReferenced(page);
err = add_to_page_cache_lru(page, mapping, offset,
gfp_mask & GFP_RECLAIM_MASK); // 把新的页插入到基树中,并且插入到 LRU 链表
if (unlikely(err)) {
page_cache_release(page);
page = NULL;
if (err == -EEXIST)
goto repeat;
}
}
return page;
}
3)iov_iter_copy_from_user_atomic(page,i,offset,bytes);把数据从用户缓冲区复制到 page 中。
4)调用 a_ops->write_end,ext4_write_end 函数首先调用 block_write_end 函数,其中调用 __block_commit_write 提交写入的数据,但事实上该提交只是对 buff 的状态做了处理,并没有其他大的操作。
在 __block_commit_write 中会调用 set_buffer_uptodate(bh);函数,其关键步骤如下:
mark_buffer_dirty(bh)->mark_buffer_dirty->__set_page_dirty,将该页设为脏。
mark_buffer_dirty(bh)->mark_buffer_dirty->__mark_inode_dirty->wb_wakeup_delayed 把 writeback 任务提交到 bdi_writeback 队列中。
其中,把页面标记为脏的原因是因为还未写入到磁盘,数据和磁盘还不一致。
上面的 write 过程把要写的 page 提交到了 bdi_writeback 队列中,然后由 writeback 线程将其真正写到 block device 上。
writeback 机制的好处总结起来主要有两点:
加快 write()的响应速度。因为磁盘的读写相对于内存访问是较慢的。如果每个 write()都访问磁盘,势必很慢。将较慢的磁盘访问交给 writeback 线程,而 write()本身的线程里只在内存里操作数据,将数据交到 writeback queue 即返回。
便于合并和排序多个 write 操作,合并(merge)是将多个少量数据的 write 合并成几个大量数据的 write,减少访问磁盘的次数;排序(sort)是将无序的 write 按照其访问磁盘上的 block 的顺序排序,减少磁头在磁盘上的移动距离。
writeback 是文件系统的概念,writeback 是指文件(即 inode)的部分数据由 writeback 线程写入磁盘。这里就产生一个问题,一个磁盘上可能有多个文件系统,如 sda1 上是 ext4,sda2 上是 fat,但其实是在一个硬盘 sda 上,如果分别由不同的线程对 sda1、sda2 进行 writeback 操作的话,上面所说的排序(sort)功能将没有意义,因为可能 thread1 写了一会儿 sda1,thread2 又要把磁头移到别的地方去写 sda2 了。鉴于此,设计 writeback 机制时,writeback 的主体应该是 sda,而不是 sda1、sda2。这就是 backing device 的概念。sda 是 sda1 上 ext4,sda2 上 fat 的 backing device,sda1 和 sda2 的 writeback 都应该由 sda 的 write-back 线程来完成。
bdi 的全称是 backing device info,它代表了一个 backing device。每个文件系统在 mount 的时候,就将它的 backing device 记录到 super->s_bdi 中。如果 backing device 是个 block device,那么其 inode 所在的 backing device 被记录到 super->s_bdev->bd_inode->i_mapping->backing_dev_info 中。
bdi 的初始化通过 bdi_init 方法完成:
int bdi_init(struct backing_dev_info *bdi)
{
int ret;
bdi->dev = NULL;
bdi->min_ratio = 0;
bdi->max_ratio = 100;
bdi->max_prop_frac = FPROP_FRAC_BASE;
INIT_LIST_HEAD(&bdi->bdi_list);
INIT_LIST_HEAD(&bdi->wb_list);
init_waitqueue_head(&bdi->wb_waitq);
ret = cgwb_bdi_init(bdi);
list_add_tail_rcu(&bdi->wb.bdi_node, &bdi->wb_list);
return ret;
}
其中:
cgwb_bdi_init->wb_init:INIT_DELAYED_WORK(&wb->dwork,wb_workfn);初始化了一个 delayed_work 线程来处理 writeback 请求。
wb_workfn 函数用于处理提交给 wb 线程的 work,其中核心为 wb_do_writeback->wb_writeback->__writeback_inodes_wb->writeback_sb_inodes->__writeback_single_inode->do_writepages 本质是在实际文件系统的格式里找到要写 page 对应的 block 位置,构建出相应的 buffer head(bh)以及 bio,然后调用 submit_bio()来产生一个对 block device 的 write。
bio 还只是一个抽象的读写 block device 的请求,bio 要变成实际的 block device access 还要通过 block device driver 再排队,并受到 ioschduluer 的控制。
2.DirectIO
在一些类似于 MySQL 这样的应用层数据库软件中,应用层已经实现了数据的缓存功能,这时候在 IO 读写的时候,再经过页面缓存层反而是一种浪费,所以在 Linux 中提供了 DirectIO 的实现。
回到 __generic_file_write_iter 的实现,DirectIO 的核心部分由 generic_file_direct_write 函数完成:
ssize_t
generic_file_direct_write(struct kiocb *iocb, struct iov_iter *from, loff_t pos)
{
struct file *file = iocb->ki_filp;
struct address_space *mapping = file->f_mapping;
struct inode *inode = mapping->host;
ssize_t written;
size_t write_len;
pgoff_t end;
struct iov_iter data;
write_len = iov_iter_count(from);
end = (pos + write_len - 1) >> PAGE_CACHE_SHIFT;
// 刷该文件 mapping 下的脏页
written = filemap_write_and_wait_range(mapping, pos, pos + write_len - 1);
…
// 检查和该 direct_IO 相关的缓存页是否还存在,如果有就让它失效
if (mapping->nrpages) {
written = invalidate_inode_pages2_range(mapping,
pos >> PAGE_CACHE_SHIFT, end);
…
}
data = *from;
// 调用 direct_IO 方法
written = mapping->a_ops->direct_IO(iocb, &data, pos);
// 再次检查 direct_IO 对应的缓存页是否还存在,如果有就让它失效。
if (mapping->nrpages) {
invalidate_inode_pages2_range(mapping,
pos >> PAGE_CACHE_SHIFT, end);
}
if (written > 0) {
pos += written;
iov_iter_advance(from, written);
if (pos > i_size_read(inode) && !S_ISBLK(inode->i_mode)) {
i_size_write(inode, pos);
mark_inode_dirty(inode);
}
iocb->ki_pos = pos;
}
out:
return written;
}
DirectIO 执行的过程如下:
1)首先让文件对应的脏页刷新到块设备层,并且同步等待获取结果。
2)检查和这次 DirectIO 相关的缓存页,如果有就让它失效。
3)调用 mapping->a_ops->direct_IO(iocb,&data,pos)。
4)再次检查和这次 DirectIO 相关的缓存页,如果有也让它失效。
下面,我们再重点关注 mapping->a_ops->direct_IO 的实现,在 ext4 文件系统中,a_ops 定义如下:
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.readpages = ext4_readpages,
.writepage = ext4_writepage,
.writepages = ext4_writepages,
.write_begin = ext4_write_begin,
.write_end = ext4_write_end,
.bmap = ext4_bmap,
.invalidatepage = ext4_invalidatepage,
.releasepage = ext4_releasepage,
.direct_IO = ext4_direct_IO,
.migratepage = buffer_migrate_page,
.is_partially_uptodate = block_is_partially_uptodate,
.error_remove_page = generic_error_remove_page,
};
其中,direct_IO 方法最终会执行 ext4_direct_IO 方法。在 ext4_direct_IO 方法中,我们仅仅关注最后调用的方法:__blockdev_direct_IO->do_blockdev_direct_IO。在 direct_IO 实现中,有两个结构体扮演了非常重要的角色:struct dio 和 struct dio_submit。一些关键成员变量的含义如下:
dio_submit.pages_in_io:本次 IO 共有多少个 page。
dio_submit.first_block_in_page:IO 操作的第一个块在页面中的偏移量。
dio_submit.final_block_in_request:本次 IO 请求的最后一个块号。
dio_submit.total_pages:本次 IO 请求共有多少个 page。
do_blockdev_direct_IO 的一堆准备工作我们忽略不关注,在初始化 dio_submit 和 dio 后,进入了 do_direct_IO,这里有三个关键步骤:
1)dio_get_page 将用户态缓冲区转化为 page。
2)get_more_blocks 把对应磁盘的逻辑块号转换成物理块号。
3)submit_page_section->dio_bio_submit 把 dio 转换成 bio 提交到块设备层。
5.1.3 Block 层
通过 directIO 和 writeback 机制最终都会通过 submit_bio 方法提交 bio 到 block 层,下面我们开始分析在 block 层的流程。
submit_bio 核心还是调用了 generic_make_request 来构建 block 层的 IO 请求:
blk_qc_t generic_make_request(struct bio *bio)
{
struct bio_list bio_list_on_stack;
blk_qc_t ret = BLK_QC_T_NONE;
if (!generic_make_request_checks(bio))
goto out;
if (current->bio_list) {
bio_list_add(current->bio_list, bio);// 把 bio 添加到当前线程的 bio_list 中
goto out;
}
…
bio_list_init(&bio_list_on_stack);
current->bio_list = &bio_list_on_stack;
do {
struct request_queue *q = bdev_get_queue(bio->bi_bdev);
if (likely(blk_queue_enter(q, false) == 0)) {
// 将 bio 合并到某个 request 中,同时因为增加了一个 bio,原本不相邻的两个 request 可能变得相邻,从而可以合并成一个 request
ret = q->make_request_fn(q, bio);
blk_queue_exit(q);
bio = bio_list_pop(current->bio_list);
} else {
struct bio *bio_next = bio_list_pop(current->bio_list);
bio_io_error(bio);
bio = bio_next;
}
} while (bio);
current->bio_list = NULL; // 让当前进程 bio_list 失效
out:
return ret;
}
在 generic_make_request 实现中请求构建的关键为 q->make_request_fn,该函数调用链路为:
blk_init_queue()->blk_init_queue_node()->blk_init_allocated_queue->blk_queue_make_request(q,lk_queue_bio);最后被调用执行的回调函数 blk_queue_bio 的实现如下:
static blk_qc_t blk_queue_bio(struct request_queue *q, struct bio *bio)
{
const bool sync = !!(bio->bi_rw & REQ_SYNC);
struct blk_plug *plug;
int el_ret, rw_flags, where = ELEVATOR_INSERT_SORT;
struct request *req;
unsigned int request_count = 0;
…
blk_queue_split(q, &bio, q->bio_split);
…
if (!blk_queue_nomerges(q)) {
// 尝试将 bio 合并到当前 plugged 的请求队列中
if (blk_attempt_plug_merge(q, bio, &request_count, NULL))
return BLK_QC_T_NONE;
} else
request_count = blk_plug_queued_count(q);
spin_lock_irq(q->queue_lock);
// elv_merge 是核心函数,找到 bio 前向或者后向合并的请求
el_ret = elv_merge(q, &req, bio);
if (el_ret == ELEVATOR_BACK_MERGE) {
// 进行后向合并操作
if (bio_attempt_back_merge(q, req, bio)) {
elv_bio_merged(q, req, bio);
if (!attempt_back_merge(q, req))
elv_merged_request(q, req, el_ret);
goto out_unlock;
}
} else if (el_ret == ELEVATOR_FRONT_MERGE) {
// 进行前向合并操作
if (bio_attempt_front_merge(q, req, bio)) {
elv_bio_merged(q, req, bio);
if (!attempt_front_merge(q, req))
elv_merged_request(q, req, el_ret);
goto out_unlock;
}
}
// 无法找到对应的请求实现合并
get_rq:
rw_flags = bio_data_dir(bio);
if (sync)
rw_flags |= REQ_SYNC;
// 获取一个empty request请求
req = get_request(q, rw_flags, bio, GFP_NOIO);
if (IS_ERR(req)) {
bio->bi_error = PTR_ERR(req);
bio_endio(bio);
goto out_unlock;
}
// 采用 bio 对 request 请求进行初始化
init_request_from_bio(req, bio);
if (test_bit(QUEUE_FLAG_SAME_COMP, &q->queue_flags))
req->cpu = raw_smp_processor_id();
plug = current->plug;
if (plug) {
if (!request_count)
trace_block_plug(q);
else {
if (request_count >= BLK_MAX_REQUEST_COUNT) {
// 请求数量达到队列上限值,进行 unplug 操作
blk_flush_plug_list(plug, false);
trace_block_plug(q);
}
}
// 将请求加入到队列
list_add_tail(&req->queuelist, &plug->list);
blk_account_io_start(req, true);
} else {
spin_lock_irq(q->queue_lock);
// 将 request 加入到调度器中
add_acct_request(q, req, where);
// 调用 q->request_fn(q);
__blk_run_queue(q);
out_unlock:
spin_unlock_irq(q->queue_lock);
}
return BLK_QC_T_NONE;
}
总结一下,blk_queue_bio 函数的大致处理流程如下:
1)调用 blk_queue_bounce 进行一些特殊处理(如果底层驱动表示它想要将在某个限制之上的页地址回弹到低地址)。
2)调用 attempt_plug_merge 尝试将新的请求同已经 plugged 的请求进行合并,已经 plugged 的请求会被保存在 current->plug 链表中。
3)调用 elv_merge 判断新的 bio 是否可以同请求队列上已经存在的请求的 bio 进行合并,如果可以合并就进行合并。这里是否可以合并以及如何合并都取决于所采用的 IO 调度算法。
4)如果无法进行合并,开始创建一个新的请求,调用 get_request_wait 来获取一个新的请求结构。
5)调用 init_request_from_bio 来使用 bio 中的数据初始化这个新的请求。
6)如果 current->plug 不空,则表示当前队列是 plug 的,如果该链表上已经有足够数目的请求,则调用 blk_flush_plug_list 进行处理(该函数会调用 __elv_add_request 将请求添加到请求队列,还可能调用 queue_unplugged 进行实际的请求处理),最后会将新的请求添加到 current->plug 上并更新统计信息。
7)如果 current->plug 为空,则调用 __blk_run_queue 直接处理请求,这会调用请求队列上的 request_fn,也就是要求驱动必须提供的那个函数来进行请求处理。
从其处理逻辑可以看出,这里又对请求进行了一次缓冲,如果 current->plug 不空,则新的请求都会添加到该链表上,只有请求的数目超过一定的值后才会处理(加入到请求队列中或者更进一步地处理掉)。显然只有这里的处理逻辑是不完善的,假如系统不是很忙,只有很少量的请求需要处理,则这里的处理条件可能很长时间都不能被满足,这时就需要另外一个机制来触发 blk_flush_plug_list 的动作,这个机制就是 schedule,该机制的路径如下:schedule->sched_submit_work->blk_schedule_flush_plug->blk_flush_plug_list。
到了这一步,IO 的读写已经被提交给了硬件,由驱动所提供的 request_fn 进行处理。
5.1.4 scsi 层
在 block 层的实现中 blk_queue_bio 最后一步或者用 schedule 的时候,会执行 request_fn,该方法由不同的块设备驱动实现,我们以常见的 scsi 为例来分析一下。首先搞清楚 request_fn 是哪里来的,应是在 scsi 设备分配的时候设置的:
struct request_queue *scsi_alloc_queue(struct scsi_device *sdev)
{
struct request_queue *q;
q = __scsi_alloc_queue(sdev->host, scsi_request_fn);
if (!q)
return NULL;
blk_queue_prep_rq(q, scsi_prep_fn);
blk_queue_unprep_rq(q, scsi_unprep_fn);
blk_queue_softirq_done(q, scsi_softirq_done);
blk_queue_rq_timed_out(q, scsi_times_out);
blk_queue_lld_busy(q, scsi_lld_busy);
return q;
}
对应 scsi 层的 request_fn 就是 scsi_request_fn:
static void scsi_request_fn(struct request_queue *q)
__releases(q->queue_lock)
__acquires(q->queue_lock)
{
struct scsi_device *sdev = q->queuedata;
struct Scsi_Host *shost;
struct scsi_cmnd *cmd;
struct request *req;
shost = sdev->host;
for (;;) {
int rtn;
req = blk_peek_request(q); // 调用调度层的 elevator\_dispatch_fn 从队列中
取出最合适的 request
…
spin_unlock_irq(q->queue_lock);
cmd = req->special; // 获取 cmd
…
cmd->scsi_done = scsi_done;
rtn = scsi_dispatch_cmd(cmd); // 把命令发送到 host 层
if (rtn) {
scsi_queue_insert(cmd, rtn);
spin_lock_irq(q->queue_lock);
goto out_delay;
}
spin_lock_irq(q->queue_lock);
}
…
}
scsi_request_fn 从调用调度层的 elevator_dispatch_fn 队列中取出最合适的 request,然后获取 cmd,分发到 host 层,也就是真正的 scsi 硬件层。
在 scsi_dispatch_cmd 中,执行了:
rtn = host->hostt->queuecommand(host, cmd);// 把命令写入到 scsi 硬件层
我们以 QLogic 的 qla4xxx 的 host 实现来说明:
qla4xxx_queuecommand-> qla4xxx_send_command_to_isp-> ha->isp_ops->queue_
ocb(ha);
void qla4xxx_queue_iocb(struct scsi_qla_host *ha)
{
writel(ha->request_in, &ha->reg->req_q_in);
readl(&ha->reg->req_q_in);
}
最后通过 write 命令把数据写入到 scsi 硬件缓冲区,然后用 read 读取结果。
在 scsi 层的流程如图5-3所示。
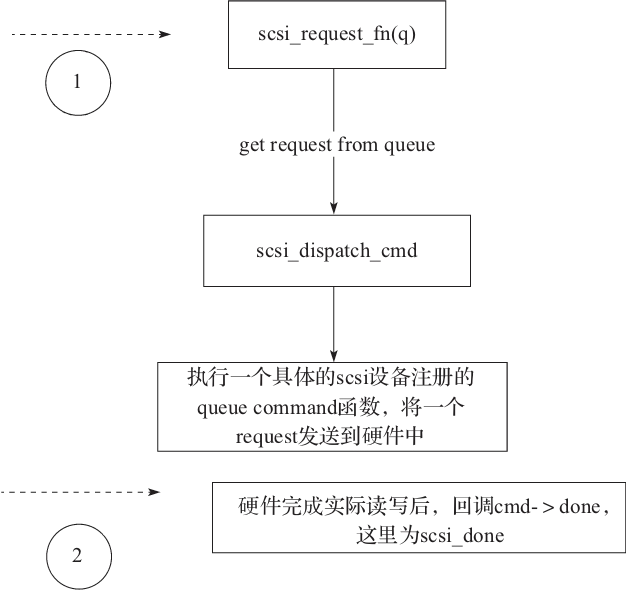
图5-3 scsi 层 I/O 流程示意图
5.1.5 I/O 流程总结
首先来总结一下从页面缓存到最终提交到设备的过程(见图5-4):
1)在地址空间构建 page 并且提交到 pageCache 中。
2)在 block 层调用 __block_commit_write 函数提交 work 到 bdi_writeback_queue 中。
3)每个 work 对应一个 wb_workfn 回调函数,会构建 bio 请求,通过 submit_io 函数提交到 request_queue 队列。
4)在 scsi 层通过 I/O 调度器来调度具体需要执行的 request。
5)scsi 层通过发送具体的 CMD 到指定的 scsi-host 层设备。
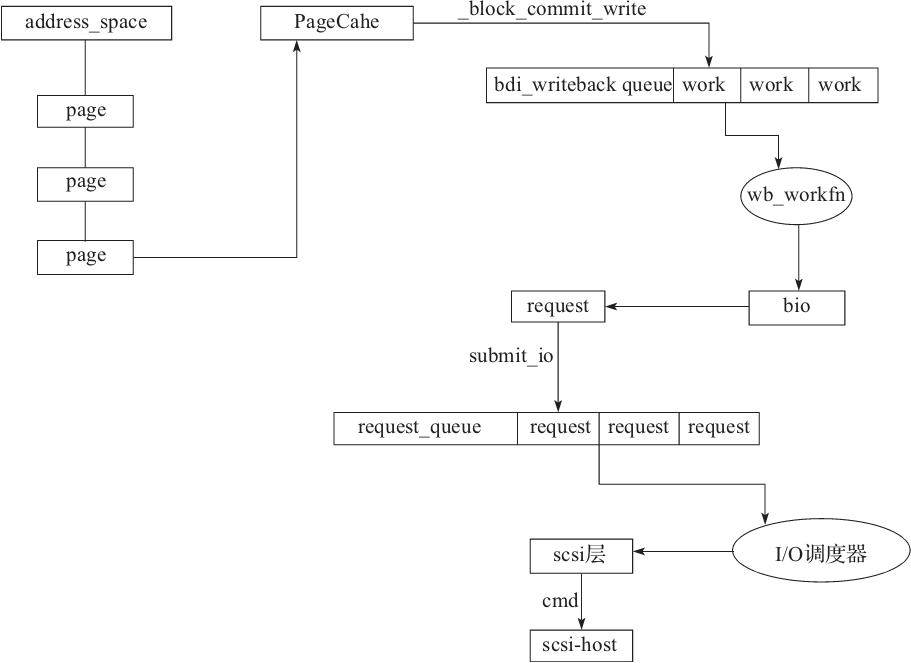
图5-4 I/O 写入流程图
图5-5描述了 Linux 中 I/O 的整体架构:
Linux 很好地贯彻了分层的设计思想,所以 I/O 的处理暴露给用户的也是从上到下的分层模型:
1)在用户态暴露给程序员的是系统调用函数,例如 read/write,一般会有标准库,例如用 glibc 进行封装。
2)为了屏蔽底层文件系统的实现细节,操作系统暴露的是标准文件操作接口 vfs。
3)基于 vfs 的接口,在 Linux 中支持不同的文件系统实现,例如 ext4 文件系统。
4)在某些场景下,为了加快 I/O 的读写速度,还会利用页面缓存来进行加速。
5)在 Linux 中,对文件的 I/O 读写事件,最终会被转化为 block 层的一个数据块。
6)Linux 对 I/O 的处理需要有个调度的过程,这里会涉及很多调度算法,例如著名的电梯算法。
7)Linux 把 I/O 的底层处理交给 scsi 层来处理,这是一个通用的抽象层。
8)对于具体的 scsi 设备,交给 scsi-host 层来处理,比如机械硬盘驱动。
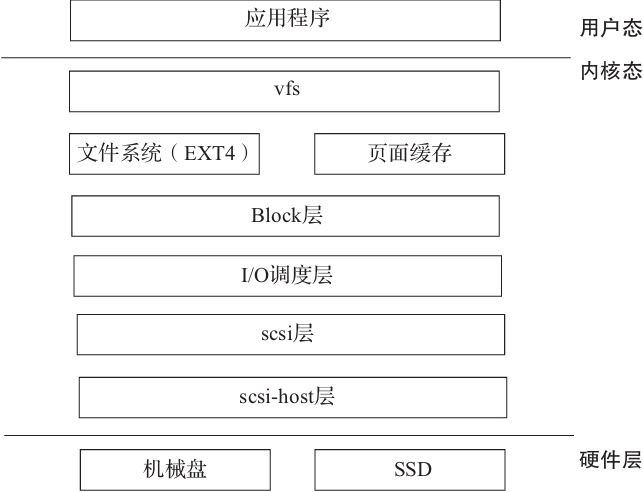
图5-5 Linux 的 I/O 整体架构
5.2 I/O 调度器
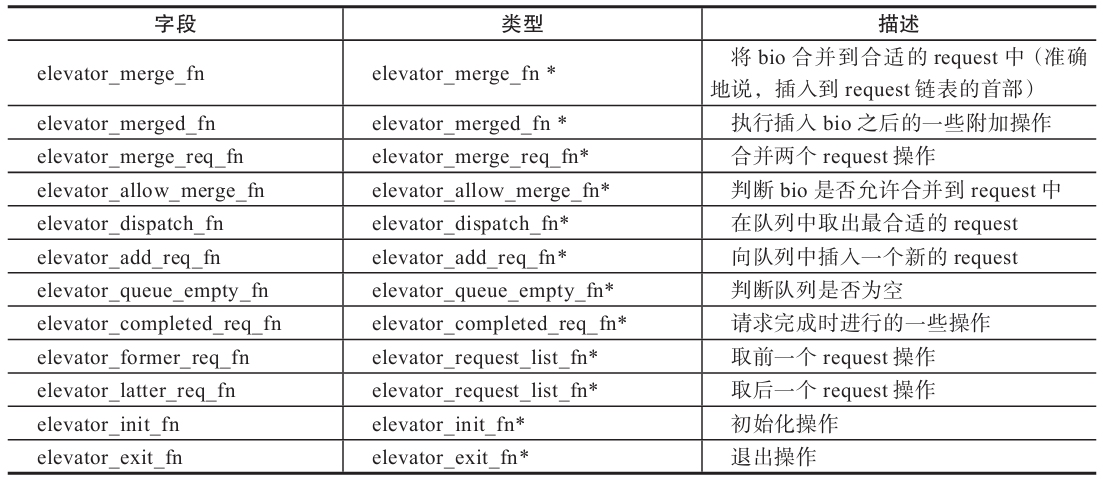
通过 block 层的分析,我们已经了解了调度是 block 层的概念,在 blk_queue_bio 中 elv_merge(q,&req,bio)->e->type->ops.elevator_merge_fn(q,req,bio)查找 scheduler(调度器)检查是否可以进行合并,如果可以,那么进行合并。
其中 ops 为 elevator_ops 类型,在 Linux 中为其定义了一些操作函数接口,这些接口函数由不同的 I/O 调度算法重载。不同的调度器对这些接口函数分别有不同的实现,表5-1是该数据结构中一些主要字段的意义。
表5-1 elevator_ops 中的主要字段
下面我们介绍常见的3种调度器:NOOP、CFQ、Deadline。
1.NOOP
NOOP 调度器十分简单,只拥有一个等待队列,每当来一个新的请求,仅仅是按先来先处理的思路将请求插入到等待队列的尾部。
2.CFQ
CFQ 实现了一种 QoS 的 I/O 调度算法。该算法为每一个进程分配一个时间窗口,在该时间窗口内,允许进程发出 I/O 请求。通过时间窗口在不同进程间的移动,保证了对于所有进程而言都有公平地发出 I/O 请求的机会。同时 CFQ 也实现了进程的优先级控制,保证高优先级进程可以获得更长的时间窗口。
CFQ 适用于系统中存在多任务 I/O 请求的情况,通过在多进程中轮换,保证了系统 I/O 请求整体的低延迟。但是,对于只有少数进程存在大量密集的 I/O 请求的情况,会出现明显的 I/O 性能下降。
3.Deadline
Deadline 调度算法主要针对 I/O 请求的延时而设计,每个 I/O 请求都附加了一个最后执行期限。该算法维护两类队列,一是按照扇区排序的读写请求队列;二是按照过期时间排序的读写请求队列。如果当前没有 I/O 请求过期,则会按照扇区顺序执行 I/O 请求;如果发现过期的 I/O 请求,则会处理按照过期时间排序的队列,直到所有过期请求都发生为止。在处理请求时,该算法会优先考虑读请求。
当系统中存在的 I/O 请求进程数量比较少时,与 CFQ 算法相比,Deadline 算法可以提供较高的 I/O 吞吐率。
Linux 系统中可以通过 cat/sys/block/.../queue/scheduler 进行查看:
cat /sys/block/sda/queue/scheduler
noop deadline [cfq]
修改磁盘 I/O 调度算法时,可以使用如下命令格式:echo 调度算法>/sys/block/磁盘名/queue/scheduler 例如:
echo "noop" > /sys/block/sda/queue/scheduler
cat /sys/block/sda/queue/scheduler
[noop] deadline cfq
4.机械硬盘和 SSD 的调度器选择
由于机械盘是由机械指针转动来读写数据的,如图5-6所示,所以,数据写入时需要考虑随机指针转动性能的问题。
注意
如果不是特殊场景,建议把 I/O 调度器设置为 CFQ,这对于通用的服务器也是最好的选择。
图5-6 机械磁盘示意图
固态硬盘(SSD)是基于闪存的数据存储设备,每个数据位保存在由浮栅晶体管制成的闪存单元里。SSD 整个都是由电子组件制成的,没有像硬盘那样的移动或者机械的部分,SSD 架构如图5-7所示。
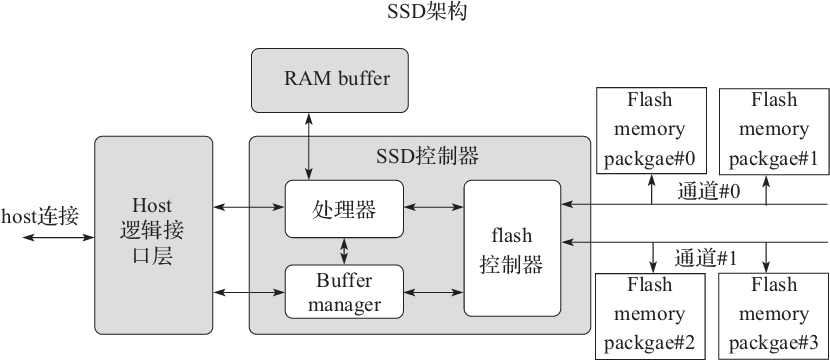
图5-7 SSD 架构图
默认的 I/O 调度一般针对磁盘寻址慢的特性做了专门优化,但对于 SSD 而言,由于访问磁盘不同逻辑扇区的时间几乎是一样的,这个优化就没有什么作用了,反而耗费了 CPU 时间。Linux 系统中,可以用 NOOP 调度器代替内核默认的 CFQ 调度器。
5.3 多队列机制
在 Linux3.19 中,block 层引入了多队列的机制,每个 CPU 维护一个队列来提升 I/O 的处理性能,如图5-8所示。
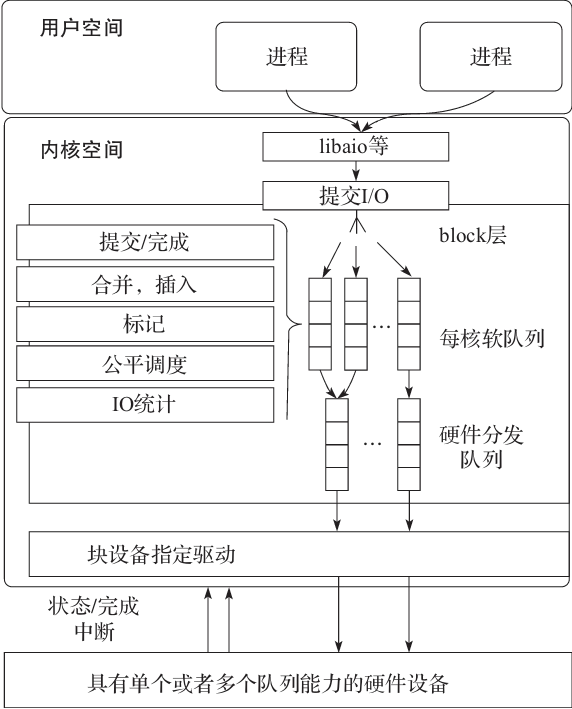
图5-8 Linux 多队列架构图
在 Linux 中,当使用多队列来提交请求的时候,执行函数为 blk_mq_insert_requests,该函数实现了多队列插入 request 的过程,实现代码如下:
static void blk_mq_insert_requests(struct request_queue *q,
struct blk_mq_ctx *ctx,
struct list_head *list,
int depth,
bool from_schedule)
{
struct blk_mq_hw_ctx *hctx;
struct blk_mq_ctx *current_ctx;
trace_block_unplug(q, depth, !from_schedule);
current_ctx = blk_mq_get_ctx(q); // 获取该 CPU 的 queue_ctx
if (!cpu_online(ctx->cpu)) // 假如当前 ctx 对应的 CPU 不在线,那么设置当前的
// ctx 为从这次请求对应的 ctx
ctx = current_ctx;
hctx = q->mq_ops->map_queue(q, ctx->cpu); // 获取该请求对应的硬件上下文
spin_lock(&ctx->lock);
while (!list_empty(list)) {
struct request *rq;
rq = list_first_entry(list, struct request, queuelist); // 获取第一个请求队列
list_del_init(&rq->queuelist); // 删除掉该队列
rq->mq_ctx = ctx;
__blk_mq_insert_req_list(hctx, ctx, rq, false); // 把当前请求队列插入到当前请求
// 上下文的请求队列的队尾
}
blk_mq_hctx_mark_pending(hctx, ctx); // 设置该硬件上下文为 pending
spin_unlock(&ctx->lock);
blk_mq_run_hw_queue(hctx, from_schedule);
blk_mq_put_ctx(current_ctx); // 打开该 CPU 抢占功能
}
在多核环境下,多队列机制能显著提升 I/O 读写的性能。
5.4 I/O 多路复用实现
Linux 在2.6内核之后,引入了 epoll 系统调用实现多路复用,显著提升了高并发场景下的吞吐量,其最大的功能就是获取事件的时候,无须遍历整个被侦听的描述符集,只要遍历那些被内核 I/O 事件异步唤醒而加入就绪队列的描述符集合就行了。
应用程序一般都会通过 libc 这样的库函数来使用封装过后的 epoll 调用,在 libc 中,封装了三个和 epoll 相关的系统调用函数:
int epoll_create(int size); // 创建 epoll 池子
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); // 向 epoll 中注册事件
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int
timeout); // 等待就绪事件的到来
其实 libc 的这三个函数,分别调用了 Linux 提供的三个同名系统调用,下面分别来分析其实现。
首先来看 epoll_create:
SYSCALL_DEFINE1(epoll_create, int, size)
{
…
return sys_epoll_create1(0);
}
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
int error, fd;
struct eventpoll *ep = NULL;
struct file *file;
…
error = ep_alloc(&ep);// 创建 eventpoll 数据结构
…
/*
* 从 fd 表中分配一个 fd
*/
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
if (fd < 0) {
error = fd;
goto out_free_ep;
}
// 创建一个新的文件
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,
O_RDWR | (flags & O_CLOEXEC));
if (IS_ERR(file)) {
error = PTR_ERR(file);
goto out_free_fd;
}
// 把文件和 fd 以及 eventpoll 挂钩
ep->file = file;
fd_install(fd, file);
return fd;
…
}
epoll_create 创建和初始化了 eventpoll 结构:
struct eventpoll {
…
wait_queue_head_t wq; // sys_epoll_wait() 使用的等待队列
wait_queue_head_t poll_wait;// file->poll()使用的等待队列
struct list_head rdllist; // 事件满足条件的链表
struct rb_root rbr; // 用于管理所有 fd 的红黑树(树根)
struct epitem *ovflist; // 将事件到达的 fd 链接起来发送至用户空间
…
struct file *file;
…
};
epitem 的结构为:
struct epitem {
union {
struct rb_node rbn; // 用于主结构管理的红黑树
struct rcu_head rcu;
};
struct list_head rdllink; // 事件就绪队列
struct epitem *next; // 用于主结构体中的链表
struct epoll_filefd ffd; // 这个结构体对应的被监听的文件描述符信息
int nwait; // poll 操作中事件的个数
struct list_head pwqlist; // 双向链表,保存着被监视文件的等待队列,功能类似于select/
// poll 中的 poll_table
struct eventpoll *ep; // 该项属于哪个主结构体(多个 epitm 从属于一个 eventpoll)
struct list_head fllink; // 双向链表,用来链接被监视的文件描述符对应的 structfile。
// 因为 file 里有 f_ep_link,用来保存所有监视这个文件的 epoll // 节点
...
struct epoll_event event; // 注册的感兴趣的事件,也就是用户空间的 epoll_event
};
其中 eventpoll 把 epitem 组织成了一颗红黑树。
在创建完 epoll 之后,就可以通过 epoll_ctl 来注册事件:
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
int error;
int full_check = 0;
struct fd f, tf;
struct eventpoll *ep;
struct epitem *epi;
struct epoll_event epds;
struct eventpoll *tep = NULL;
error = -EFAULT;
// 判断参数的合法性,将 __user *event 复制给 epds
if (ep_op_has_event(op) &&
copy_from_user(&epds, event, sizeof(struct epoll_event)))
goto error_return;
error = -EBADF;
f = fdget(epfd); // epoll fd 对应的文件对象
if (!f.file)
goto error_return;
tf = fdget(fd); // fd 对应的文件对象
…
// 在 create 时存入的(anon_inode_getfd),现在取用
ep = f.file->private_data;
…
// 防止重复添加(在 ep 的红黑树中查找是否已经存在这个 fd)
epi = ep_find(ep, tf.file, fd);
error = -EINVAL;
switch (op) {
case EPOLL_CTL_ADD: // 增加监听一个 fd
if (!epi) {
epds.events |= POLLERR | POLLHUP; //默认包含 POLLERR 和 POLLHUP 事件
error = ep_insert(ep, &epds, tf.file, fd, full_check); //在红黑树中插入这个 fd 对应的 epitm
} else // 红黑树中已经存在这个 fd
error = -EEXIST;
…
}
其中关键的一步为 ep_insert:
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd, int full_check)
{
int error, revents, pwake = 0;
unsigned long flags;
long user_watches;
struct epitem *epi;
struct ep_pqueue epq;
…
// 分配一个 epitem 来保存新加入的 fd
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
return -ENOMEM;
// 初始化epitem
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
epi->nwait = 0;
epi->next = EP_UNACTIVE_PTR;
…
epq.epi = epi;
// 初始化 ep_pqueue的poll table,并且设置 poll table 的回调函数为 ep_ptable_queue proc
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
// 执行 epi->ffd.file->f_op->poll
revents = ep_item_poll(epi, &epq.pt);
…
// 将该 epi 插入到 ep 的红黑树中
ep_rbtree_insert(ep, epi);
…
// revents & event->events:刚才 fop->poll 的返回值中标识的事件有用户 event 关心的事件发生。
// !ep_is_linked(&epi->rdllink):epi 的 ready 队列中有数据。ep_is_linked 用于判断队列是否为空。
// 如果要监视的文件状态已经就绪并且还没有加入到就绪队列中,则将当前的 epitem 加入到就绪队列中;
// 如果有进程正在等待该文件的状态就绪,则唤醒一个等待的进程
if ((revents & event->events) && !ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
ep_pm_stay_awake(epi);
// 如果有进程正在等待文件的状态就绪,也就是调用 epoll_wait 睡眠的进程正在等待,则唤醒一个等待进程。
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
if (waitqueue_active(&ep->poll_wait))
pwake++;
}
…
}
在 ep_item_poll 中执行了 epi->ffd.file->f_op->poll,如果 fd 是套接字,f_op 为 socket_file_ops,poll 函数是 sock_poll()。如果是 TCP 套接字的话,进而会调用到 tcp_poll()函数。此处调用 poll 函数查看当前文件描述符的状态,存储在 revents 中。在 poll 的处理函数(tcp_poll())中,会调用 sock_poll_wait(),在 sock_poll_wait()中会调用到 epq.pt.qproc 指向的函数,也就是 ep_ptable_queue_proc()。
// 在文件操作中的 poll 函数中调用,将 epoll 的回调函数加入到目标文件的唤醒队列中
// 参数 whead 是设备的等待队列
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
struct epitem *epi = ep_item_from_epqueue(pt); // 获取 pt 中的 epi 字段
struct eppoll_entry *pwq;
// 分配一个新的 eppoll_entry,用于关联 epitem 和设备以及 ep_poll_callback
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
// 初始化 pwd->wait 队列并且添加 ep_poll_callback
pwq->whead = whead;// pwq->whead 指向设备的等待队列
pwq->base = epi;
if (epi->event.events & EPOLLEXCLUSIVE)
add_wait_queue_exclusive(whead, &pwq->wait);
// 把 pwd 的等待队列加入到设备的等待队列中
else
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
} else {
// 当错误发生的时候,我们必须发送信号
epi->nwait = -1;
}
}
由于 ep_ptable_queue_proc 函数设置了等待队列的 ep_poll_callback 回调函数。所以在设备硬件数据到来时,硬件中断处理函数唤醒该等待队列上等待的进程时,会调用唤醒函数 ep_poll_callback:
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi->ep;
int ewake = 0;
…
spin_lock_irqsave(&ep->lock, flags);
// 有非 EPOLLWAKEUP | EPOLLONESHOT | EPOLLET | EPOLLEXCLUSIVE 事件
if (!(epi->event.events & ~EP_PRIVATE_BITS))
goto out_unlock;
// 没有注册的感兴趣事件
if (key && !((unsigned long) key & epi->event.events))
goto out_unlock;
if (unlikely(ep->ovflist != EP_UNACTIVE_PTR)) {
if (epi->next == EP_UNACTIVE_PTR) {
epi->next = ep->ovflist;
ep->ovflist = epi;
if (epi->ws) {
__pm_stay_awake(ep->ws);// 唤醒调用 epoll_wait()函数时睡眠的进程。
}
}
goto out_unlock;
}
最后就是通过 epoll_wait 来等待就绪事件的到来:
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
…
error = ep_poll(ep, events, maxevents, timeout);
…
return error;
}
epoll_wait 其实调用了 ep_poll,下面我们来看 ep_poll:
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
int res = 0, eavail, timed_out = 0;
unsigned long flags;
long slack = 0;
wait_queue_t wait;
ktime_t expires, *to = NULL;
…
if (!ep_events_available(ep)) {
init_waitqueue_entry(&wait, current);
// 没有事件,所以需要睡眠。当有事件到来时,睡眠会被 ep_poll_callback 函数唤醒
__add_wait_queue_exclusive(&ep->wq, &wait); // 将 current 进程放在 wait 这个等待队列中
for (;;) {
// 执行ep_poll_callback()唤醒时应当将当前进程唤醒,所以当前进程状态应该为“可唤醒”TASK_INTERRUPTIBLE
set_current_state(TASK_INTERRUPTIBLE);
// 如果就绪队列不为空(已经有文件的状态就绪)或者超时,则退出循环。
if (ep_events_available(ep) || timed_out)
break;
// 如果当前进程接收到信号,则退出循环,返回 EINTR 错误
if (signal_pending(current)) {
res = -EINTR;
break;
}
spin_unlock_irqrestore(&ep->lock, flags);
// 放弃 CPU 休眠一段时间
if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS))
timed_out = 1;
spin_lock_irqsave(&ep->lock, flags);
}
__remove_wait_queue(&ep->wq, &wait);
__set_current_state(TASK_RUNNING);
}
check_events:
// 该事件是否值得处理
eavail = ep_events_available(ep);
spin_unlock_irqrestore(&ep->lock, flags);
// 如果没有被信号中断,并且有事件就绪,但是没有获取到事件(有可能被其他进程获取到了),并且没有超时,
// 则跳转到 fetch_events 标签处,重新等待文件状态就绪
if (!res && eavail &&
!(res = ep_send_events(ep, events, maxevents)) && !timed_out)
goto fetch_events;
return res;
}
epoll_wait 会循环等待直到关心的事件就绪,其中 ep_send_events 函数向用户空间发送就绪事件。ep_send_events()函数将用户传入的内存简单封装到 ep_send_events_data 结构中,然后调用 ep_scan_ready_list()将就绪队列中的事件传入用户空间的内存。用户空间访问这个结果,进行处理。
最后,我们用图5-9回顾一下 epoll 调用的整体执行流程。
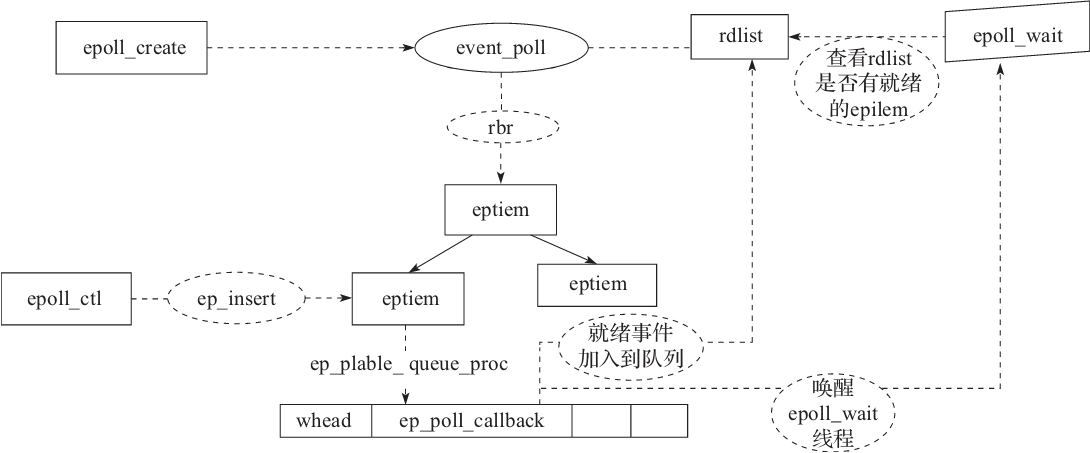
图5-9 epoll 的整体执行流程

















 1532
1532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









