






自己训练BERT
本文使用google提供的BERT脚本进行训练,并在TensorBoard中观察BERT的计算图。
bert地址:
https://github.com/google-research/bert
clone这个git repo
git clone https://github.com/google-research/bert
下载BERT预训练模型,里面有vocab.txt文件,后面要用到
wget https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip
解压BERT预训练模型到某个目录
:~/ugetdownload$ unzip uncased_L-12_H-768_A-12.zip
Archive: uncased_L-12_H-768_A-12.zip
creating: uncased_L-12_H-768_A-12/
inflating: uncased_L-12_H-768_A-12/bert_model.ckpt.meta
inflating: uncased_L-12_H-768_A-12/bert_model.ckpt.data-00000-of-00001
inflating: uncased_L-12_H-768_A-12/vocab.txt
inflating: uncased_L-12_H-768_A-12/bert_model.ckpt.index
inflating: uncased_L-12_H-768_A-12/bert_config.json
bert脚本需要使用tensorflow 1.x运行,使用2.x会报错
conda create -n py37tf1 python=3.7
conda activate py37tf1
pip install tensorflow < 2.0
设置BERT_BASE_DIR环境变量
export BERT_BASE_DIR=~/ugetdownload/uncased_L-12_H-768_A-12
运行数据脚本,产生用于预训练的数据
(py37tf1) ~/code/github_read/google-research/bert$ python create_pretraining_data.py \
--input_file=./sample_text.txt \
--output_file=./run0507/tf_examples.tfrecord \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--do_lower_case=True \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--masked_lm_prob=0.15 \
--random_seed=12345 \
--dupe_factor=5
WARNING:tensorflow:From create_pretraining_data.py:469: The name tf.app.run is deprecated. Please use tf.compat.v1.app.run instead.
WARNING:tensorflow:From create_pretraining_data.py:437: The name tf.logging.set_verbosity is deprecated. Please use tf.compat.v1.logging.set_verbosity instead.
W0502 17:39:58.054978 139793997326144 module_wrapper.py:139] From create_pretraining_data.py:437: The name tf.logging.set_verbosity is deprecated. Please use tf.compat.v1.logging.set_verbosity instead.
WARNING:tensorflow:From create_pretraining_data.py:437: The name tf.logging.INFO is deprecated. Please use tf.compat.v1.logging.INFO instead.
W0502 17:39:58.055087 139793997326144 module_wrapper.py:139] From create_pretraining_data.py:437: The name tf.logging.INFO is deprecated. Please use tf.compat.v1.logging.INFO instead.
在同一目录下运行训练脚本
python run_pretraining.py \
--input_file=./run0507/tf_examples.tfrecord \
--output_dir=./run0507/pretraining_output \
--do_train=True \
--do_eval=True \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--train_batch_size=32 \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--num_train_steps=20 \
--num_warmup_steps=10 \
--learning_rate=2e-5
I0502 17:48:02.704535 140404206638912 run_pretraining.py:173] name = cls/seq_relationship/output_bias:0, shape = (2,), *INIT_FROM_CKPT*
WARNING:tensorflow:From run_pretraining.py:198: The name tf.metrics.accuracy is deprecated. Please use tf.compat.v1.metrics.accuracy instead.
W0502 17:48:02.709678 140404206638912 module_wrapper.py:139] From run_pretraining.py:198: The name tf.metrics.accuracy is deprecated. Please use tf.compat.v1.metrics.accuracy instead.
WARNING:tensorflow:From run_pretraining.py:202: The name tf.metrics.mean is deprecated. Please use tf.compat.v1.metrics.mean instead.
W0502 17:48:02.722177 140404206638912 module_wrapper.py:139] From run_pretraining.py:202: The name tf.metrics.mean is deprecated. Please use tf.compat.v1.metrics.mean instead.
INFO:tensorflow:Done calling model_fn.
I0502 17:48:02.767565 140404206638912 estimator.py:1150] Done calling model_fn.
INFO:tensorflow:Starting evaluation at 2020-05-02T17:48:02Z
I0502 17:48:02.787446 140404206638912 evaluation.py:255] Starting evaluation at 2020-05-02T17:48:02Z
INFO:tensorflow:Graph was finalized.
I0502 17:48:03.247700 140404206638912 monitored_session.py:240] Graph was finalized.
INFO:tensorflow:Restoring parameters from /tmp/pretraining_output/model.ckpt-20
INFO:tensorflow:Evaluation [100/100]
I0502 17:50:20.824831 140404206638912 evaluation.py:167] Evaluation [100/100]
INFO:tensorflow:Finished evaluation at 2020-05-02-17:50:20
I0502 17:50:20.975484 140404206638912 evaluation.py:275] Finished evaluation at 2020-05-02-17:50:20
INFO:tensorflow:Saving dict for global step 20: global_step = 20, loss = 0.27436933, masked_lm_accuracy = 0.95210946, masked_lm_loss = 0.273851, next_sentence_accuracy = 1.0, next_sentence_loss = 0.0004196863
I0502 17:50:20.975750 140404206638912 estimator.py:2049] Saving dict for global step 20: global_step = 20, loss = 0.27436933, masked_lm_accuracy = 0.95210946, masked_lm_loss = 0.273851, next_sentence_accuracy = 1.0, next_sentence_loss = 0.0004196863
INFO:tensorflow:Saving 'checkpoint_path' summary for global step 20: /tmp/pretraining_output/model.ckpt-20
I0502 17:50:21.689311 140404206638912 estimator.py:2109] Saving 'checkpoint_path' summary for global step 20: /tmp/pretraining_output/model.ckpt-20
INFO:tensorflow:evaluation_loop marked as finished
I0502 17:50:21.689822 140404206638912 error_handling.py:101] evaluation_loop marked as finished
INFO:tensorflow:***** Eval results *****
I0502 17:50:21.689958 140404206638912 run_pretraining.py:483] ***** Eval results *****
INFO:tensorflow: global_step = 20
I0502 17:50:21.690061 140404206638912 run_pretraining.py:485] global_step = 20
INFO:tensorflow: loss = 0.27436933
I0502 17:50:21.690387 140404206638912 run_pretraining.py:485] loss = 0.27436933
INFO:tensorflow: masked_lm_accuracy = 0.95210946
I0502 17:50:21.690463 140404206638912 run_pretraining.py:485] masked_lm_accuracy = 0.95210946
INFO:tensorflow: masked_lm_loss = 0.273851
I0502 17:50:21.690540 140404206638912 run_pretraining.py:485] masked_lm_loss = 0.273851
INFO:tensorflow: next_sentence_accuracy = 1.0
I0502 17:50:21.690627 140404206638912 run_pretraining.py:485] next_sentence_accuracy = 1.0
INFO:tensorflow: next_sentence_loss = 0.0004196863
I0502 17:50:21.690728 140404206638912 run_pretraining.py:485] next_sentence_loss = 0.0004196863
使用TensorBoard可视化
现在基础的训练能够跑通,我们使用TensorBoard来可视化BERT的训练过程。
由于BERT使用了TensorBoard的estimator api,默认就会产生TensorBoard所需的events文件,文件位置在output_dir参数所指定的位置(/tmp/pretraining_output)。
(base) :/tmp/pretraining_output$ ll
总用量 2610064
drwxr-xr-x 3 wenkai wenkai 4096 5月 2 17:50 ./
drwxrwxrwt 65 root root 12288 5月 2 18:07 ../
-rw-rw-r-- 1 wenkai wenkai 126 5月 2 17:48 checkpoint
drwxr-xr-x 2 wenkai wenkai 4096 5月 2 17:50 eval/
-rw-rw-r-- 1 wenkai wenkai 156 5月 2 17:50 eval_results.txt
-rw-rw-r-- 1 wenkai wenkai 13311481 5月 2 17:48 events.out.tfevents.1588412530.G6
-rw-rw-r-- 1 wenkai wenkai 9153045 5月 2 17:42 graph.pbtxt
-rw-rw-r-- 1 wenkai wenkai 1321277144 5月 2 17:42 model.ckpt-0.data-00000-of-00001
-rw-rw-r-- 1 wenkai wenkai 23350 5月 2 17:42 model.ckpt-0.index
-rw-rw-r-- 1 wenkai wenkai 3796855 5月 2 17:42 model.ckpt-0.meta
-rw-rw-r-- 1 wenkai wenkai 1321277144 5月 2 17:48 model.ckpt-20.data-00000-of-00001
-rw-rw-r-- 1 wenkai wenkai 23350 5月 2 17:48 model.ckpt-20.index
-rw-rw-r-- 1 wenkai wenkai 3796855 5月 2 17:48 model.ckpt-20.meta
打开TensorBoard即可可视化训练过程:
(py37tf1) wenkai@wenkai-HP-EliteBook-840-G6:/tmp/pretraining_output$ tensorboard --logdir . --port 6007
W0502 18:08:16.384034 139671431165696 plugin_event_accumulator.py:294] Found more than one graph event per run, or there was a metagraph containing a graph_def, as well as one or more graph events. Overwriting the graph with the newest event.
W0502 18:08:16.389085 139671431165696 plugin_event_accumulator.py:302] Found more than one metagraph event per run. Overwriting the metagraph with the newest event.
TensorBoard 1.15.0 at http://0.0.00:6007/ (Press CTRL+C to quit)
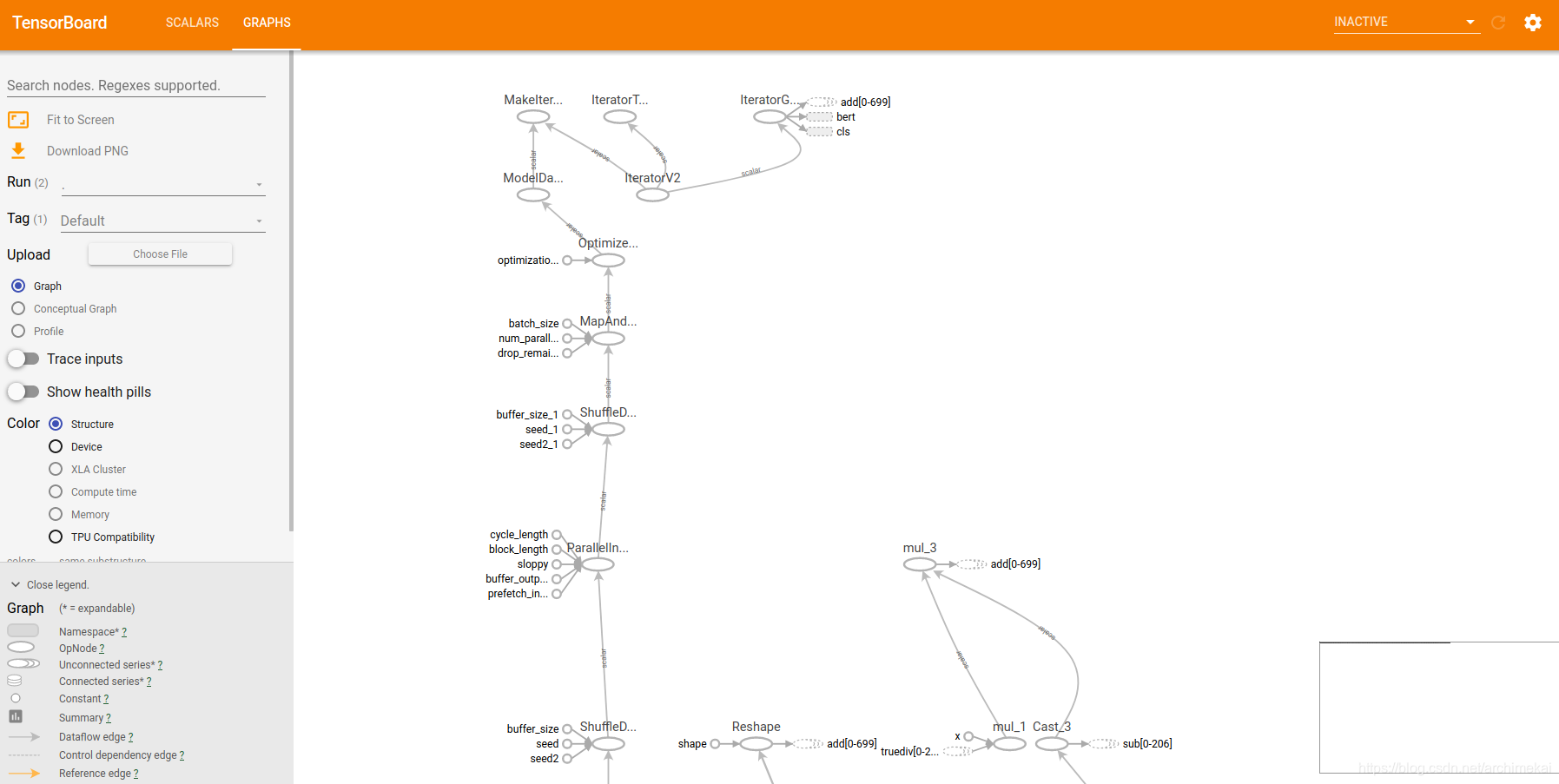
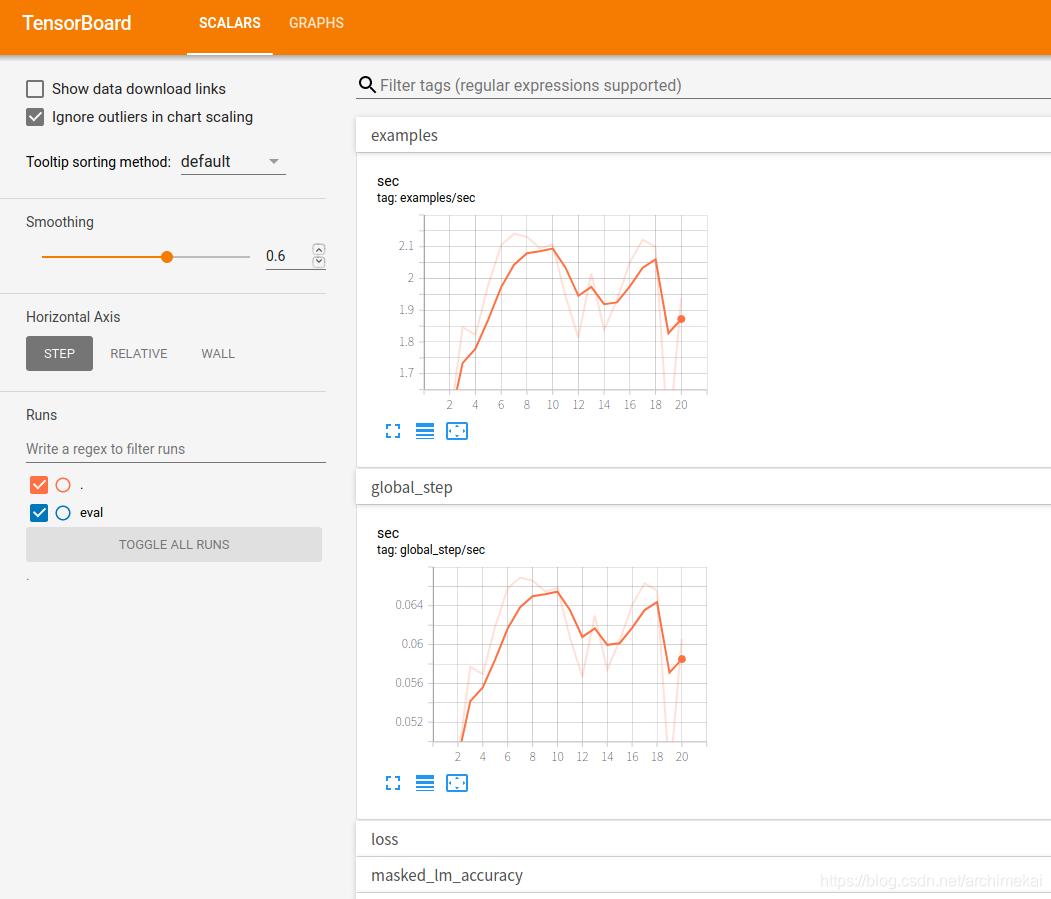
常见报错
使用TF2.x运行报错。
Traceback (most recent call last):
File "create_pretraining_data.py", line 26, in <module>
flags = tf.flags
AttributeError: module 'tensorflow' has no attribute 'flags'
解决办法:使用TensorFlow 1.x
没有设置BERT_BASE_DIR环境变量
Traceback (most recent call last):
File "create_pretraining_data.py", line 469, in <module>
tf.app.run()
File "/home/wenkai/anaconda3/envs/py37tf1/lib/python3.7/site-packages/tensorflow_core/python/platform/app.py", line 40, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File "/home/wenkai/anaconda3/envs/py37tf1/lib/python3.7/site-packages/absl/app.py", line 299, in run
_run_main(main, args)
File "/home/wenkai/anaconda3/envs/py37tf1/lib/python3.7/site-packages/absl/app.py", line 250, in _run_main
sys.exit(main(argv))
File "create_pretraining_data.py", line 440, in main
vocab_file=FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)
File "/home/wenkai/code/github_read/google-research/bert/tokenization.py", line 165, in __init__
self.vocab = load_vocab(vocab_file)
File "/home/wenkai/code/github_read/google-research/bert/tokenization.py", line 127, in load_vocab
token = convert_to_unicode(reader.readline())
File "/home/wenkai/anaconda3/envs/py37tf1/lib/python3.7/site-packages/tensorflow_core/python/lib/io/file_io.py", line 178, in readline
self._preread_check()
File "/home/wenkai/anaconda3/envs/py37tf1/lib/python3.7/site-packages/tensorflow_core/python/lib/io/file_io.py", line 84, in _preread_check
compat.as_bytes(self.__name), 1024 * 512)
tensorflow.python.framework.errors_impl.NotFoundError: /vocab.txt; No such file or directory
解决办法:正确设置BERT_BASE_DIR
关于TensorBoard的使用(请忽略)
由于使用的tensorflow是1.x版本,TensorBoard也要使用1.x版本,相关的文档在这里:
https://github.com/tensorflow/tensorboard/blob/master/docs/r1/summaries.md
https://github.com/tensorflow/tensorboard/blob/master/docs/r1/graphs.md
https://github.com/tensorflow/tensorboard/blob/master/docs/r1/overview.md
重点在这:
The FileWriter takes a logdir in its constructor - this logdir is quite important, it's the directory where all of the events will be written out. Also, the FileWriter can optionally take a Graph in its constructor. If it receives a Graph object, then TensorBoard will visualize your graph along with tensor shape information.
https://github.com/tensorflow/tensorboard/blob/master/docs/r1/summaries.md

















 2305
2305

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









