







 这篇博客介绍了Pandas库的一些常用操作,包括数据读写、类型转换、数据筛选、连接操作、GroupBy、删除和增加列、查找不重复值以及绘图等。重点讲解了如何使用astype()进行类型转换,read_csv()函数的dtype参数设定,以及如何通过pivot进行数据重塑。
这篇博客介绍了Pandas库的一些常用操作,包括数据读写、类型转换、数据筛选、连接操作、GroupBy、删除和增加列、查找不重复值以及绘图等。重点讲解了如何使用astype()进行类型转换,read_csv()函数的dtype参数设定,以及如何通过pivot进行数据重塑。
?
import numpy as np
import pandas as pd
features_list_temp = [x for x in df_tmp.columns if ('norm' in str(x))==True]
features_list = [x.replace('_norm','') for x in features_list_temp]
features = df_tmp[features_list]
补集
idx_test = np.random.randint(data_num, size=test_num)
session_ymd_test = session_ymd_uniq[idx_test]
idx_train = np.array(list(set(np.arange(data_num))-set(idx_test)))
select 行 where某一列的值在某个array中
feature[feature['session_ymd'].isin([3,4,9])]
转换类型・连接两列(字符)
#列a是int型,将它转变为str
dataframe["a"].map(str)
#将列a与列b(str型)合并
dataframe["a"].map(str)+' '+dataframe["b"]
numpy -> pandas
# data_test_cur是一个pd.dataframe变量
df_pred = pd.DataFrame(data={'pop_pred':pop_pred})
df_pred = pd.DataFrame(data={'pop_pred':pop_pred},index=data_test_cur.index)
pandas -> numpy
a = df_pred.values
a.tolist()
groupby
grouped = df_data.groupby("session_ymd")
# sessionごと、日付ごとで分ける
grouped = rawdata.groupby([rawdata["sessionid"],rawdata["ymd"]])
for session_ymd, df_group in grouped: #同じsessionid,同じymdの全ログ
# logtimeでsort
df_group.sort_values('logtime_sum', inplace=True)
print(session_ymd)
print(df_group)
pdb.set_trace()
将两个df.dataframs给连在一起
#df_1的列是'column1','column2'
#df_2的列是'abc','bcd'
#结果是'column1','column2','abc','bcd'
data_test = df_1.join(df_2)
index
#season_dummy: 'mesh','abc','seaon_1','seaon_2','seaon_3','pop'
#a将取season_dummy的所有行,以及'seaon_1','seaon_2','seaon_3','pop'这几列
a = season_dummy.ix[:, 'season_1':]
#取'mesh', 'pop'这两列
seaon_dummy.columns = ['mesh', 'pop']
b = seaon_dummy[cols_to_keep]
#
seaon_dummy.columns[2:]
where
#season_dummy: 'mesh','abc','seaon_1','seaon_2','seaon_3','pop'
#取mesh为100的所有行
season_dummy[season_dummy['mesh']==100]
data.loc[(data['month'] == mm) & (data['dayflag'] == dd)]
df[df['A'].isin([3, 6])]
Dataframe
读csv文件
test1.csv
mesh,pop
1,200
2,300
3,400
test2.csv
1,200
2,300
3,400
import pandas as pd
#会从第一行开始读数据
df = pd.read_csv('test2.csv', header=None,names=["mesh","pop"])
#会把csv的第一行认为是header,数据从第二行开始
df = pd.read_csv('test1.csv')
型(dtype)を指定して読み込み
https://note.nkmk.me/python-pandas-read-csv-tsv/
pandas.DataFrameは列ごとに型dtypeが設定されており、astype()メソッドで変換(キャスト)できる。文字列とobject型との関係など詳細は以下の記事を参照。
関連記事: pandasのデータ型dtype一覧とastypeによる変換(キャスト)
read_csv()では値から各列の型dtypeが自動的に選択されるが、場合によっては引数dtypeで明示的に指定する必要がある。
以下のファイルを例とする。
,a,b,c,d
ONE,1,"001",100,x
TWO,2,"020",,y
THREE,3,"300",300,z
source: sample_header_index_dtype.csv
0で始まる数値の列は引用符で囲まれていてもいなくてもデフォルトでは文字列ではなく数値としてみなされて、先頭の0は省略されてしまう。
df_default = pd.read_csv('data/src/sample_header_index_dtype.csv', index_col=0)
print(df_default)
# a b c d
# ONE 1 1 100.0 x
# TWO 2 20 NaN y
# THREE 3 300 300.0 z
print(df_default.dtypes)
# a int64
# b int64
# c float64
# d object
# dtype: object
print(df_default.applymap(type))
# a b c d
# ONE <class 'int'> <class 'int'> <class 'float'> <class 'str'>
# TWO <class 'int'> <class 'int'> <class 'float'> <class 'str'>
# THREE <class 'int'> <class 'int'> <class 'float'> <class 'str'>
source: pandas_csv_tsv.py
先頭の0を含んだ文字列として扱いたい場合は、read_csv()の引数dtypeを指定する。
引数dtypeに任意のデータ型を指定すると、index_colで指定した列も含むすべての列がその型に変換されて読み込まれる。例えばdtype=strとすると、すべての列が文字列にキャストされる。ただし、この場合も欠損値はfloat型。
df_str = pd.read_csv('data/src/sample_header_index_dtype.csv',
index_col=0, dtype=str)
print(df_str)
# a b c d
# ONE 1 001 100 x
# TWO 2 020 NaN y
# THREE 3 300 300 z
print(df_str.dtypes)
# a object
# b object
# c object
# d object
# dtype: object
print(df_str.applymap(type))
# a b c d
# ONE <class 'str'> <class 'str'> <class 'str'> <class 'str'>
# TWO <class 'str'> <class 'str'> <class 'float'> <class 'str'>
# THREE <class 'str'> <class 'str'> <class 'str'> <class 'str'>
source: pandas_csv_tsv.py
dtype=objectとしても同じ結果となる。
df_object = pd.read_csv('data/src/sample_header_index_dtype.csv',
index_col=0, dtype=object)
print(df_object)
# a b c d
# ONE 1 001 100 x
# TWO 2 020 NaN y
# THREE 3 300 300 z
print(df_object.dtypes)
# a object
# b object
# c object
# d object
# dtype: object
print(df_object.applymap(type))
# a b c d
# ONE <class 'str'> <class 'str'> <class 'str'> <class 'str'>
# TWO <class 'str'> <class 'str'> <class 'float'> <class 'str'>
# THREE <class 'str'> <class 'str'> <class 'str'> <class 'str'>
source: pandas_csv_tsv.py
型変換(キャスト)できない型を引数dtypeに指定するとエラーになるので注意。この例ではindex_colで指定した文字列のインデックス列を整数int型に変換するところでエラーになっている。
# df_int = pd.read_csv('data/src/sample_header_index_dtype.csv',
# index_col=0, dtype=int)
# ValueError: invalid literal for int() with base 10: 'ONE'
source: pandas_csv_tsv.py
読み込んだあとでpandas.DataFrameの列の型を変換するにはastype()メソッドに辞書形式で指定する。詳細は上述の関連記事を参照。
df_str_cast = df_str.astype({'a': int})
print(df_str_cast)
# a b c d
# ONE 1 001 100 x
# TWO 2 020 NaN y
# THREE 3 300 300 z
print(df_str_cast.dtypes)
# a int64
# b object
# c object
# d object
# dtype: object
source: pandas_csv_tsv.py
read_csv()での読み込み時に引数dtypeに辞書形式で列の型を指定することもできる。指定した列以外は自動で選ばれた型となる。
df_str_col = pd.read_csv('data/src/sample_header_index_dtype.csv',
index_col=0, dtype={'b': str, 'c': str})
print(df_str_col)
# a b c d
# ONE 1 001 100 x
# TWO 2 020 NaN y
# THREE 3 300 300 z
print(df_str_col.dtypes)
# a int64
# b object
# c object
# d object
# dtype: object
source: pandas_csv_tsv.py
列名だけでなく列番号でも指定できる。インデックス列を指定している場合、インデックス列も含めた列番号で指定する必要があるので注意。
df_str_col_num = pd.read_csv('data/src/sample_header_index_dtype.csv',
index_col=0, dtype={2: str, 3: str})
print(df_str_col_num)
# a b c d
# ONE 1 001 100 x
# TWO 2 020 NaN y
# THREE 3 300 300 z
print(df_str_col_num.dtypes)
# a int64
# b object
# c object
# d object
# dtype: object
source: pandas_csv_tsv.py
存csv
name=['one','two','three']
test=pd.DataFrame(columns=name,data=list)
print(test)
test.to_csv('out.csv',encoding='gbk')
test.to_csv('out.csv',encoding='gbk',index=False,header=True)
寻址
#?
data = data_train[data_train['mesh500mid']==mesh]
data[["a","b"]] #选a和b这两列
data["a":"d"] #选了从a列到d列的所有列
#转载
#https://blog.youkuaiyun.com/xiaodongxiexie/article/details/53108959
import numpy as np
import pandas as pd
from pandas import Sereis, DataFrame
ser = Series(np.arange(3.))
data = DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz'))
data['w'] #选择表格中的'w'列,使用类字典属性,返回的是Series类型
data.w #选择表格中的'w'列,使用点属性,返回的是Series类型
data[['w']] #选择表格中的'w'列,返回的是DataFrame类型
data[['w','z']] #选择表格中的'w'、'z'列
data[0:2] #返回第1行到第2行的所有行,前闭后开,包括前不包括后
data[1:2] #返回第2行,从0计,返回的是单行,通过有前后值的索引形式,
#如果采用data[1]则报错
data.ix[1:2] #返回第2行的第三种方法,返回的是DataFrame,跟data[1:2]同
data['a':'b'] #利用index值进行切片,返回的是**前闭后闭**的DataFrame,
#即末端是包含的
#——————新版本pandas已舍弃该方法,用iloc代替———————
data.irow(0) #取data的第一行
data.icol(0) #取data的第一列
ser.iget_value(0) #选取ser序列中的第一个
ser.iget_value(-1) #选取ser序列中的最后一个,这种轴索引包含索引器的series不能采用ser[-1]去获取最后一个,这会引起歧义。
#————————————————————————————-----------------
data.head() #返回data的前几行数据,默认为前五行,需要前十行则data.head(10)
data.tail() #返回data的后几行数据,默认为后五行,需要后十行则data.tail(10)
data.iloc[-1] #选取DataFrame最后一行,返回的是Series
data.iloc[-1:] #选取DataFrame最后一行,返回的是DataFrame
data.loc['a',['w','x']] #返回‘a’行'w'、'x'列,这种用于选取行索引列索引已知
data.iat[1,1] #选取第二行第二列,用于已知行、列位置的选取。
删除列
data.drop(['catid','category','weektype','mesh100mid'], axis=1, inplace=True)
增加列
df_tmp = pd.DataFrame(data={'hour2':np.square(data_train["hour"])},index=data_train.index)
data_train = data_train.join(df_tmp)
找出pd不重复的值
mesh500mids=data_train['mesh500mid'].unique()
for i, mesh in enumerate(mesh500mids):
data = data_train[data_train['mesh500mid']==mesh]
import numpy as np
import pandasa as pd
cat_week = np.unique(df[['catid','weektype']].values,axis=0)
for i in range(len(cat_week)):
cat = cat_week[i][0]
week = cat_week[i][1]
data = df.loc[(df['catid'] == cat) & (df['weektype'] == week)]
pd.unique(rawdata[["sessionid","ymd"]].values.ravel())
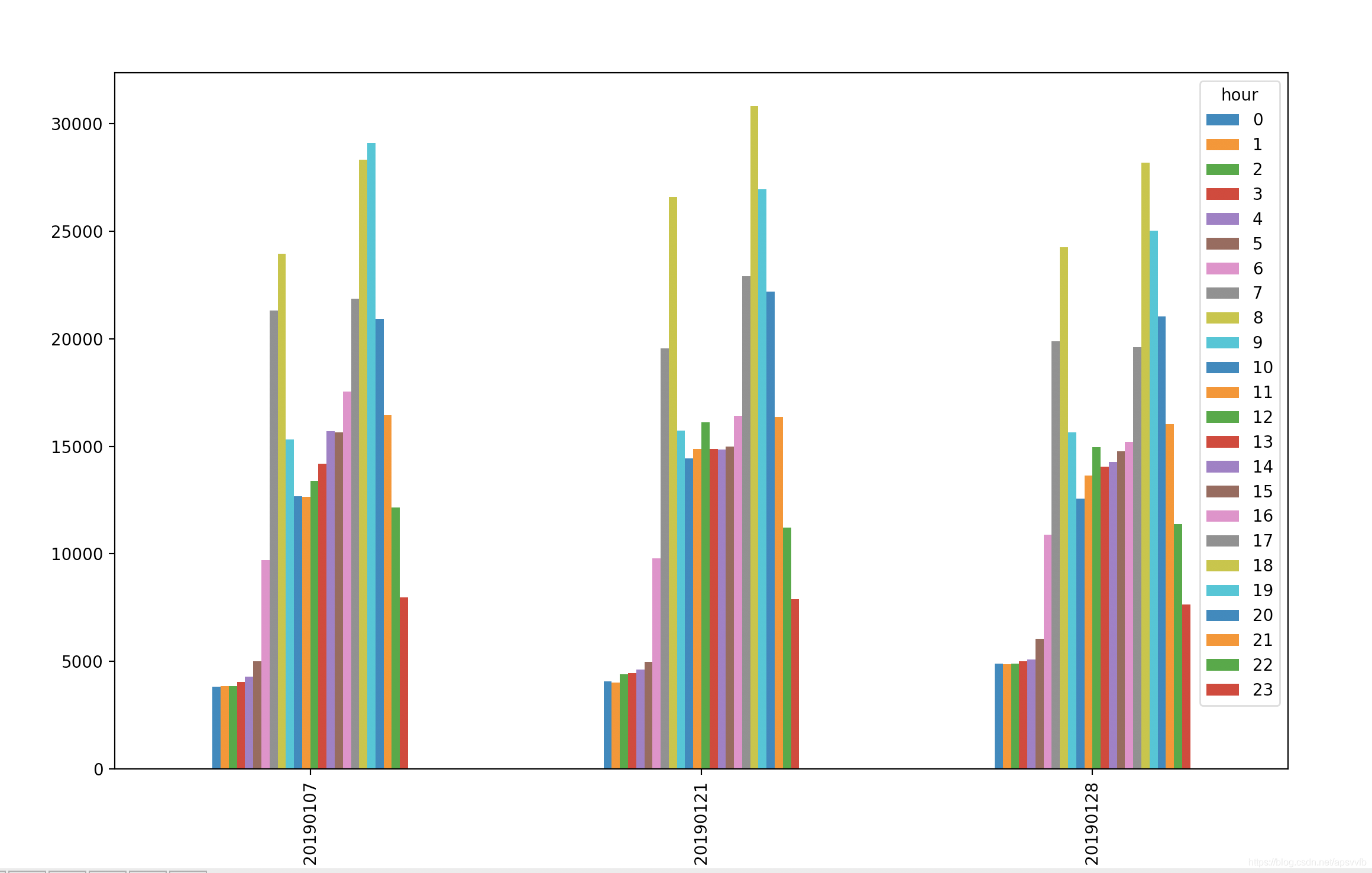
画图
import pandas as pd
import matplotlib.pyplot as plt
datatmp["time"]=datatmp["ymd"].map(str)+datatmp["hour"].map(str)
datatmp.plot(x='time',y='pop',title='dayflag:{}'.format(d))
plt.show()
有不同颜色的条形图
https://ask.hellobi.com/blog/wangdawei/9037
df2 = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df2.plot.bar()
index
有时候index是乱七八糟一堆数字,想把它们变成连续的数字时
data.reset_index()
pivot
pivoted = ldata.pivot('date', 'item', 'value')
前两个传递的值分别用作行和列索引,最后一个可选值则是用于填充DataFrame的数据列。假设有两个需要同时重塑的数据列:
# datatmp中有很多列,其中我们想要用的是:日期ymd,时间带hour, 人口值pop
datatmp[["ymd","hour","pop"]].pivot("ymd","hour","pop")
table = datatmp[["ymd","hour","pop"]].pivot("ymd","hour","pop")
print(table)
table.plot.bar()
plt.show()


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









