




 博客围绕K-近邻算法在分类和回归方面的应用展开,虽未给出具体代码内容,但强调了该算法在这两个领域的运用。K-近邻算法是信息技术领域重要算法,可用于数据处理和分析。
博客围绕K-近邻算法在分类和回归方面的应用展开,虽未给出具体代码内容,但强调了该算法在这两个领域的运用。K-近邻算法是信息技术领域重要算法,可用于数据处理和分析。
import numpy as np
from matplotlib import pyplot as plt
X_train = np.array([
[158, 64],
[170, 66],
[183, 84],
[191, 80],
[155, 49],
[163, 59],
[180, 67],
[158, 54],
[178, 77]
])
y_train = ["male", "male", "male", "male", "female", "female", "female", "female", "female"]
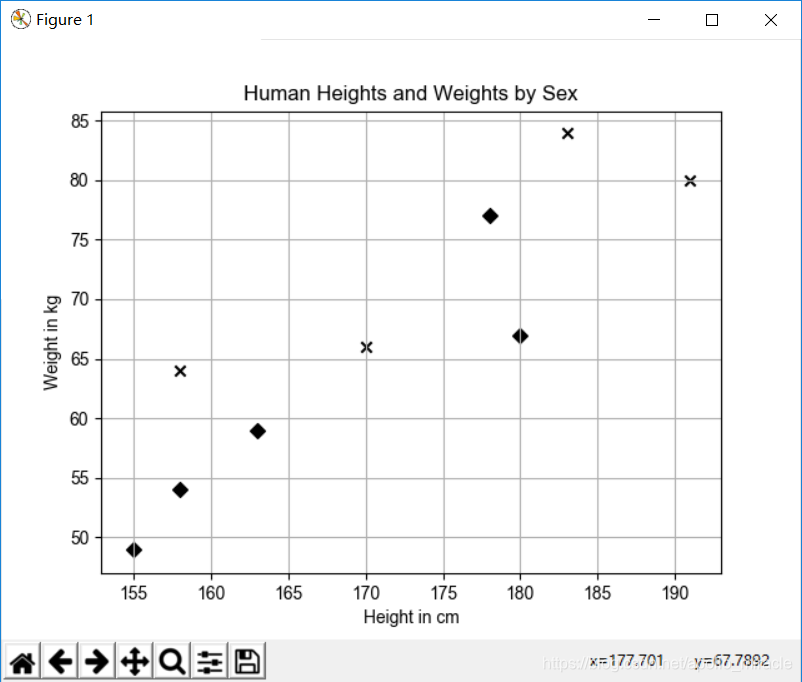
plt.figure()
plt.title("Human Heights and Weights by Sex")
plt.xlabel("Height in cm")
plt.ylabel("Weight in kg")
for i, x in enumerate(X_train):
plt.scatter(x[0], x[1], c="k", marker="x" if y_train[i] == "male" else "D")
plt.grid(True)
plt.show()
代码结果:
from collections import Counter
import numpy as np
X_train = np.array([
[158, 64],
[170, 66],
[183, 84],
[191, 80],
[155, 49],
[163, 59],
[180, 67],
[158, 54],
[178, 77]
])
y_train = ["male", "male", "male", "male", "female", "female", "female", "female", "female"]
# 预测数据
x = np.array([[155, 70]])
# 两点之间的距离
distances = np.sqrt(np.sum((X_train - x) ** 2, axis=1))
"""[ 6.70820393 15.5241747 31.30495168 37.36308338 21. 13.60147051 25.17935662 16.2788206 24.04163056]"""
# 距离由小到大的索引排序(取前三个)
nearest_neighbor_indices = distances.argsort()[:3]
"""[0 5 1]"""
# 通过索引,获取y_train中相应的内容
nearest_neighbor_genders = np.take(y_train, nearest_neighbor_indices)
"""['male' 'female' 'male']"""
# 统计nearest_neighbor_genders中每个数据出现的次数
b = Counter(nearest_neighbor_genders)
"""Counter({'male': 2, 'female': 1})"""
# 获取出现次数最多的一个数据(1代表获取一个数据)
gender = b.most_common(1)[0][0]
print(gender)
"""male"""
# 标签二进制化
from sklearn.preprocessing import LabelBinarizer
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
X_train = np.array([
[158, 64],
[170, 66],
[183, 84],
[191, 80],
[155, 49],
[163, 59],
[180, 67],
[158, 54],
[178, 77]
])
y_train = ["male", "male", "male", "male", "female", "female", "female", "female", "female"]
# 预测数据
x = np.array([[155, 70]])
# 实例化标签二进制化
lb = LabelBinarizer()
# 将y_train转化为二进制
y_train_binarized = lb.fit_transform(y_train)
"""[[1] [1] [1] [1] [0] [0] [0] [0] [0]]"""
K = 3
# 实例化KNeighborsClassifier类
clf = KNeighborsClassifier(n_neighbors=K)
# 调用fit方法
clf.fit(X_train, y_train_binarized.reshape(-1))
# 预测x的标签(二进制)
predicted_binarized = clf.predict(x)
"""[1]"""
# 将二进制转换为标签
predicted_label = lb.inverse_transform(predicted_binarized)
print(predicted_label)
"""['male']"""
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, matthews_corrcoef, \
classification_report
from sklearn.preprocessing import LabelBinarizer
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
X_train = np.array([
[158, 64],
[170, 66],
[183, 84],
[191, 80],
[155, 49],
[163, 59],
[180, 67],
[158, 54],
[178, 77]
])
y_train = ["male", "male", "male", "male", "female", "female", "female", "female", "female"]
# 预测数据
x_text = np.array([
[168, 65],
[180, 96],
[160, 52],
[169, 67]
])
y_test = ['female', 'male', 'female', 'female']
# 实例化标签二进制化
lb = LabelBinarizer()
# 将y_train转化为二进制
y_train_binarized = lb.fit_transform(y_train)
"""[[1] [1] [1] [1] [0] [0] [0] [0] [0]]"""
y_test_binarized = lb.transform(y_test)
"""[[0] [1] [0] [0]]"""
K = 3
# 实例化KNeighborsClassifier类
clf = KNeighborsClassifier(n_neighbors=K)
# 调用fit方法
clf.fit(X_train, y_train_binarized.reshape(-1))
# 预测x的标签(二进制)
predicted_binarized = clf.predict(x_text)
"""[1 1 0 0]"""
# 将二进制转换为标签
predicted_label = lb.inverse_transform(predicted_binarized)
print(predicted_label)
"""['male' 'male' 'female' 'female']"""
# 3.5计算准确率
# gender_accuracy_score = accuracy_score(y_test, predicted_label)
gender_accuracy_score = accuracy_score(y_test_binarized, predicted_binarized)
print(gender_accuracy_score)
# 3.6计算精准率(只能使用二进制)
gender_precision_score = precision_score(y_test_binarized, predicted_binarized)
print(gender_precision_score)
# 3.7计算召回率(只能使用二进制)
gender_recall_score = recall_score(y_test_binarized, predicted_binarized)
print(gender_recall_score)
# 3.8计算F1统计变量(精准率和召回率的调和平均值)
gender_f1_score = f1_score(y_test_binarized, predicted_binarized)
print(gender_f1_score)
# 3.9计算马修斯相关系数MCC
gender_mcc_score = matthews_corrcoef(y_test_binarized, predicted_binarized)
print(gender_mcc_score)
# 3.10生成精准率、召回率、F1得分
# gender_report = classification_report(y_test_binarized, predicted_binarized, target_names=["male"], labels=[1])
gender_report = classification_report(y_test_binarized, predicted_binarized)
print(gender_report)
代码结果:
['male' 'male' 'female' 'female']
0.75
0.5
1.0
0.6666666666666666
0.5773502691896258
precision recall f1-score support
0 1.00 0.67 0.80 3
1 0.50 1.00 0.67 1
micro avg 0.75 0.75 0.75 4
macro avg 0.75 0.83 0.73 4
weighted avg 0.88 0.75 0.77 4
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
from sklearn.neighbors import KNeighborsRegressor
import numpy as np
X_train = np.array([
[158, 1],
[170, 1],
[183, 1],
[191, 1],
[155, 0],
[163, 0],
[180, 0],
[158, 0],
[170, 0]
])
y_train = [64, 86, 84, 80, 49, 59, 67, 54, 67]
# 预测数据
x_text = np.array([
[168, 1],
[180, 1],
[160, 0],
[169, 0]
])
y_test = [65, 96, 52, 67]
K = 3
# 实例化KNeighborsRegressor类
clf = KNeighborsRegressor(n_neighbors=K)
# 调用fit方法
clf.fit(X_train, y_train)
# 预测x的体重
predictions = clf.predict(x_text)
print("Predicted wights: %s" % predictions)
# 计算确定系数
wieghts_r2_score = r2_score(y_test, predictions)
print("Coefficient of determination: %s" % wieghts_r2_score)
# 计算平均绝对误差
wieghts_mean_absolute_error = mean_absolute_error(y_test, predictions)
print("Mean absolute error: %s" % wieghts_mean_absolute_error)
# 计算均方误差
wieghts_mean_squared_error = mean_squared_error(y_test, predictions)
print("Mean squared error: %s" % wieghts_mean_squared_error)
代码结果:
Predicted wights: [70.66666667 79. 59. 70.66666667]
Coefficient of determination: 0.6290565226735438
Mean absolute error: 8.333333333333336
Mean squared error: 95.8888888888889
import numpy as np
from scipy.spatial.distance import euclidean
# heights in millimeters
X_train = np.array([
[1700, 1],
[1600, 0]
])
x_test = np.array([1640, 1]).reshape(1, -1)
# 计算欧氏距离(Euclidean Distance)
print(euclidean(X_train[0, :], x_test))
print(euclidean(X_train[1, :], x_test))
# heights in meters
X_train = np.array([
[1.7, 1],
[1.6, 0]
])
x_test = np.array([1.64, 1]).reshape(1, -1)
print(euclidean(X_train[0, :], x_test))
print(euclidean(X_train[1, :], x_test))
代码结果:
60.0
40.01249804748511
0.06000000000000005
1.0007996802557444
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
from sklearn.neighbors import KNeighborsRegressor
import numpy as np
from sklearn.preprocessing import StandardScaler
X_train = np.array([
[158, 1],
[170, 1],
[183, 1],
[191, 1],
[155, 0],
[163, 0],
[180, 0],
[158, 0],
[170, 0]
])
y_train = [64, 86, 84, 80, 49, 59, 67, 54, 67]
# 预测数据
x_test = np.array([
[168, 1],
[180, 1],
[160, 0],
[169, 0]
])
y_test = [65, 96, 52, 67]
# 实例化StandardScaler类
ss = StandardScaler()
# 调用fit_transform方法
X_train_scaled = ss.fit_transform(X_train)
print(X_train)
print(X_train_scaled)
x_test_scaled = ss.fit_transform(x_test)
print(x_test)
print(x_test_scaled)
K = 3
# 实例化KNeighborsRegressor类
clf = KNeighborsRegressor(n_neighbors=K)
# 调用fit方法
clf.fit(X_train_scaled, y_train)
# 预测x的体重
predictions = clf.predict(x_test_scaled)
print("Predicted wights: %s" % predictions)
# 计算确定系数
wieghts_r2_score = r2_score(y_test, predictions)
print("Coefficient of determination: %s" % wieghts_r2_score)
# 计算平均绝对误差
wieghts_mean_absolute_error = mean_absolute_error(y_test, predictions)
print("Mean absolute error: %s" % wieghts_mean_absolute_error)
# 计算均方误差
wieghts_mean_squared_error = mean_squared_error(y_test, predictions)
print("Mean squared error: %s" % wieghts_mean_squared_error)
代码结果:
[[158 1]
[170 1]
[183 1]
[191 1]
[155 0]
[163 0]
[180 0]
[158 0]
[170 0]]
[[-0.9908706 1.11803399]
[ 0.01869567 1.11803399]
[ 1.11239246 1.11803399]
[ 1.78543664 1.11803399]
[-1.24326216 -0.89442719]
[-0.57021798 -0.89442719]
[ 0.86000089 -0.89442719]
[-0.9908706 -0.89442719]
[ 0.01869567 -0.89442719]]
[[168 1]
[180 1]
[160 0]
[169 0]]
[[-0.17557375 1. ]
[ 1.50993422 1. ]
[-1.29924573 -1. ]
[-0.03511475 -1. ]]
Predicted wights: [78. 83.33333333 54. 64.33333333]
Coefficient of determination: 0.6706425961745109
Mean absolute error: 7.583333333333336
Mean squared error: 85.13888888888893

















 2742
2742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









