



@[TOC](lecture3-Dynamic Mode Decomposition(DMD))
纯新手!纯个人理解,主要拿来应用时间序列分析,没有数学基础,自用,勿喷。
lecture1介绍了SVD,lecture2介绍了POD,很重要,但是没做整理,略。
研究问题
在一个线性系统里,如何对未来数据进行预测?
公式
lecture里只介绍了 SVD-based DMD:
1. 数据准备
将时间序列数据矩阵 V1NV_1^NV1N 拆分为两个矩阵:
V1N−1=[v1,v2,…,vN−1]
V_1^{N-1} = [v_1, v_2, \dots, v_{N-1}]
V1N−1=[v1,v2,…,vN−1]
V2N=[v2,v3,…,vN]
V_2^{N} = [v_2, v_3, \dots, v_N]
V2N=[v2,v3,…,vN]
其中 vk∈Rnv_k \in \mathbb{R}^nvk∈Rn 表示第 kkk 个时间点的状态快照,V1N∈RM×NV_{1}^{N} \in \mathbb{R}^{M \times N}V1N∈RM×N是一个数据矩阵,,其列代表各个快照。这些快照被假设通过线性映射相互关联,该线性映射定义了一个线性动力系统:
vi+1=Avi v_{i+1} = A v_{i} vi+1=Avi
以矩阵形式表示:
V2N=AV1N−1+reN−1T, {\displaystyle V_{2}^{N}=AV_{1}^{N-1}+re_{N-1}^{T},} V2N=AV1N−1+reN−1T,
The SVD-based approach yields the matrix S~\tilde{S}S~ that is related to AAA via a similarity transform.
2. 奇异值分解 (SVD)
对 V1N−1V_1^{N-1}V1N−1 进行奇异值分解:
V1N−1=UΣWT
V_1^{N-1} = U \Sigma W^T
V1N−1=UΣWT
- U∈Rn×rU \in \mathbb{R}^{n \times r}U∈Rn×r:左奇异向量矩阵(POD,正交分解模式),满足 UTU=IrU^T U = I_rUTU=Ir
POD的核心:找到最优正交基 UUU - Σ∈Rr×r\Sigma \in \mathbb{R}^{r \times r}Σ∈Rr×r:奇异值对角矩阵
- W∈R(N−1)×rW \in \mathbb{R}^{(N-1) \times r}W∈R(N−1)×r:右奇异向量矩阵,满足 WTW=IrW^T W = I_rWTW=Ir
- rrr:保留的奇异值个数(可根据能量准则截断)
3. 构建降阶矩阵
计算降阶矩阵:
S~=UTV2NWΣ−1
\tilde{S} = U^T V_2^{N} W \Sigma^{-1}
S~=UTV2NWΣ−1
其中 S~∈Rr×r\tilde{S} \in \mathbb{R}^{r \times r}S~∈Rr×r 是原系统矩阵 AAA 在 POD 子空间上的投影。
构建推导:
V2N=AV1N−1+reN−1T V_2^{N} = A V_1^{N-1} + r e_{N-1}^T V2N=AV1N−1+reN−1T
- rerere:残差
假设条件
- rrr 与 UUU 正交,即 UTr=0U^T r = 0UTr=0
- V2NV_2^{N}V2N 的列在 UUU 的列张成的空间 Column Space中(POD 假设),即 V2N=UCV_2^{N} = U CV2N=UC 对某个 CCC 成立
Column space: 该矩阵的所有列向量通过线性组合所能得到的所有向量的集合。这句话意味着:下一个时刻的任何一个状态(即 V2NV_2^{N}V2N 的任意一列),都可以完全由过去时刻的主导模式 UUU 的线性组合来表示。
推导过程
由已知条件:
V2N=AUΣWT+reN−1T
V_2^{N} = A U \Sigma W^T + r e_{N-1}^T
V2N=AUΣWT+reN−1T
两边左乘 UTU^TUT:
UTV2N=UTAUΣWT+UTreN−1T
U^T V_2^{N} = U^T A U \Sigma W^T + U^T r e_{N-1}^T
UTV2N=UTAUΣWT+UTreN−1T
利用正交性假设 UTr=0U^T r = 0UTr=0:
UTV2N=UTAUΣWT
U^T V_2^{N} = U^T A U \Sigma W^T
UTV2N=UTAUΣWT
整理得到:
UTAU=(UTV2N)WΣ−1≡S~
U^T A U = (U^T V_2^{N}) W \Sigma^{-1} \equiv \tilde{S}
UTAU=(UTV2N)WΣ−1≡S~
于是得到降价矩阵(Reduced-Order Model, ROM):
S~=UTV2NWΣ−1
\tilde{S} = U^T V_2^{N} W \Sigma^{-1}
S~=UTV2NWΣ−1
4. 特征分解
对 S~\tilde{S}S~ 进行特征分解:
S~yi=λiyi
\tilde{S} y_i = \lambda_i y_i
S~yi=λiyi
- λi\lambda_iλi:第 iii 个 DMD 特征值
- yiy_iyi:S~\tilde{S}S~ 的第 iii 个特征向量
这里A和S~\tilde{S}S~做的是合同变换(维基百科说是相似变换相关),S~\tilde{S}S~的特征值近似A的特征值,如果y是S~\tilde{S}S~的特征向量,则UyUyUy近似A的特征向量。
- 当 UUU 是方阵且正交时(即保留所有POD模式,r=nr = nr=n),S~=UTAU\tilde{S} = U^T A US~=UTAU 是相似变换,特征值精确相同
- 当 UUU 是瘦正交矩阵时(r<nr < nr<n,降阶情况),S~\tilde{S}S~ 是 AAA 在子空间上的投影,特征值是 AAA 的 rrr 个主导特征值的近似
5. 重构 DMD 模式
将降阶特征向量映射回原始状态空间:
ϕi=Uyi
\phi_i = U y_i
ϕi=Uyi
其中
- ϕi∈Rn\phi_i \in \mathbb{R}^nϕi∈Rn 是第 iii 个 DMD 模式(A的近似特征向量)。
- U∈Rn×rU \in \mathbb{R}^{n \times r}U∈Rn×r,用来project back to high dimensional space (from coordinate to vector)
- yi∈Rry_i \in \mathbb{R}^{r}yi∈Rr, low dimension coordinate
6. 结果(deepseek说的)
- DMD 特征值:λi\lambda_iλi 描述模式的动态行为(增长/衰减率和频率)
- DMD 模式:ϕi\phi_iϕi 表示在状态空间中的相干空间结构
通过 DMD 分解,原系统动态可近似为:
v(t)≈∑i=1rϕiλit/Δtbi
v(t) \approx \sum_{i=1}^r \phi_i \lambda_i^{t/\Delta t} b_i
v(t)≈i=1∑rϕiλit/Δtbi
其中 bib_ibi 是初始幅值,可通过初始条件 v1v_1v1 在 DMD 模式上的投影求得。
仿真
数据描述
generate data from numerical integration of a partial differential equation
非线性薛定谔方程:
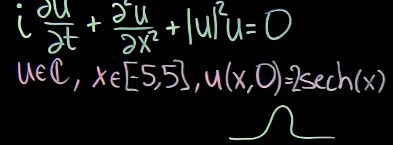
initial situation:
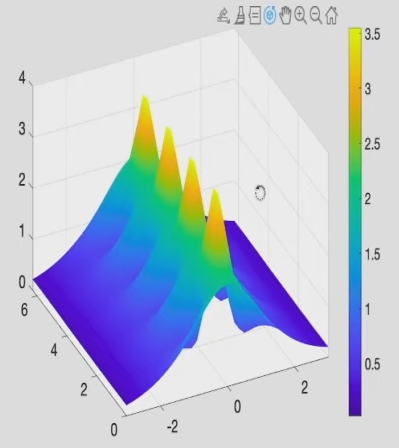
一开始是S曲线,随着时间推移,lt localizes and bunches up (局部化并聚集起来,黄色尖峰),然后breath out, and thenm sucks in.
过程:
- seed dyamic mode decomposition
- create data matrics (complex matrics):each column of X is advanced by one time step when you look at the same column of Y
- 计算DMD

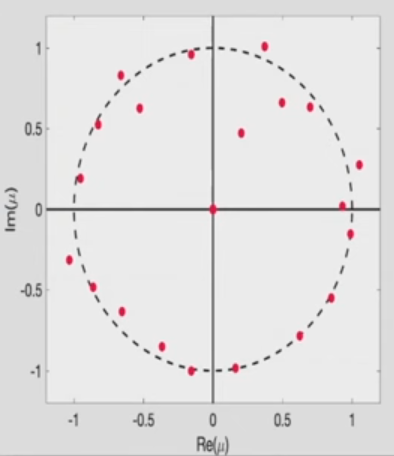
- 在复平面绘制:横轴实轴,纵轴虚轴。描述:0附近有很多eigen values,只有20个非零的eigen values.(非零数量是A较小维度的数量)
如果能量是守恒的,在每个时间点对复数解进行空间积分 =0 不随时间变化,说明系统上的粒子数量守恒:
∫−55∣u(x,t)∣2dx \int_{-5}^{5} |u(x,t)|^{2} dx∫−55∣u(x,t)∣2dx
unitary matrix 酉矩阵 这个方法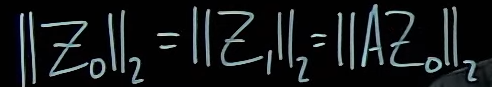

unitary prediction 可以预测更长的时间,牺牲了部分准确性(short-term accuracy)。从长远来看,解决方案保持有界(bounded error)且相对接近。(regular DMD方法在更长的时间尺度误差会很大)
参考
https://www.youtube.com/watch?v=w-CjCteRPuU
deepseek帮助理解 https://chat.deepseek.com/
维基百科 借鉴公式 https://en.wikipedia.org/wiki/Dynamic_mode_decomposition

















 3989
3989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









