






我们或多或少都听说LLM大模型是先“训练”出来,然后再用于“推理”,那怎么理解这个“训练”过程?
是不是经常听说行业性场景中要使用垂域大模型,比通用大模型效果会更好,然后都说垂域大模型是“微调”出来的,那么什么是“微调”?和上面说的“训练”是什么关系?
当你尝试去深入了解这些问题时,搜到的各种介绍是不是都有点深奥?看到预训练、后训练、监督微调、强化学习、低秩适应、奖励模型等一堆概念是不是有点懵逼?
本文对这些概念和模式进行梳理汇总,并结合DeepSeek和Qwen两个案例进行说明,方便像我一样从信息化领域转型过来刚入门的同学也能快速了解“训练”的范围和基础逻辑。
前排提示,文末有大模型AGI-优快云独家资料包哦!
预训练(Pre-Training)和后训练(Post-Training)
“训练Training”其实是多年前机器学习时代就有的概念,把机器学习模型可以想象成一个包含有多元变量的数学函数公式y=w1x1+w2x2+...+wnxn+b,其中X1、X2...Xn就是预先选择好要参与计算的特征变量,然后利用一组包含特征值x和结果值y的历史数据,进行训练得到就是各个特征变量的权重系数W1、W2...Wn,这样这个函数就建立起来(训练出来)了,然后预测过程就是将新的一组变量x代入这个函数公式(模型)进行计算,得到函数结果y就是预测值。
虽然大模型本质和机器学习差异还是巨大的,比如大模型的训练过程是不需要人工预先选择/设计特征x的,而是自动学习提取出来的;大模型的权重系数W的数量是巨大的,几十亿到上万亿参数量;大模型的推理是基于词向量的概率推理,和机器学习这种确定性映射计算不同等。
但为了便于理解,我们还是可以将大模型的训练过程简单理解成以上数学函数的训练过程,最终都是为了训练得到这个函数的一套权重参数(只不过大模型的这个函数公式特别通用化、变量特征不固定、权重参数量特别多)。这个过程就包括预训练(pre-training)和后训练(post-train),其相互关系如下:
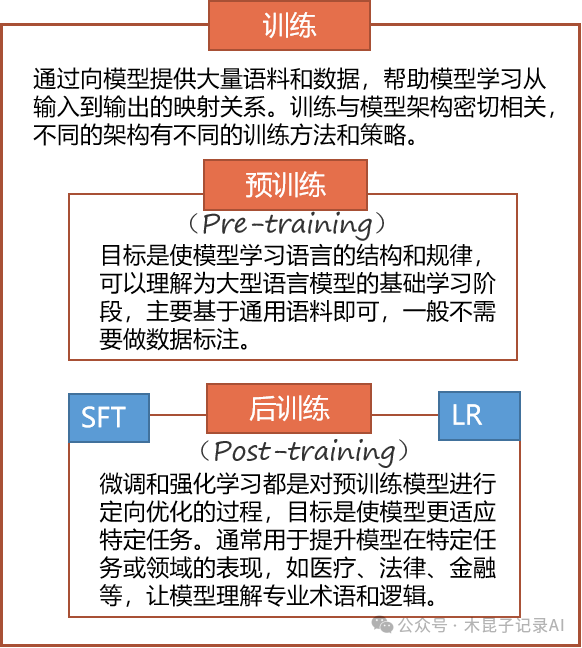
预训练(pre-training)得到的叫基座模型,可以认为是得到数学函数的一套基础权重参数,可以满足一般场景的预测和推理需要。
后训练(post-train)则是在这个基座模型基础上,结合业务场景需要和行业知识数据等进一步训练,最终是调整了基座模型的某些权重参数,以更精准的满足具体业务场景预测和推理需要。
监督微调(SFT)和强化学习(RL)
后训练(post-train)内部又包含监督微调Supervised Fine-Tuning(SFT)和强化学习Reinforcement Learning(RL)两个方向,其主要实现机制对比如下:
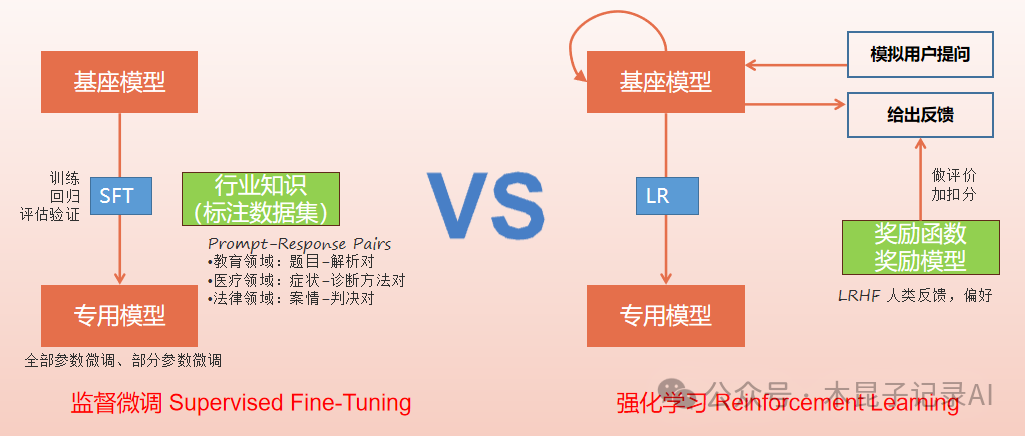
先利用前文所述数学函数的例子,来看看监督微调与强化学习的区别:监督微调是要准备一组特征值X和结果值Y(也就是所谓的标注/标签)组成的数据集来进行训练,通过调整函数的权重参数,让它的预测值与结果值Y尽可能接近,它的核心目标就是要最小化预测值与真实标签的误差;而强化学习则不需要预先准备好结果值Y,它只要提供输入让函数模拟计算,再通过与环境的交互获得反馈(奖励或惩罚),通过调整参数尽可能获取奖励,它的核心目标是要能最大化长期累积奖励期望值。
更形象的比喻,监督微调有点像刷练习题,预先准备好题目和标准答案,通过同类题目的反复练习和纠错(调参),确保碰到新题也能作对;而强化学习有点像模拟考,需要阅卷老师评价,通过反复模拟考,提升书写规范性、掌握时间分配、符合阅卷老师倾向等,以尽可能得高分。
如上所述监督微调Supervised Fine-Tuning(SFT)核心是要用到精确标注的数据集,而且是输入(特征)/输出(标签)成对出现的数据集,比如教育领域的题目和解题方法,医疗领域的症状和诊断方法,法律领域的案情和判决结果等,经过微调部分参数或全部参数,得到一个适用于特定行业领域更精准的专有模型。
这里推荐大神“智能体AI”写的《你真的了解大模型怎么“调”?四种主流LLM微调方法详解》这篇文章,基础逻辑讲得非常清晰,按微调的代价从高到低包括:全量微调Full-Tuning给基座模型“重塑金身”,相当于对以上所说数学函数的权重参数w全部都调整;冻结部分参数Freeze-Tunging只调“头部”参数;低秩适应LoRA给基座模型加外挂配件,相当于不用改模型本身参数,而是通过做加法,在基座模型上额外增加一些小的数学函数,以确保最终预测和推理结果也能符合行业特性;还有更轻量的量化低秩适应QLoRA,是把基座模型先量化压缩后,再做加法。
强化学习Reinforcement Learning(RL)的核心逻辑和微调SFT差别很大,它核心是通过奖励函数/奖励模型(Reward Model)的方式,来引导大模型形成一定的“肌肉记忆”,就是通过对模型输出,选择某些质量维度(如回答的有用性、安全性)进行评价,生成奖励分数,来指导大模型自我优化方向,举个例子可能更好理解:
比如我们常用的一些聊天对话大模型,之所以能够提供所谓的“情绪价值”,之所以不会出现暴力和涩涩的回答,很大程度上是通过强化学习实现的,在强化学习期间,如果大模型的输出是温暖和正面的,奖励模型就给它加分,经过长时间的强化学习引导,大模型的回答自然就会符合这些价值观和偏好。
所以强化学习的核心就在于奖励模型,这个才是灵魂和难度所在,当然强化学习内部又还有多种策略,比如RLHF(人类反馈强化学习)、PPO(近端策略优化)、GRPO(群体相对策略优化)等,后面案例中也会有所展开。
DeepSeek的模型谱系示例
接下来我们用DeepSeek的模型谱系案例,来理解上述预训练、监督微调和强化学习等不同训练方法的具体实践:
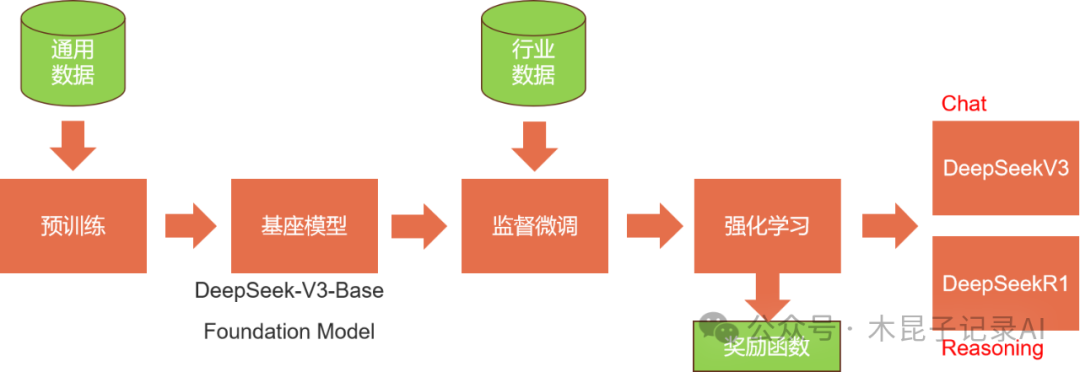
如图,我们都很熟悉DeepSeek有两种比较常用的模型,通用语言模型V3和推理增强模型R1,这两种模型实际都是在基座模型DeepSeek-V3-Base基础上经过监督微调和强化学习出来的。
和我们一般认知有所不同,都说R1是基于V3的,实际指的是基于V3-Base这个基座模型(Foundation Model)。
然后用于聊天对话的V3,实际也是在V3-Base基础上经过专门的后训练得出来的(基于标注好的问答数据集做SFT,基于强化学习评价引导等),所以才能在聊天对话中提供“情绪价值”。
而R1则是推理增强模型,其核心也包括监督微调SFT过程,利用带思维链推理过程标注的数据集;也包括强化学习RL过程,利用奖励模型来评分(如有推理过程和格式就加分,推理过程越清晰得分越多等)。经过多轮次交替最终得到这种推理增强模型,
额外提一句:R1推理模型因为有Thinking思考过程,响应时间更慢一些,但可解释性更强一些,所以更适合复杂分析和总结的场景,而需要即时响应并反馈的场景,则更适合用通用语言模型V3。五一前夕出来的Qwen3模型,则是一个混合推理模型,可以按需开启/关闭推理思考过程。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









