




 本文介绍了如何使用NLTK库在英文文本中进行句子切割,特别强调了自定义词典对分词效果的影响。通过实例展示,注意到专有名词如'Mr.Smith'未被正确拆分,探讨了如何改进参数设置以提高准确性。
本文介绍了如何使用NLTK库在英文文本中进行句子切割,特别强调了自定义词典对分词效果的影响。通过实例展示,注意到专有名词如'Mr.Smith'未被正确拆分,探讨了如何改进参数设置以提高准确性。
因为我这里已经下载过NLTK了,所以就不提供安装教程了,搜一搜都能找到。
这里就直接演示对英文句子切分:
from nltk.tokenize.punkt import PunktSentenceTokenizer, PunktParameters
def cut_sentences_en(content):
punkt_param = PunktParameters()
abbreviation = ['i.e.', 'dr', 'vs', 'mr', 'mrs', 'prof', 'inc'] # 自定义的词典
punkt_param.abbrev_types = set(abbreviation)
tokenizer = PunktSentenceTokenizer(punkt_param)
sentences = tokenizer.tokenize(content)
return sentences
测试:
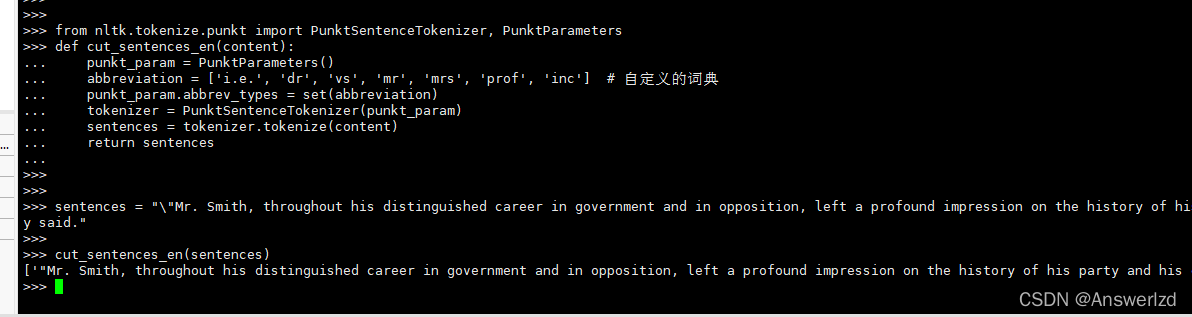
可以发现Mr. Smith并没有被分开。

















 2432
2432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









