




1.HTTP层请求的类型有哪些?
2.GET和POST的使用场景,有哪些区别?
3.HTTP的长连接是什么?
4.HTTP默认的端口是什么?
5.HTTP1.1怎么对请求做拆包,具体来说怎么拆的?
6.HTTP为什么不安全?
7.HTTP和HTTPS 的区别?
8.HTTPS握手过程说一下
9.HTTPS是如何防范中间人的攻击?
10.Http1.1和2.0的区别是什么?
1.HTTP层请求的类型有哪些?
GET:用于请求获取指定资源,通常用于获取数据。
HEAD:类似于GET请求,但只返回资源的头部信息,用于获取资源的元数据而不获取实际内容。
PUT:用于向服务器更新指定资源,通常用于更新已存在的资源。
POST:用于向服务器提交数据,通常用于提交表单数据或进行资源的创建。
DELETE:用于请求服务器删除指定资源。
2.GET和POST的使用场景,有哪些区别?
GET 的语义是从服务器获取指定的资源,GET 请求的参数位置一般是写在 URL 中,URL 规定只能支持 ASCII,所以 GET 请求的参数只允许 ASCII 字符 ,而且浏览器会对 URL 的长度有限制。
POST 的语义是根据请求负荷(报文body)对指定的资源做出处理,POST 请求携带数据的位置一般是写在报文 body 。

3.HTTP的长连接是什么?
长连接时建立一次连接后,可以交互多次,也就是请求多次,响应多次。

如果每次请求都要先建立连接,那对于频繁请求的场景太过浪费时间,因此进行了改进,提出了长连接。
具体的实现机制是:HTTP 的 Keep-Alive + keepalive_timeout。在响应头部的connection:设定Keep-Alive或者close。目前HTTP1.1 默认开启,要关闭在头部加上close。
这里有一个知识点:HTTP的长连接和TCP的长连接的区别
HTTP 的 Keep-Alive 也叫 HTTP 长连接,该功能是由「应用程序」实现的,TCP 的 Keepalive 也叫 TCP 保活机制,该功能是由「内核」实现的,发送探测报文。
4.HTTP默认的端口是什么?
http 是 80,https 默认是 443。
5.HTTP1.1怎么对请求做拆包,具体来说怎么拆的?
第一次遇到这个问题,觉得莫名其妙,明明HTTP是一个报文一个报文的发送接收,怎么还要拆包粘包?
尽管HTTP是报文级的协议,但它并不是直接在应用层发送独立的报文,而是依赖于TCP连接来进行数据的流式传输。TCP传输的数据是流式的,它会将所有数据当做一个字节流来传送,而不是按报文来传送。因此,HTTP虽然是一种基于报文的协议,但在TCP层面,发送的数据是一个字节流。这就意味着,如果没有额外的指示,接收方无法知道每个HTTP报文的结束位置,因为TCP没有报文边界的概念。
为了让接收方知道每个HTTP报文的结束位置,HTTP协议引入了Content-Length头字段。这个字段告诉接收方“接下来会有多少字节的消息体”,从而明确每个报文的结束位置。
6.HTTP为什么不安全?
HTTP 是明文传输容易造成数据泄露和数据篡改,HTTP不提供身份验证机制,容易受到中间人攻击(MITM)。
7.HTTP和HTTPS 的区别?

8.HTTPS握手过程说一下
一来一回两次,一次交换必要信息(服务器端分多次回应),在第一次基础上各自都得到会话密钥,进行第二次的确认。
客户端先发起对话(Client Hello),提出要求。
服务器应答(Server Hello)并证明自己身份(发送证书)。
双方交换“秘密”信息(客户端密钥交换、服务器密钥交换)。
双方都用共享的密钥结束对话并确认(Finished)。
具体行为:
记住最终的会话密钥是 双方的随机数+随机数(pre-master key)计算出来的。服务器获得pre-master key的方式是,客户端利用在验证中心得到的服务器公钥加密的。
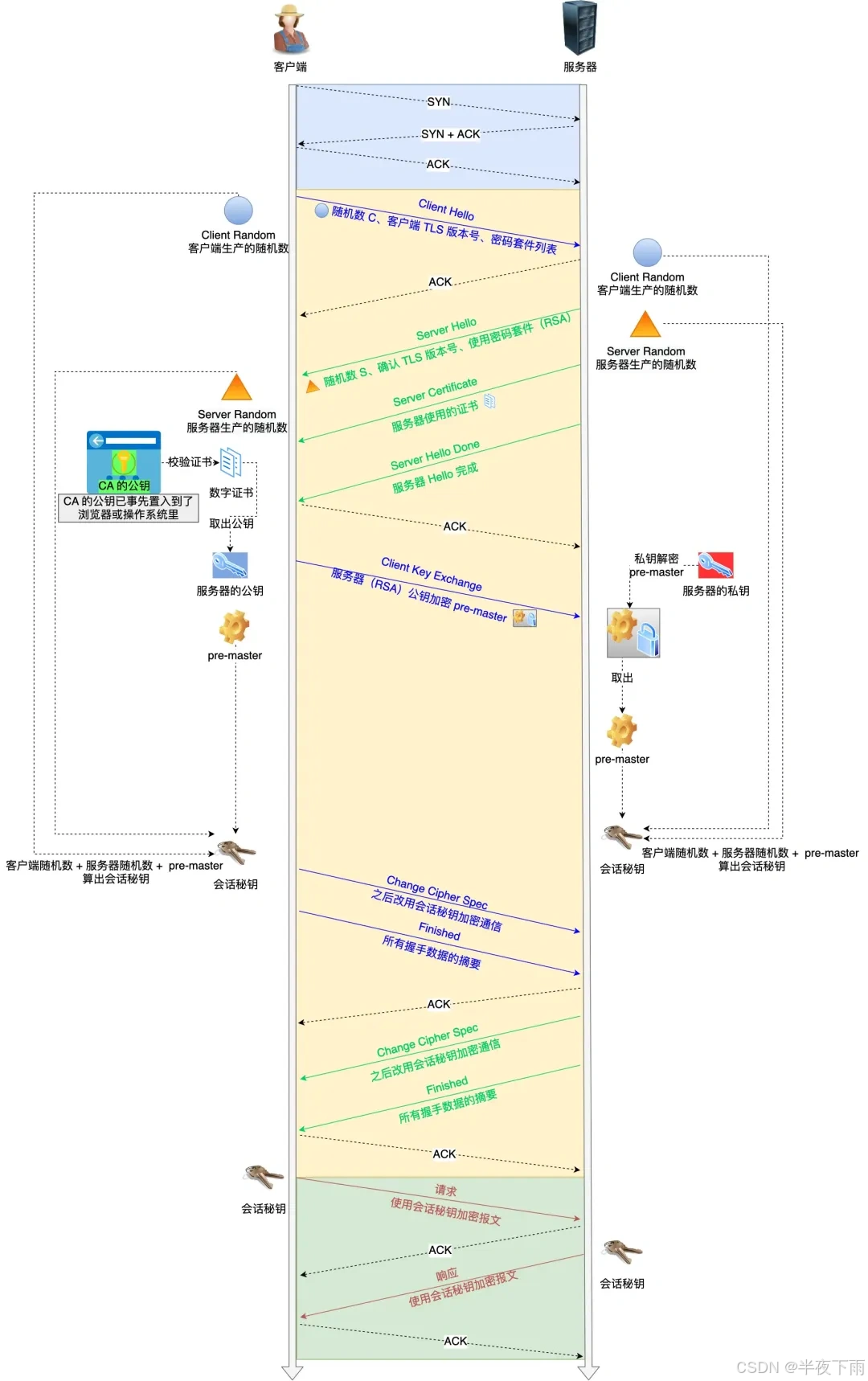
9.HTTPS是如何防范中间人的攻击?
主要还是非对称加密,中间人无法获取私钥,因此无法得到pre-master key。

10.HTTP1.1和2.0的区别是什么?


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









