




1.ZSet用过吗?
2.Zset 底层是怎么实现的?
3.跳表是怎么实现的?
4.跳表是怎么设置层高的?
5.Redis为什么使用跳表而不是用B+树?
6.压缩列表是怎么实现的?
7.介绍一下 Redis 中的 listpack
8.哈希表是怎么扩容的?
9.哈希表扩容的时候,有读请求怎么查?
10.String 是使用什么存储的?为什么不用 c 语言中的字符串?
1.ZSet用过吗?
Zset(有序集合)。一般是设计排序采用到。比如说排行版之类的。
ZADD key score1 member1 [score2 member2] //先分数再对应的元素名。
ZCOUNT key min max //最大最小
ZINCRBY key increment member //按increment递增
2.Zset 底层是怎么实现的?

在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
listpack 也叫紧凑列表,它的特点就是用一块连续的内存空间来紧凑地保存数据,同时为了节省内存空间,listpack 列表项使用了多种编码方式,来表示不同长度的数据,这些数据包括整数和字符串。

Zset 对象在执行数据插入或是数据更新的过程中,会依次在跳表和哈希表中插入或更新相应的数据,从而保证了跳表和哈希表中记录的信息一致。
3.跳表是怎么实现的?
Redis 只有 Zset 对象的底层实现用到了跳表,跳表的优势是能支持平均 O(logN) 复杂度的节点查找。
跳表是在链表基础上改进过来的,实现了一种「多层」的有序链表。
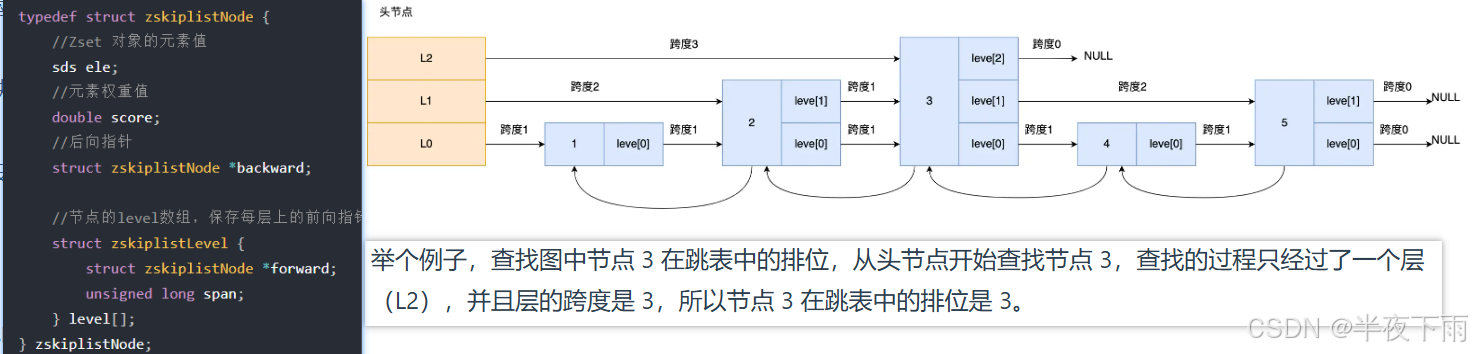
查询过程:
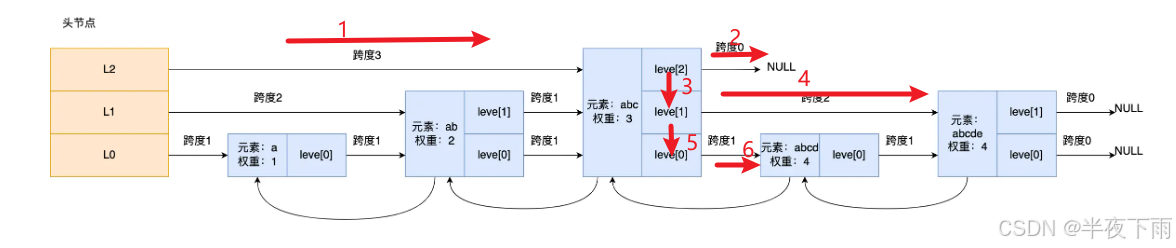
4.跳表是怎么设置层高的?
跳表的相邻两层的节点数量最理想的比例是 2:1,查找复杂度可以降低到 O(logN)。
如果采用新增节点或者删除节点时,来调整跳表节点以维持比例的方法的话,会带来额外的开销。

这个初始头结点层数,每个redis版本是不一样的。
5.Redis为什么使用跳表而不是用B+树?

也是因为不用考虑磁盘IO的性能问题,所以redis从算法实现难度上来比较,选择比平衡树要简单得多的跳表。特别
6.压缩列表是怎么实现的?
主旨就是为了节约空间,entry之间紧密相贴。
压缩列表是 Redis 为了节约内存而开发的,它是由连续内存块组成的顺序型数据结构,有点类似于数组。
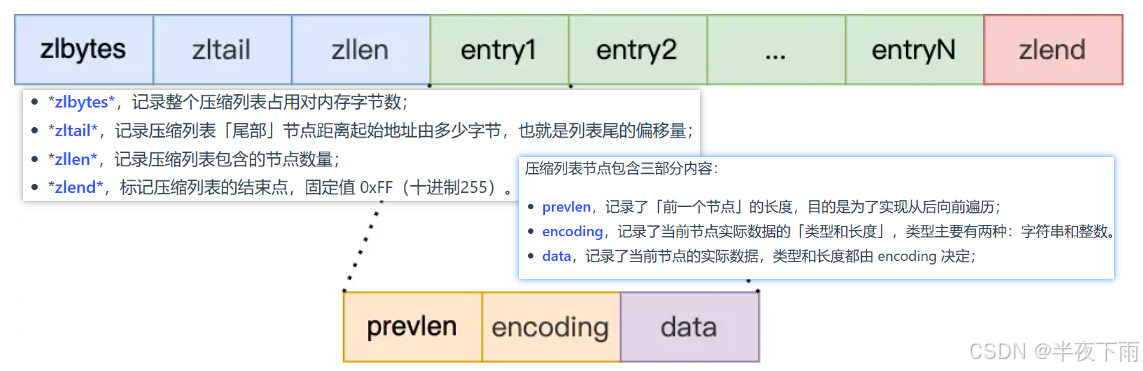
压缩列表的缺点是会发生连锁更新的问题,因此连锁更新一旦发生就会导致压缩列表占用的内存空间要多次重新分配,这就会直接影响到压缩列表的访问性能。
这也是quicklist和listpack被提出的原因,是为了解决连锁更新的问题。
7.介绍一下 Redis 中的 listpack?
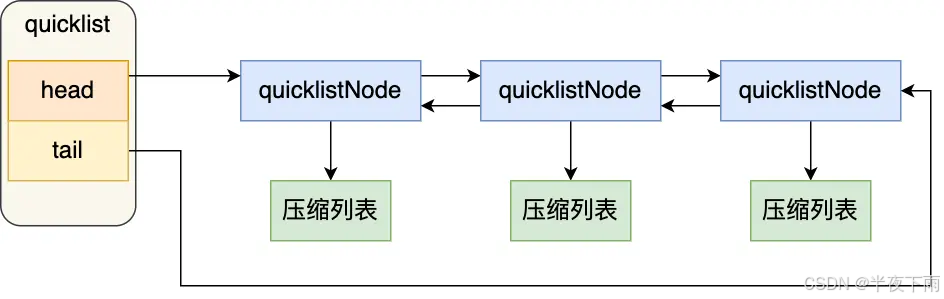
通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。
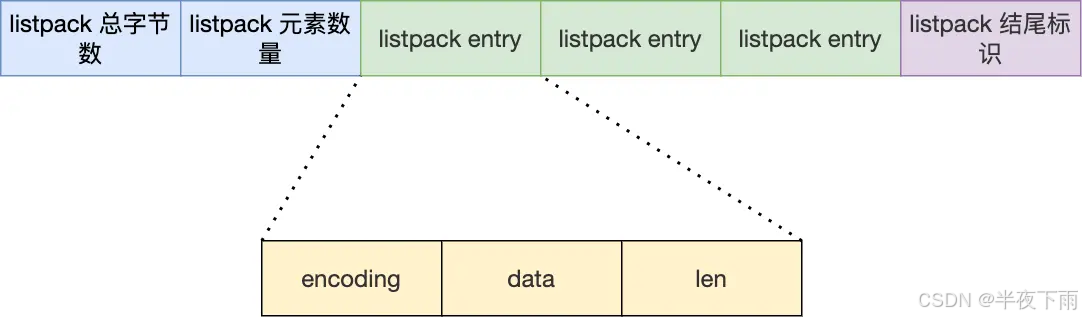 listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。
listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。
8.哈希表是怎么扩容的?
进行 rehash 的时候,需要用上 2 个哈希表了。

如果一口气进行全部的迁移,那么会造成redis阻塞,无法处理其他请求。
因此,使用渐进式的rehash。

9.哈希表扩容的时候,有读请求怎么查?
查找一个 key 的值的话,先会在「哈希表 1」 里面进行查找,如果没找到,就会继续到哈希表 2 里面进行找到。
10.String 是使用什么存储的?为什么不用 c 语言中的字符串?
SDS。
那当然是因为有需要避免的问题。
C语言的字符串长以下这样:


SDS长下面这样:


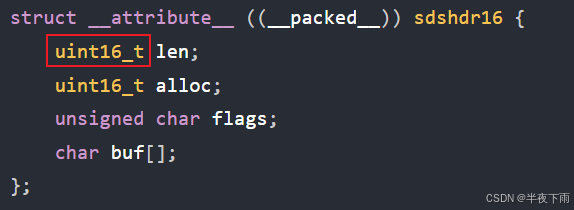
Redis 一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。

















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









