




 在使用Tesseract 4.0进行图像文字识别时遇到崩溃问题,错误发生在调用"TessBaseAPIRecognize()"时。经过调试和分析,确定不是空指针或野指针导致,而是与字库相关。通过尝试使用不同版本的字库,发现30多M的"4.00"版本字库解决了崩溃问题。问题在于原始字库中可能缺少某些字符,导致识别特定字符时程序崩溃。
在使用Tesseract 4.0进行图像文字识别时遇到崩溃问题,错误发生在调用"TessBaseAPIRecognize()"时。经过调试和分析,确定不是空指针或野指针导致,而是与字库相关。通过尝试使用不同版本的字库,发现30多M的"4.00"版本字库解决了崩溃问题。问题在于原始字库中可能缺少某些字符,导致识别特定字符时程序崩溃。
近日在使用Tesseract4.0时踩了个坑,在识别一张质量较差的图片时崩溃了。
原图文字被切成多行,每一行文字调用一次Tesseract识别。在某一次崩了,偶发bug。
Release崩溃截图如下:

进入Debug模式崩溃截图如下:

调试发现,是在在某次调用"TessBaseAPIRecognize()" 时崩溃了。
百度搜索"读取位置0x000000时发生访问冲突",都说是空指针,野指针的问题。
但实际调试发现"handle"正常,并不是指针问题。
然后根据Release崩溃信息去看源码,如图:

断言在"contains_unichar_id(unichar_id)",分析这个英文意思:包含字符id 。
这个字符的ID不存在?字符不就是在字库里吗?
换个字库试试看
github找到Tesseract4.0的字库,如图:
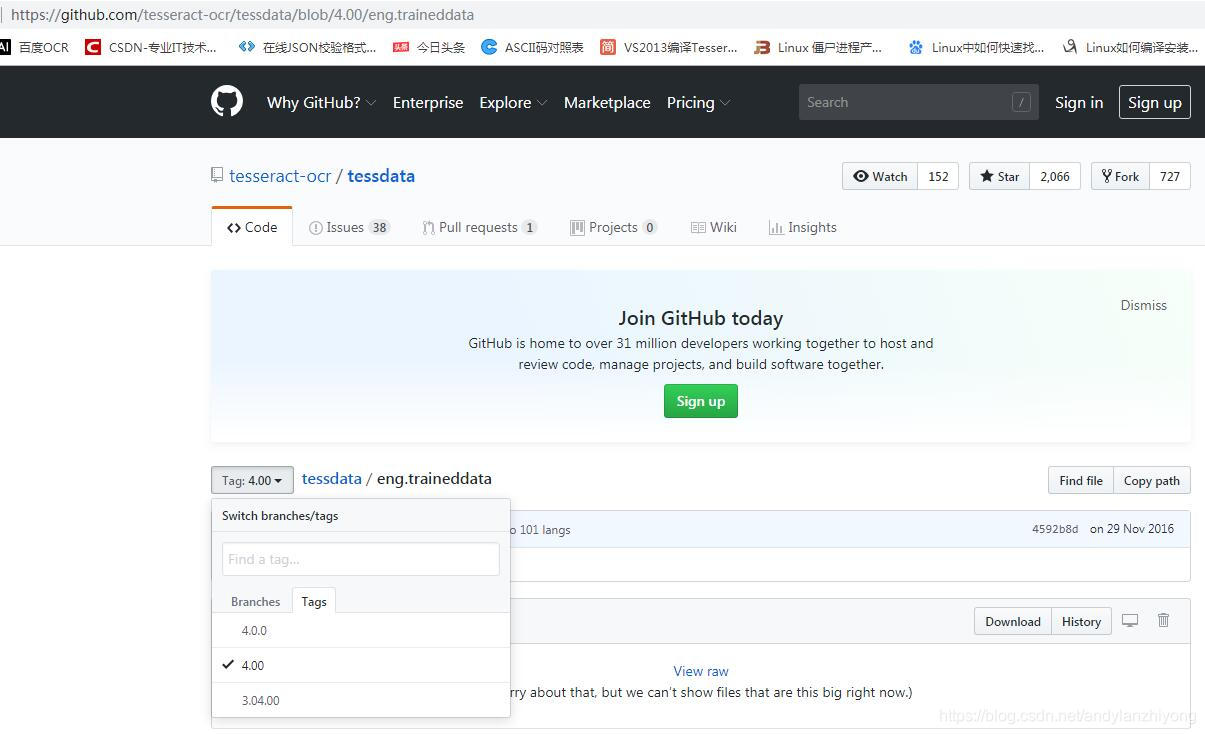
其中"4.0.0"与“master”版本字库都是20多M大小(好像是一样的)
"4.00"版本字库30多M
我之前使用的字库是20多M,那直接换这30多M的字库试一下。
换掉字库之后,运行竟然成功了。。。
识别结果如下:
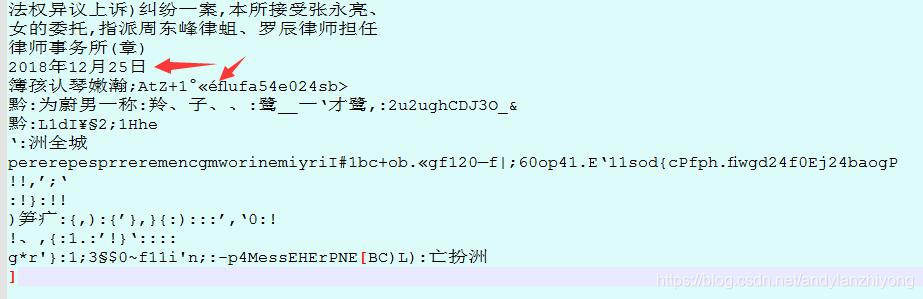
发现第5行有个特殊字符,程序崩溃 。。。。。。
似乎问题就在字库这了
这不是个坑货吗,字库里没有的字就崩溃?
此问题纯个人分析,如有不同看法,欢迎交流

















 1916
1916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









