



 本文深入探讨Python中的匿名函数、列表生成式、生成器和装饰器等高级特性,解析其工作原理及应用场景,帮助读者掌握Python编程精髓。
本文深入探讨Python中的匿名函数、列表生成式、生成器和装饰器等高级特性,解析其工作原理及应用场景,帮助读者掌握Python编程精髓。
1.匿名函数lambda:
没有函数名。(所以匿名函数没有函数名,可以赋值给变量,当没有变量时,则被回收。)
eg。 calc = lambda x:x*3
变量回收:变量不被引用,则被内存回收。当变量被一次引用,二次引用,则不会被回收,
x =1
y = 1
del x
解释:1这个值被x 第一次引用,被y 二次引用,x 和y 相当于 1的门牌号,del x 相当于删掉的是门牌号x,1还存在,当内存中定期扫描值得时候,发现1 长期没有被调用,则删掉1.
2.列表生成式:使代码更简洁。
a= []
for i in range(10)
a.append(i x 2)
a
上面的代码用列表生成式来表达就是[ix2 for i in range(10)],或者更复杂一点就是将函数套用进去[func(i) for i in range(10)]
3.生成器:
res = [i*2 for i in range(10)] #列表生成式
res = (i*2 for i in range(10)) #生成器,调用的时候才生成值,节省空间。
1.只有在调用时才会生成相应的数据。
2.不支持列表切片,截断。
3.生成式生效时在内存里就是一个表达式的存在。
4.节省内存,只记忆当前位置,可以调用后面的参数,只有一个c.__next__()方法,只能一个个取,不能指定的取值或者跳跃的取值,不可以调之前的参数。 Python2.7中是c.next().
5.赋值语句 a,b=b,a+b 相当于 t = (b,a+b), a = t[0],b=t[1]
6.下面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了


def fib(max):
n,a,b = 0,0,1
while n < max:
#print(b)
yield b
a,b = b,a+b
n += 1
return 'done'
7.这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
在上面fib的例子,我们在循环过程中不断调用yield,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。
同样的,把函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
8.在生成器中,next是调用参数,send是传参数+调用函数!!!!!!!!!!!!!!
4.装饰器
定义:本质是函数,装饰其他函数就是为其它函数添加附加功能。
原则:1.不能修改被装饰的函数的源代码
2.不能修改被装饰的函数的调用方式。
3.装饰器对原函数是透明的,它并不知道装饰器对它进行了装饰。因为它的源代码没变,调用方式也没变。
实现装饰器知识储备:
1.函数即“变量”
2.高阶函数:
3.嵌套函数:
高阶函数+嵌套函数=》装饰器
-------------->
1.函数即变量
变量存在于内存之中,python的内存回收机制是解释器去做的。
eg. x=1, test= "函数体“”
整个内存相当于一栋大楼,里面有好多小房子,1 存在于一个小房子,x是1 的门牌号,函数体存在于一个小房子,test是函数体的门牌号。当门牌号被del删除之后,不存在 了,1/函数体也不存在了,内存就回收了。
匿名函数lambda: 有的函数是可以不定义名字。calc = lambda x:x*3.匿名函数没有函数名,这样匿名函数就会被回收。可以将lambda赋值给一个变量。
2.高阶函数
a.把一个函数名当做实参传给另外一个函数
b.返回值中包含函数名
3.嵌套函数: 在一个函数的函数体内用def 定义另一个函数,叫做函数嵌套。
import time
def timer(func):
def deco(*args,**kwargs):
start_time=time.time()
func(*args,**kwargs)
stop_time=time.time()
print("the func run time is %s"%(stop_time-start_time))
return deco
@timer #test1= timer(test1)
def test1():
time.sleep(3)
print("in the test1")
test1()
@timer
def test2(name,age):
time.sleep(1)
print("name:",name,age)
test2("alex",30)
3.json序列化 反序列化
json.dumps() ---序列化,---挂机,实现把内存的数据对象存到硬盘上。
json.loads() ---反序列化,--恢复,实现把硬盘上的数据加载回来。
json只能处理简单的数据类型,比如字典,字符串,列表。json是所有语言里通用的,是为了进行不同语言之间的数据交互。xml正在逐渐被json取代。
调用时一般需要 import json
处理复杂的数据类型时需 import pickle,用法与json完全一样.Pickle 只能用于python,其他语言不适用。
Pickle.dumps() / Pickle.loads()
pickle.dump(info,f) = f.write(pickle.dumps(info))
data=pickle.load(f) = date = pickle.loads(f.read())
建议dump一次 load一次,单独存放备份文件。
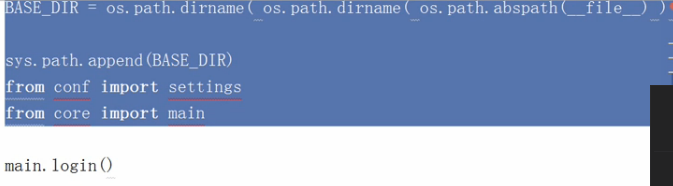
跨目录调用.py: 动态的获取绝对路径,然后动态的加到系统的环境变量里。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









