







当前,全球对AI智能体(AI Agent)的关注度达到前所未有的高度。这项技术所展现出的潜力无疑令人振奋,为我们勾勒出未来的广阔前景。然而,尽管在演示中表现亮眼、前景可期,但在真实的产品场景中,要实现AI智能体持续而稳定的运行却依然面临巨大挑战。即便是微软、苹果、亚马逊这类科技领军企业,在将AI能力融入实际产品的过程中也频频遭遇挫折。
那么,问题究竟出在哪里?为何那些在实验室中显得无比强大的AI智能体,一旦进入真实使用环境、面对真实用户,就显得如此不稳定?关键答案并不在于大语言模型(LLM)本身,不在于工具调用,甚至也不完全在于智能体的循环机制。最根本的原因,往往隐藏在一个容易被忽视的环节:大规模上下文工程。
简而言之,上下文工程既是一门科学,也是一门艺术。它的核心在于,在AI与用户交互的每一个时刻,都能精准筛选、组织并传递最相关的信息给大语言模型进行处理。本文将深入剖析在构建AI智能体过程中常见的误区,并分享四条来自实践的关键经验,帮助你理解:为什么上下文,才是决定AI智能体能否成功落地的核心所在。
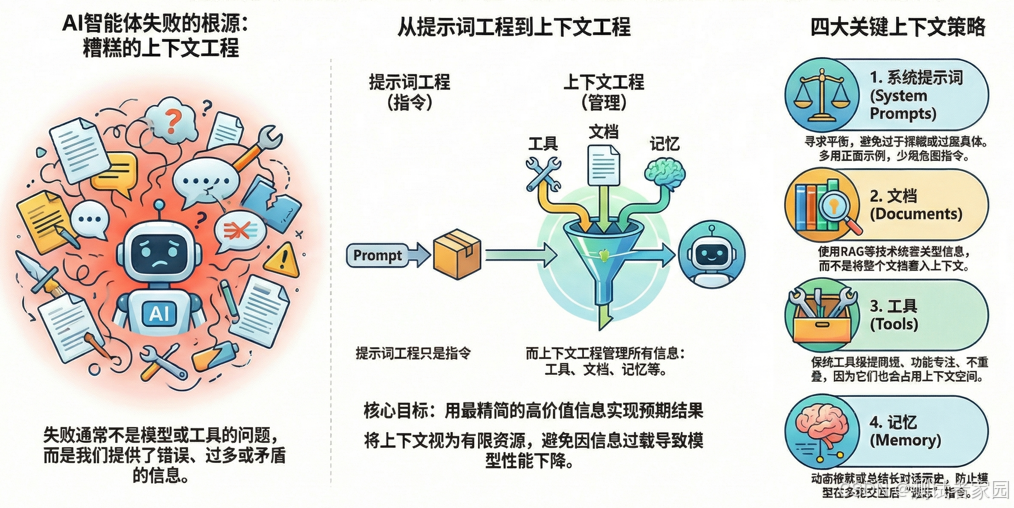
一、上下文是有限资源,不是无限的存储桶

上下文窗口的使用存在一个核心悖论:更大,并不等同于更优。一种常见的误解是,更大的窗口意味着可以向模型输入更多信息,从而直接换来更好的输出。然而,我们的实践经验反复证明,事实往往相反——向大型语言模型(LLM)过量灌输信息,反而会损害其性能。
这一问题类似于“大海捞针”。如果只提供少量关键信息,模型通常能准确提取所有相关事实。但若将一整本书都丢给它,并要求找出某个特定细节,其表现便会显著下滑。研究表明,随着上下文窗口被不断填满,几乎所有模型的性能都会出现可观测的下降。尽管某些模型的衰退曲线相对平缓,但这一基本规律普遍存在。正如人工智能公司Anthropic所精准概括的:
上下文应被视为一种有限资源,其边际收益是递减的。
因此,上下文工程的首要目标在于:找到那个能够最大化预期结果概率的、信息密度最高的最简令牌集合。你的任务不是“塞给”模型全部可用资料,而是精确提供它完成任务所必需的最少量、最高质量的信息。举例来说,在面对长文档时,更好的做法并非将整个文档灌入上下文,而是采用检索增强生成(RAG)模式:先检索出大量可能相关的文本片段,再通过一个“重排器”模型筛选出与当前任务最相关、最关键的少数几段。
二、停止告诉AI“不要做什么”

在实践中,经常出现这样一种模式:开发者倾向于根据用户反馈,用不断增加负面指令的方式来“修补”系统提示。每当用户抱怨AI犯了某个错误,最直接的反应就是在提示中追加一条禁令,比如“不要提及这个”或“禁止那样做”。
这种应对方式看似能快速解决问题,实则是一个深远的陷阱。它让开发者陷入一种虽可理解但最终有害的被动修复循环。关键在于:大语言模型并不善于从负面指令中学习,它们更擅长理解和遵循正面范例。
与其试图用上百条禁令告诉模型“什么不能做”,不如为它绘制一张清晰的“目的地地图”。请记住,一个优秀的正面范例,其效果远胜于千言万语的限制。直接向模型展示“一个好的回答应该是什么样子”,远比罗列一系列禁止事项有效得多。
如果你的系统提示因为塞满了各种规则而变得臃肿且难以管理,一个更高级的策略是:将问题拆解为两个阶段,并引入一个路由机制。首先,让模型判断当前请求属于哪种类型,然后根据这个判断,调用一个专门为该类型设计的、简洁而专注的提示来处理具体任务。
这种思维方式的转变至关重要。它将工程的重点从被动的错误修补,转向主动定义正确行为,从而有助于构建出更加健壮、行为更可预测的AI系统。
三、你可能并不需要一个复杂的“智能体”
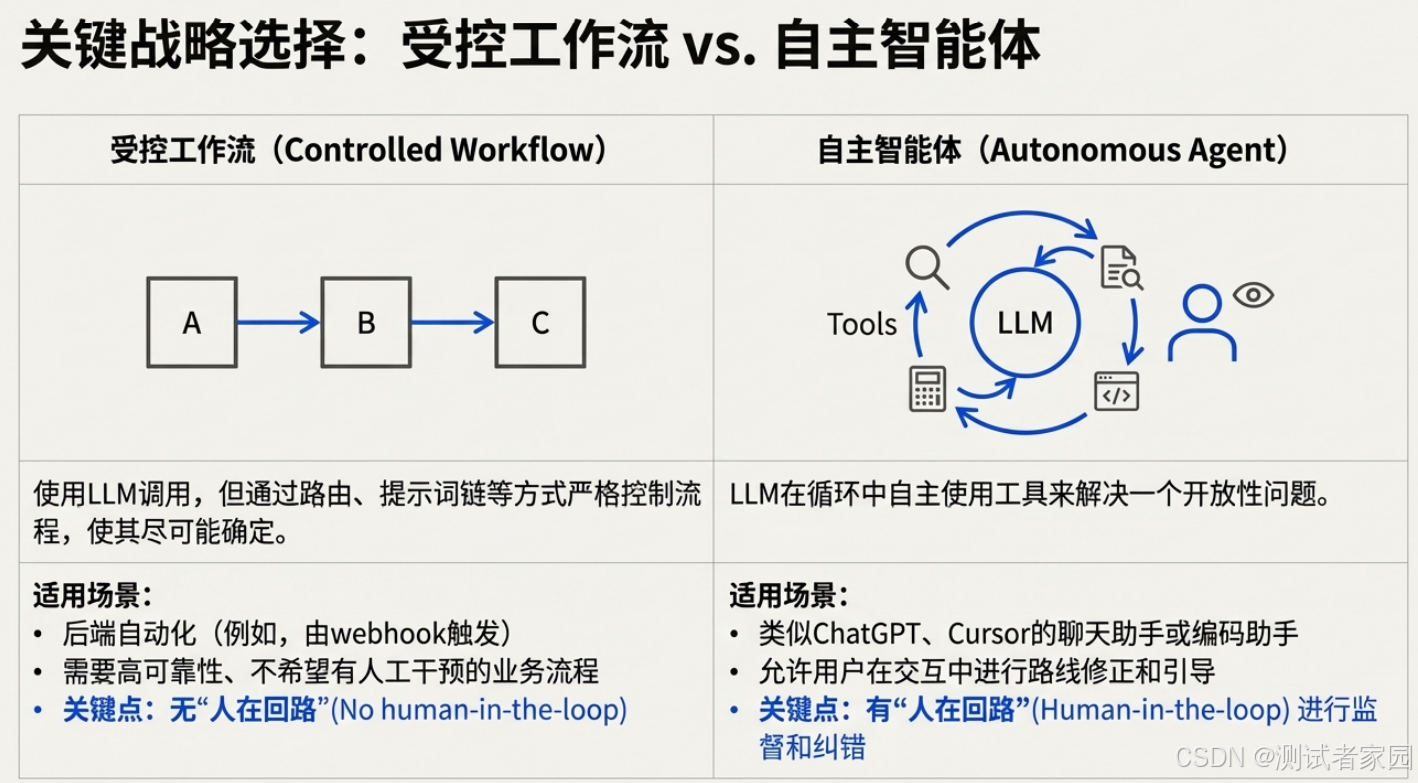
当前,“智能体”这一术语几乎被泛用于所有包含大语言模型的软件中。然而,作为工程师,我们必须清晰区分两种本质上不同的模式:
真正的智能体:指一个能够自主、循环地使用工具来解决开放性问题的系统。典型代表如Cursor或Claude Code这类AI编程助手,它们能根据用户指令,自主完成代码的编写、测试与修改。
自动化工作流:指通过路由、提示链等技术,将复杂任务分解为一系列更简单、更确定的步骤来依次执行。
对于绝大多数商业自动化场景——例如由Webhook触发的后端数据处理流程,自动化工作流通常是更优越、更可靠的选择。这是因为在该模式下,工程师对流程拥有更强的控制力,系统行为更加确定,且通常无需人类在环监督或频繁纠正模型行为。
相反,真正的智能体循环系统更适合用户在场并可实时交互的应用场景,例如对话式AI助手。这类场景允许用户随时介入,对智能体的执行路径进行即时调整与修正。
因此,在项目启动之初,清晰判断你的应用场景究竟需要哪种模式,是一项至关重要的工程决策。选择正确的范式,是构建稳定、可控、符合预期的AI系统的第一块基石。
四、真正的错误隐藏在对话历史中
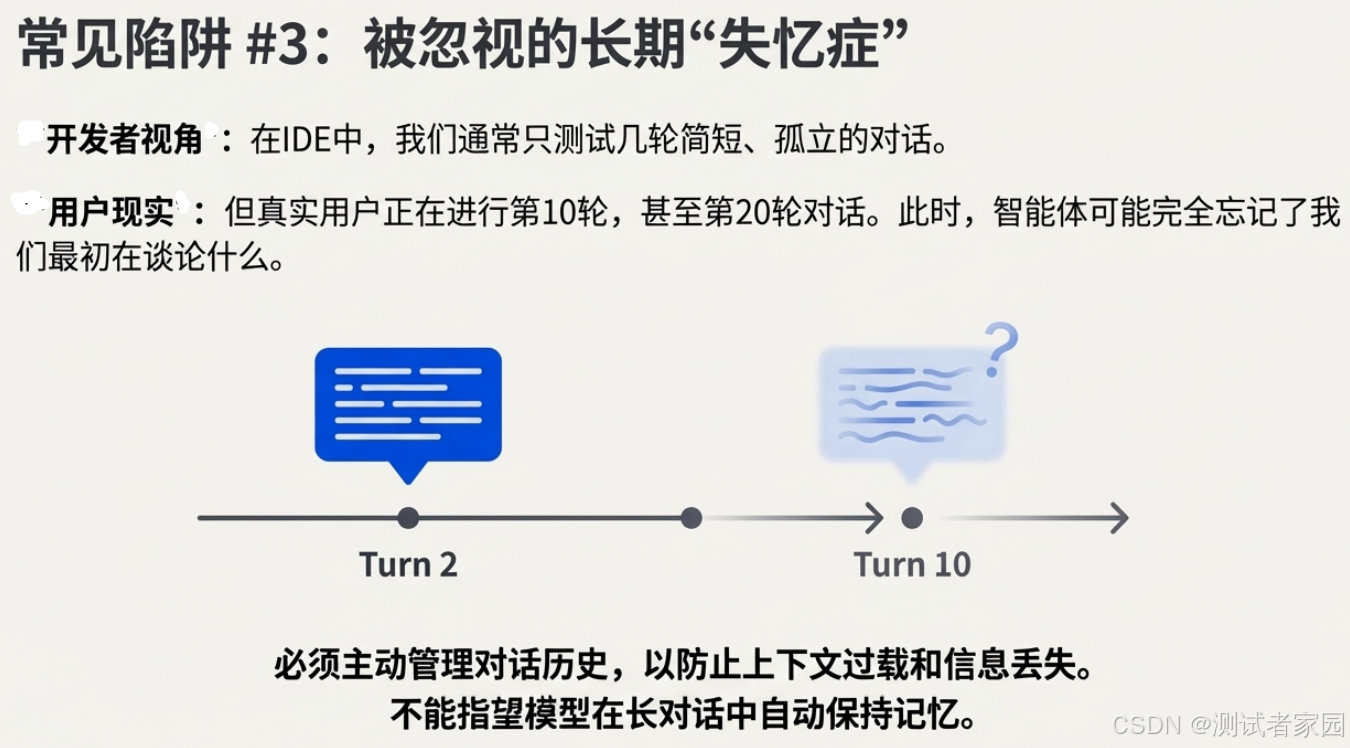
调试AI系统同样遵循一个悖论:真正的问题几乎永远不会在你第一眼看到的地方浮现。在开发阶段进行的简短测试中,系统可能表现得无可挑剔。然而,当用户进行长时间、多轮次的复杂对话后,那些潜伏的问题才会暴露出来——例如,“聊到第十轮时,它似乎完全忘记了我们之前讨论的内容”。

这一问题的根源之所以隐蔽,是因为开发者惯常的调试视角——即IDE中的代码和日志——无法真实反映用户所经历的完整交互上下文。仅仅查看最后一条用户输入和对应的模型输出是远远不够的。要定位问题,你必须借助像Langfuse这样的追踪工具,去完整审查实际传递给模型的全部上下文:这包括系统提示、完整的对话历史、每一次工具调用的细节及其返回结果。
当你能够审视完整的交互追踪记录时,问题的根源往往变得清晰可见。大多数时候,你会发现模型失败并非因为它“缺乏推理能力”,而是因为它“基于糟糕的上下文进行了推理”。这个上下文可能过于庞大臃肿,包含了相互矛盾的信息,或是已经过时的内容。
除了修剪对话历史或进行总结这类基础策略外,一个更具工程效能的模式是引入状态机。通过在数据库中跟踪用户在流程中的确切位置(例如,“用户当前正在填写表单的第二步”),你可以动态地加载与该状态最相关的系统提示片段,从而为模型提供高度聚焦、简洁且时效性强的上下文。这种基于状态的上下文管理,能从根本上提升AI系统在复杂、长程交互中的稳定性和一致性。
结论:上下文工程是新的前沿
总而言之,构建高效、可靠的AI系统,要求我们必须超越基础的“提示工程”思维,转向更系统、更富创造性的“上下文工程”。这不仅是一个技术层面的演进,更代表着一种根本性的开发理念转变:我们正从传统软件开发中编写确定性指令的“if-else”范式,转向构建一个能够持续引导非确定性大语言模型做出最优决策的动态信息环境。这一转变的核心在于,我们不再试图通过精确的指令控制模型,而是通过精心设计的信息结构和流动路径,塑造模型的思考轨迹与决策边界。





















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











