







 本文深入探讨了数学期望,包括离散分布和连续分布的期望,以及正太分布的概念。接着介绍了方差作为衡量数据离散程度的指标,并在机器学习的上下文中,解释了偏差-方差分解,如何评估模型的泛化能力。通过理解这些基本概念,有助于更好地理解和优化机器学习模型。
本文深入探讨了数学期望,包括离散分布和连续分布的期望,以及正太分布的概念。接着介绍了方差作为衡量数据离散程度的指标,并在机器学习的上下文中,解释了偏差-方差分解,如何评估模型的泛化能力。通过理解这些基本概念,有助于更好地理解和优化机器学习模型。
前言
我们经常用偏差-方差分解形式来度量机器学习模型泛化能力的内容。本文将从数学基础来解释其演进过程。我们先从数学期望开始。
1、数学期望
概率论是描述现实世界的一个重要学科。我们从现实世界了解数学规律往往是通过一次一次的抽样开始的。我们没做一个事情就会是一次抽样。同样我们也通过做一个事情的经理(也就是多次抽样)来预测,本次做这件事情的成功概率。这本身就是机器学习或者人工智能的过程。所以期望一词也符合我们在场景中的一个定义。
当前期望在数学领域并不这样笼统,首先我们需要明确的是:期望的本质就是【均值】。同时期望又分为离散分布的期望与连续分布的期望。
1.1 离散分布的期望
首先看一下离散分布期望的原始定义
在概率论和统计学中,数学期望(mean)(或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和,是最基本的数学特征之一。它反映随机变量平均取值的大小。
如果随机变量只取得有限个值或无穷能按一定次序一一列出,其值域为一个或若干个有限或无限区间,这样的随机变量称为离散型随机变量。
以上的表述非常的形而上,也不容易理解。那么我么可以用一些现实中的例子来转述一下,不过要时刻记得之前得到的一个结论:期望的本质就是【均值】
甲乙两人共进行10次打把练习,命中环数与次数的对应关系如下
甲 7环 8环 9环 10环 2次 4次 2次 1次 乙 7环 8环 9环 10环 1次 5次 4次 0次
如果我们想用一个指标来衡量这两个人的射击水平就可以用数学期望,可以做如下符号定义
 代表射击出现的概率,假如我们定义甲打出7环的概率为
代表射击出现的概率,假如我们定义甲打出7环的概率为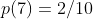 则其他概率可以进行同样的定义,则我们可以根据期望的定义计算甲的射击水平
则其他概率可以进行同样的定义,则我们可以根据期望的定义计算甲的射击水平
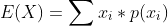
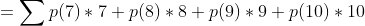
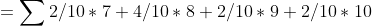
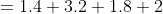
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









