




 本文介绍了作者在研究Hadoop源代码时,对mapper和reduce组件的理解。重点讨论了map()函数、setup()和cleanup()方法,以及Context对象在map任务中的作用。同时,概述了reduce函数的执行过程,强调其与map类似的操作。在配置作业的过程中,提到了job.setMapperClass()和job.setReducerClass()的方法,并简单提及了提交作业到集群的关键步骤。
本文介绍了作者在研究Hadoop源代码时,对mapper和reduce组件的理解。重点讨论了map()函数、setup()和cleanup()方法,以及Context对象在map任务中的作用。同时,概述了reduce函数的执行过程,强调其与map类似的操作。在配置作业的过程中,提到了job.setMapperClass()和job.setReducerClass()的方法,并简单提及了提交作业到集群的关键步骤。
首先初入hadoop家族,了解了一些hadoop运行作业的基本流程,
由于对编写八股文形式的hadoop程序缺少认知,所以翻了翻源代码。
首先有关继承mapper类的源代码主要由几个方法组成
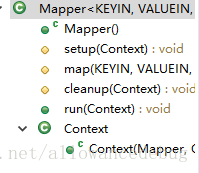
其中map函数是最经常被重写的

源码中只是运用了封装好了的输出类型的Context进行了简单的输出。
听说技术高超的人会重写run方法:

setup函数会在执行map任务之前调用一次
cleanup会在map执行之后执行一次
Context类型封装了像
Configuration conf, TaskAttemptID taskid,
RecordReader<KEYIN,VALUEIN> reader,
RecordWriter<KEYOUT,VALUEOUT> writer,
OutputCommitter committer,
StatusReporter reporter,
InputSplit split
一些任务的配置信息和要输入输出的参数类型。。
reduce函数的源码,仅仅只是将values进行了遍历,然后进行了输出

大概方式与map相同。。
在main函数中,,我们需要做很多需要的配置。。

job.setMapperClass(Map.class);//设置实现了Map步的类
job.setReducerClass(Reduce.class);//设置实现了Reduce步的类
这些也没有什么好说的,拿到自己写的ampper和reduce类class对象,进行反射,得到类名,为日后创建对象运行,这里只是将名字配置到configuration类属性里。

值得提的是上传提交作业的代码是

主要源码

链接到集群,提交作业,等待结果。。。
欢迎关注我的公众号,领取免费干货学习资源


















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









