



一,下载ollama
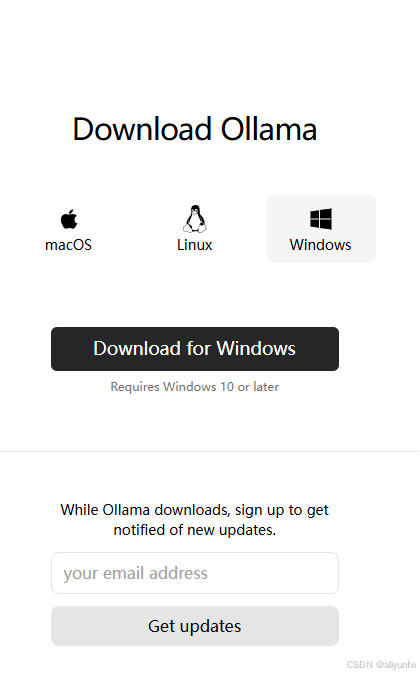
选择合适自己操作系统的版本
下载完成之后运行安装,直接install就行
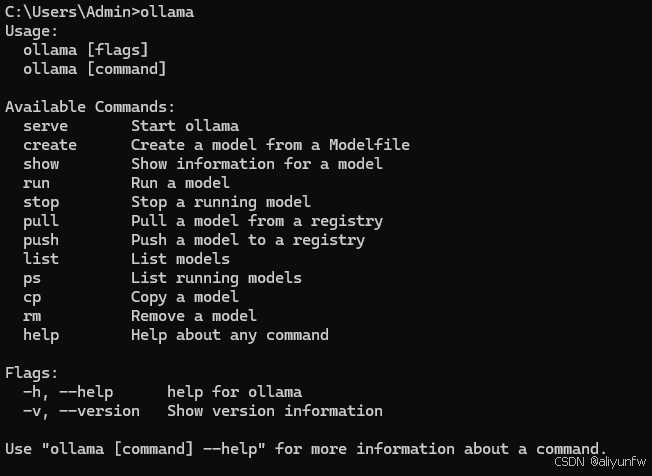
安装完成之后命令行输入ollama就代表安装成功啦
二,安装deepseek模型
在下载ollama的网站中选择deepseek模型
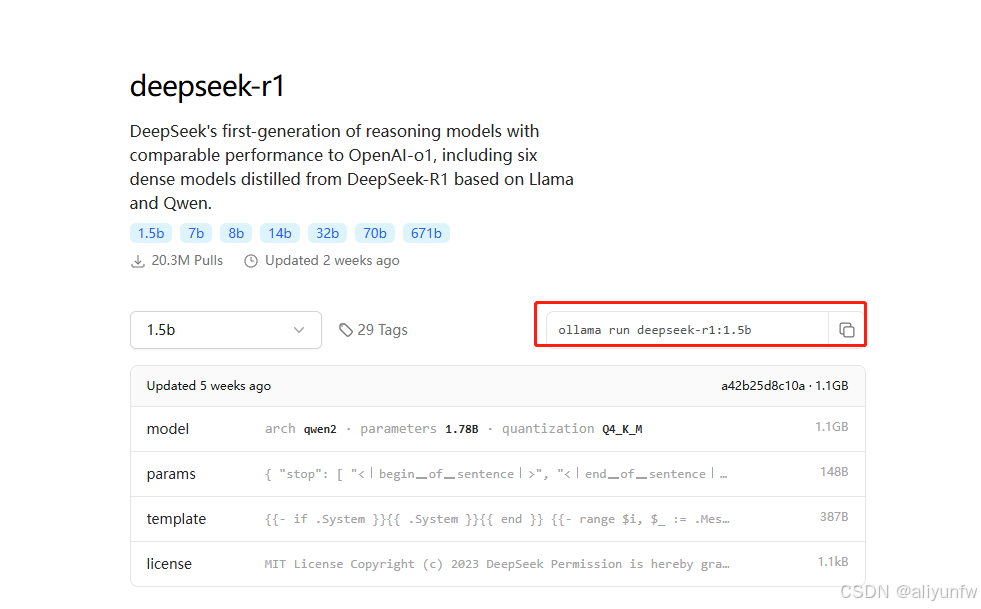
deepseek有多种模型供你选择,选择符合你电脑配置的模型,复制命令后在命令行运行就可以开始下载了
三,安装AnythingLLM
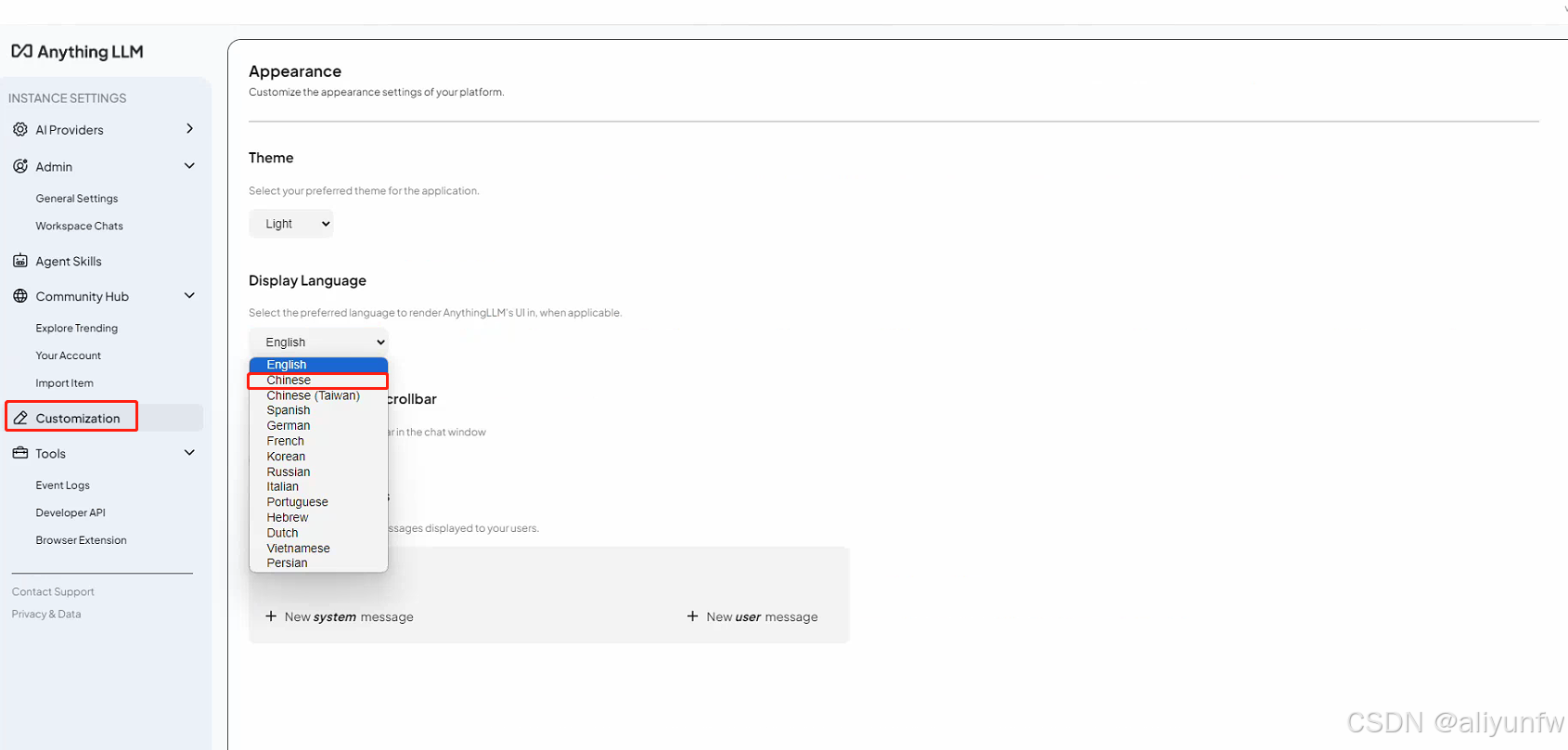
 安装完成之后打开软件,可以在设置里面把默认语言设置为中文
安装完成之后打开软件,可以在设置里面把默认语言设置为中文
创建工作区
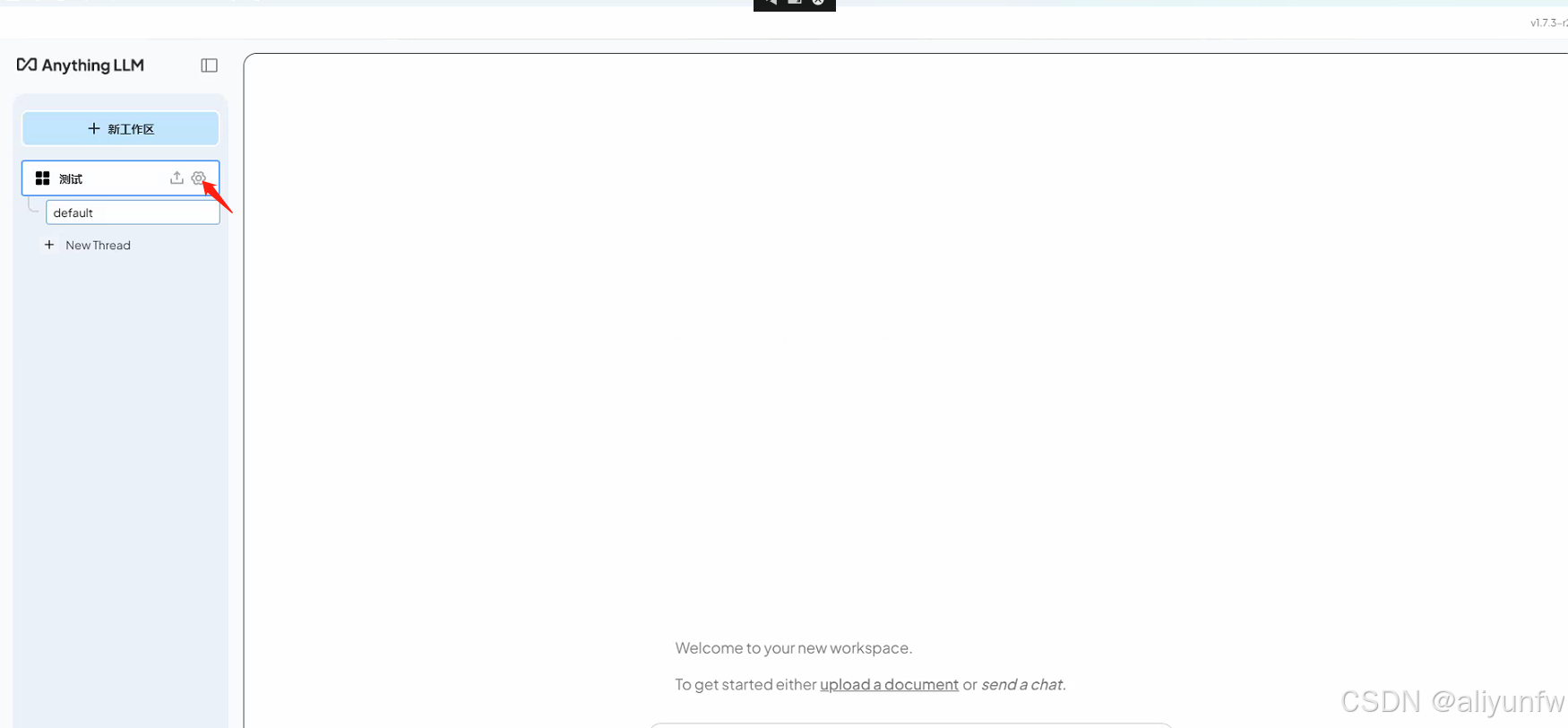
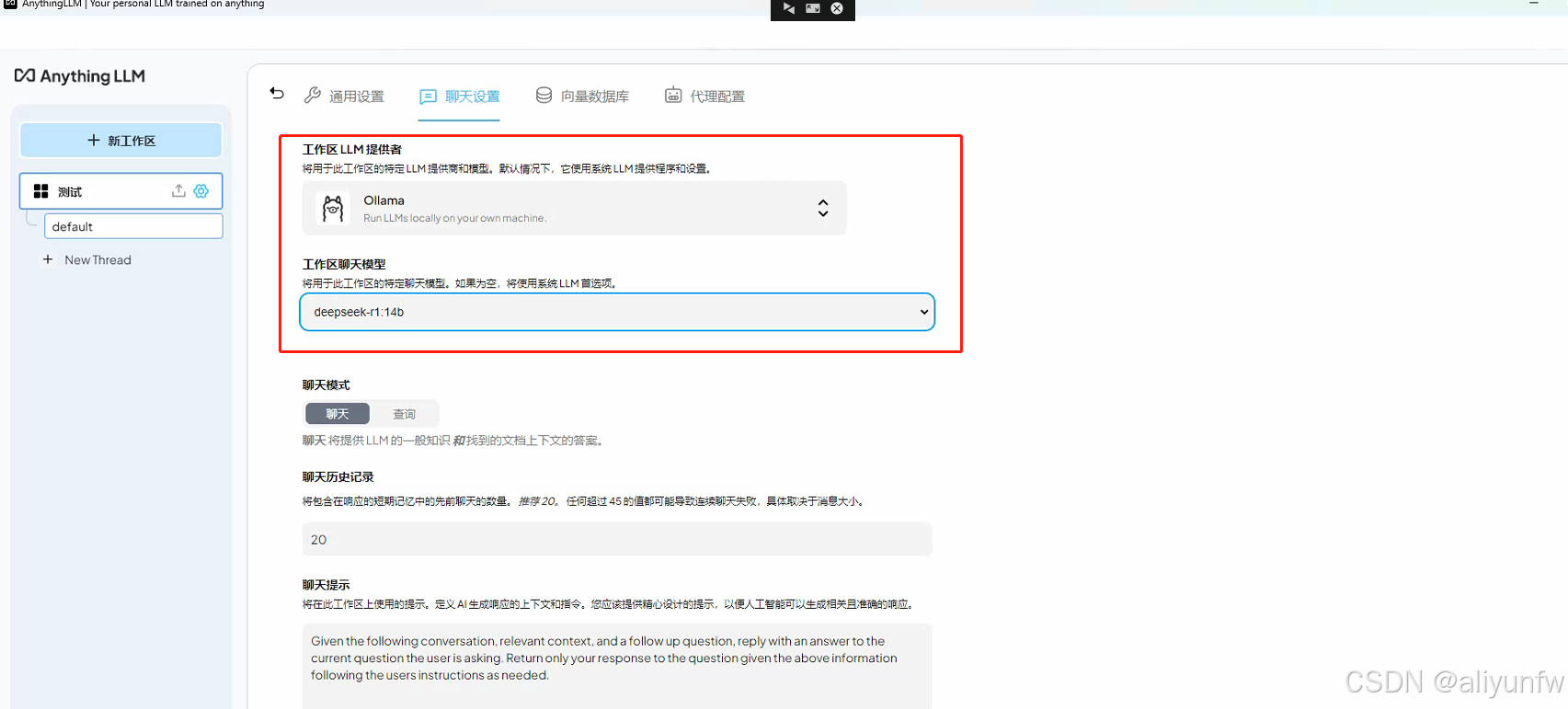
在工作区的设置里面把模型换成我们刚刚下载的deepseek模型
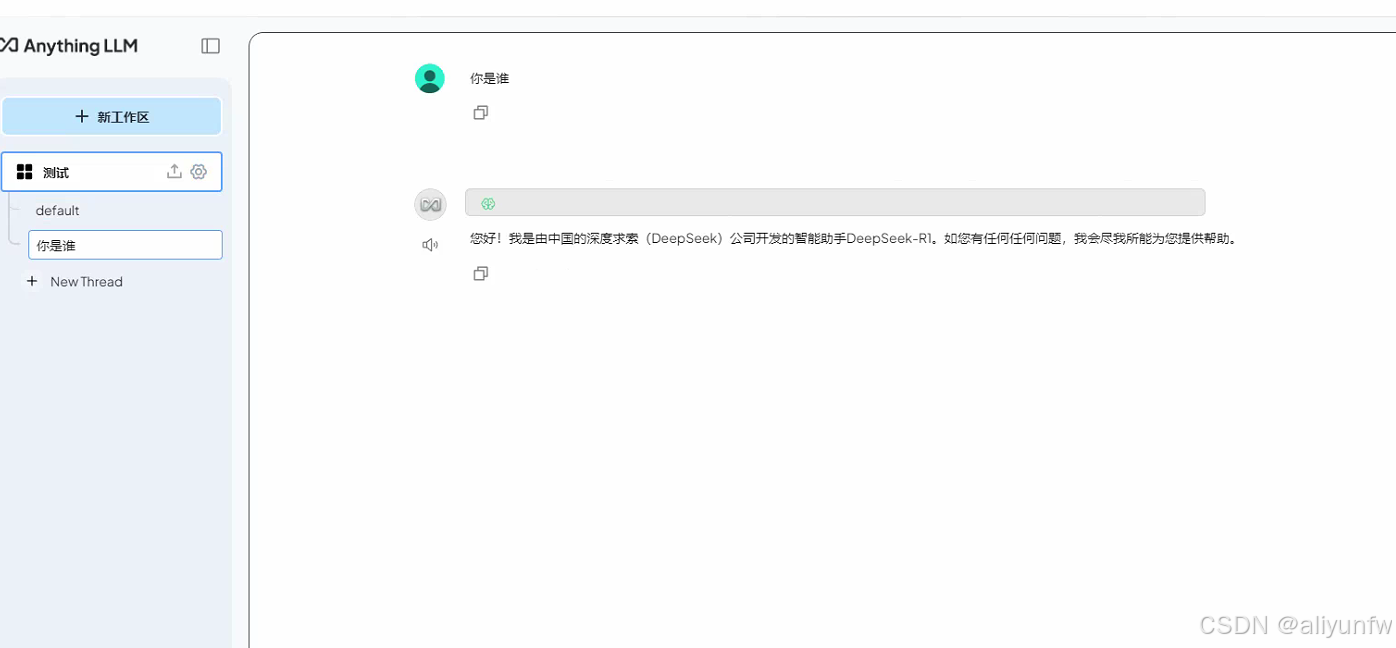
然后我们就可以提问题啦

















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









