



1. 引言
视频配乐(Video-to-Music,V2M)生成的目标是生成与给定视频在语义、时间和节奏上对齐的背景音乐,以增强视听体验、情绪表达与感染力。这涉及以下几个方面:
1)高保真度:确保音乐与人类创作的作品难以区分,这是音乐生成的基本标准;
2)语义对齐:即音乐准确反映视频中的主题、情感和叙事元素;
3)时间同步:强调在生成过程中通过整合语义和时间线索来与时间动态对齐;
然而当前的视频配乐方法存在两个关键不足:1)对视频细节的表征不完整,导致对齐较弱;2)音画两个模态在时间和节奏的对应不足,尤其体现在精确的节拍同步方面。为了克服这些挑战,北大-阿里妈妈人工智能创新联合实验室研究团队提出了VeM(Video echoed in Music),能够为输入视频生成高质量音轨,且在语义、时间和节奏上高度对齐。充分的实验结果验证了该方法的优越性,尤其是在语义相关性和节奏精确性方面。该方法对应的论文被 AAAI 2026接收为Oral,同时也在阿里妈妈智能成片场景进行了实践,欢迎大家关注。
论文题目:Video Echoed in Music: Semantic, Temporal, and Rhythmic Alignment for Video-to-Music Generation
论文链接:https://arxiv.org/pdf/2511.09585
论文主页:https://vem-paper.github.io/VeM-page
2. 方法
为了解决V2M任务面临的挑战,我们提出了VeM,这是一个旨在实现视频的语义、时间和节奏对齐的潜在扩散模型(Latent Diffusion Model)。如图1所示,该方法首次将多层级视频解析结果作为音乐生成的“指挥”,在潜空间扩散模型中融合全局语义、分镜级时间信息及帧级场景转场,通过分镜引导交叉注意力机制(SG-CAtt)精确实现语义与时间双对齐,并结合转场-节拍对齐器与适配器(TB-As)在帧级实现场景切换与节拍事件的精准同步,从而同时满足视频配乐的情绪契合度与节奏精度。
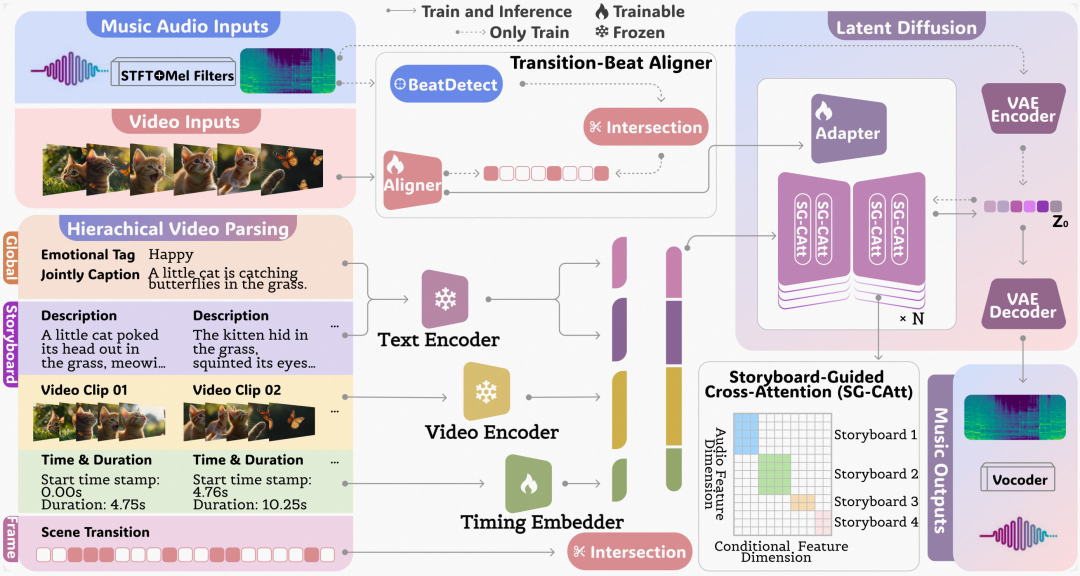
接下来会分小节详细介绍 VeM 框架中的核心模块,包括分层视频解析(Hierarchical Video Parsing)、分镜引导交叉注意力机制(SG-CAtt)、转场-节拍对齐器与适配器(TB-As)以及整个模型的训练推理详细流程。
2.1 分层视频解析
为了使模型对参考的条件视频有全面且深入的理解,我们分析拆解并确定三个关键要素:
1)全局:整体主题、氛围和情感影响;
2)分镜:将视频按照故事线拆解为多个分镜,镜头内的叙事描述、视觉内容、起始绝对时间;
3)帧级:转场发生的精确时间点;
以上元素共同通过分层视频解析模块获得,分层解析在三个层面上操作:全局、故事板和帧。在全局层面,来自视频理解模型(MLLM)[1] 的视频标题和来自音乐分类模型的情感标签提供全局信息。在分镜/故事线层面,视频分镜抽取模块提供局部视觉特征、描述、开始时间戳和持续时间。在帧层面,场景转换检测器[2] 确保了精确的转换点,实现了细粒度的节奏同步。由于视频解析独立于训练过程,我们将其作为一个预处理标注并进行了手动校正和清理。
2.2 分镜引导交叉注意力
虽然交叉注意力机制(Cross Attention)在跨模态对齐条件信号与生成表示方面很有效,但现有的实现在时间建模上存在明显的局限性。为此,我们提出了分镜引导的交叉注意力(SG-CAtt),它有利于更好地保持语义对齐以及时间同步。首先我们将全局特征和故事线分镜特征拼接起来,便于将全局信息融入到每个分镜中:
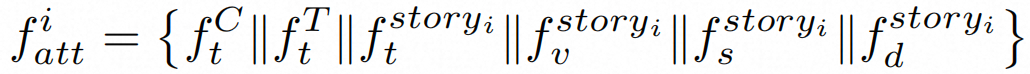
其中对于一个包含多个分镜的视频,如上的条件特征作为交叉注意力中的 Value 和 Key,Query 由扩散模型的潜在表示 提供。时间边界由分镜的开始时间 和结束时间 定义。我们通过引入一个故事线掩码sMask,具体计算方式如下:
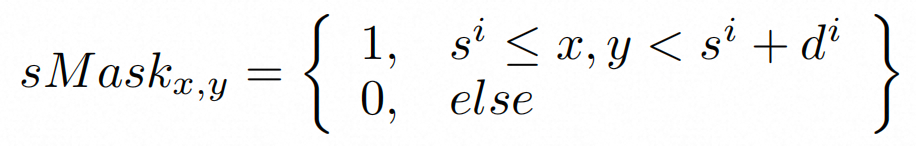
最终,SG-CAtt 具体的注意力计算形式为:
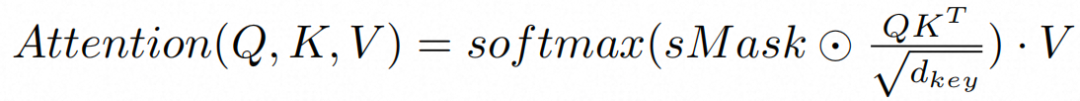
通过拼接全局特征,所有分镜之间的语义一致性得以保持,而掩码交叉注意力则针对单个故事板边界内的局部时间同步。
2.3 转场节拍对齐适配
为了实现精准的节奏一致性,即视觉转场与音乐节拍的同步(卡点),我们首先引入了转场节拍对齐器(Aligner),视频解析提供了帧级的二元序列(其中值为1表示有转场发生,0表示没有)。同时,我们应用基于 RNN 的节拍检测器来生成节拍重音对应的二元序列。它们的交集代表着视觉转换与音乐节拍对齐的时间戳。为了能够从视觉中直接提取出突显对齐帧级的节拍时刻,我们使用如下的 BCE 损失训练一个基于 ResNet-(2+1)D 架构的 Aligner。
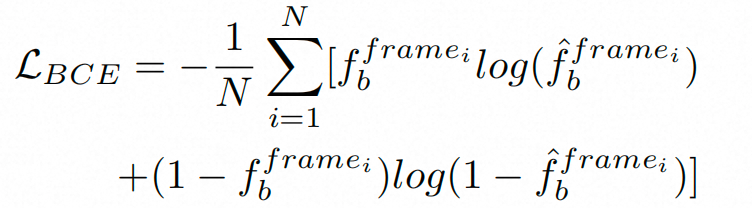
训练后,转场-节拍 Aligner 可以预测给定视频中可能出现节拍重音的合适时刻,我们提取倒数第二层的激活值,然后通过转场节拍适配器(Adapter)注入到扩散主模型。具体地,受到 AdaLN 的启发,我们基于 AdaLN 通过 MLP 将音乐特征归一化为一个缩放因子 和一个偏移因子 ,然后对音乐特征 进行调制,以此来融入节拍信息。
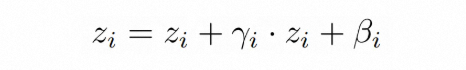
2.4 训练与推理
在训练阶段,我们首先独立地预训练音乐重建 VAE 模型和转场-节拍 Aligner。然后我们冻结这些组件,以及冻结的文本和视频编码器。随后,训练完整的潜在扩散模型,只训练可训练的时间嵌入器,这有助于模型专注于从分层视频表示中获取语义和时间细节。在此阶段不包括转场-节拍模块,以优先进行条件音乐生成。最后,我们将预训练的 Aligner 集成到框架中,并联合优化 Adapter 以细化节奏一致性。
在推理阶段,潜在音乐扩散模型接收随机噪声作为初始的 。分层视频解析处理输入视频,为生成性潜在扩散模型提供由编码器表示的条件信息。转场-节拍 Aligner 预测与转场-节拍事件相关的视觉特征,这些特征通过 Adapter 被并入音乐潜在表示中。
3. 实验与效果展示
3.1 数据集
我们提出了一个全新高质量的视频-音乐配对数据集 TB-Match,包含约18000个样本,源自电商广告和主流视频内容平台。这类视频通常表现出场景转换和音乐节拍之间频繁且高度精确的同步,特别适合用于视频-音乐关系中的时间和节奏对齐。每对样本都经过严格的混合筛选,结合了自动音视频过滤和人工审查,以确保强烈的视频-音乐相关性。此外,我们整合了 M2UGen [5] 数据集,增加了13000个视频-音乐对,总训练数据量约280小时。为了进行普适性研究,我们补充了 SymMV[6]数据集、Sora 生成的无声视频以及其他随机数据。
3.2 定量指标
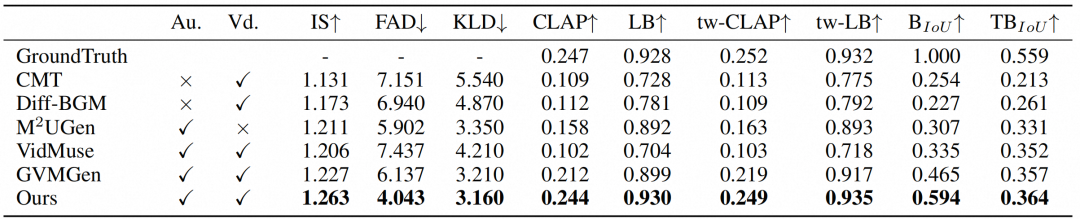
在定量评估对比方面,我们进行了全面的指标测评和主观性评估。如表1所示,我们进行了与五个基线模型在九个量化指标上的对比评估,我们的方法在音乐质量、语义对齐、时间同步和节奏一致性方面持续优于现有方法。VeM 不仅超越了基于音频的方法(GVMGen[4]、VidMuse[7] 和 M2UGen[5]),也超越了基于 MIDI 的方法(CMT [8] 和 Diff-BGM [9])。
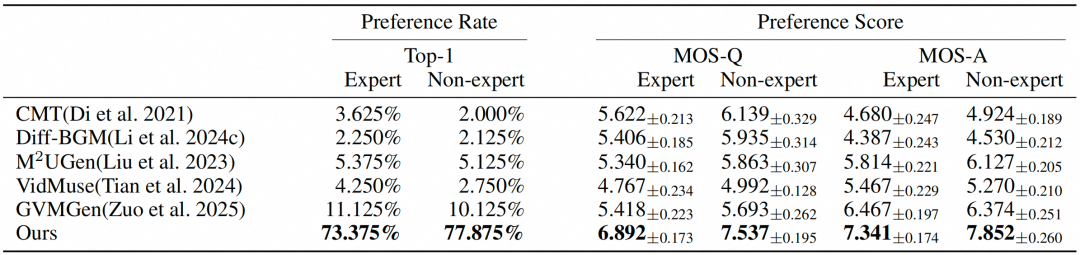
在表2的主观性评估中,也展示出了我们的方法的优越性。具体而言,VeM在专家和非专家参与者中均获得了最高的Top-1偏好率。在平均意见得分方面,MOS-Q和MOS-A分数表明其感知的音乐质量和视频-音乐对齐度更高。在不同背景的评估者中均表现出性能优势,凸显了其有效性。
3.3 效果展示
我们的方法在阿里妈妈智能成片场景上进行了实践和应用,以下前两个视频是电商广告场景的视频配乐效果示例,最后一个是在通用视频场景的效果示例。在效果上也体现了生成音乐的流畅性以及与画面对齐的强烈节奏感。
4. 总结
在本文中,我们提出了 VeM 视频配乐模型,旨在生成与视频在语义、时间、节奏上对齐的高质量音乐。VeM 利用分层视频解析来全面捕捉丰富的细节,分镜引导的交叉注意力促进了语义对齐和时间同步,并通过转场-节拍对齐器与适配器实现了细粒度的节奏精确性。另外,我们提出了全新的视频-音乐数据集,并使用新颖的评估指标结合充分实验展示了其卓越的性能。未来的工作将探索音视频联合生成,不断拓展更多的业务应用场景。
参考文献
[1] S. Bai, K. Chen, X. Liu, J. Wang, et al. 2025. Qwen2.5-VL Technical Report. arXiv preprint arXiv:2502.13923.
[2] B. Castellano. 2024. PySceneDetect. URL https://github.com/Breakthrough/PySceneDetect.
[3] H. Liu, Y. Yuan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y. Wang, W. Wang, Y. Wang, and M. D. Plumbley. 2024. Audioldm 2: Learning holistic audio generation with self-supervised pretraining. IEEE/ACM Transactions on Audio, Speech, and Language Processing.
[4] H. Zuo, W. You, J. Wu, S. Ren, P. Chen, M. Zhou, Y. Lu, and L. Sun. 2025. GVMGen: A General Video-to-Music Generation Model With Hierarchical Attentions. In Proceedings of the AAAI Conference on Artificial Intelligence.
[5] S. Liu, A. S. Hussain, C. Sun, and Y. Shan. 2023. Multi-modal Music Understanding and Generation with the Power of Large Language Models. arXiv preprint arXiv:2311.11255.
[6] L. Zhuo, Z. Wang, B. Wang, Y. Liao, C. Bao, S. Peng, S. Han, A. Zhang, F. Fang, and S. Liu. 2023. Video background music generation: Dataset, method and evaluation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 15637–15647.
[7] Z. Tian, Z. Liu, R. Yuan, J. Pan, Q. Liu, X. Tan, Q. Chen, W. Xue, and Y. Guo. 2024. VidMuse: A simple video-to-music generation framework with long-short-term modeling. arXiv preprint arXiv:2406.04321.
[8] S. Di, Z. Jiang, S. Liu, Z. Wang, L. Zhu, Z. He, H. Liu, and S. Yan. 2021. Video background music generation with controllable music transformer. In Proceedings of the 29th ACM International Conference on Multimedia, 2037–2045.
[9] S. Li, Y. Qin, M. Zheng, X. Jin, and Y. Liu. 2024. Diff-BGM: A Diffusion Model for Video Background Music Generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 27348–27357.
🏷 关于我们
我们是阿里妈妈-智能创作与AI应用团队,专注于图片、视频、文案等各种形式创意的智能制作与投放,产品覆盖阿里妈妈内外多条业务线,欢迎各业务方关注与业务合作。同时,真诚欢迎具备CV、NLP相关背景同学加入!
END

也许你还想看
更真、更像、更美:阿里妈妈重磅升级淘宝星辰视频生成大模型 2.0
懂你,更懂电商:阿里妈妈推出淘宝星辰视频生成大模型及图生视频应用
关注「阿里妈妈技术」,了解更多~

喜欢要“分享”,好看要“点赞”哦ღ~


















 744
744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









