






 本文深入探讨线性回归算法,涵盖最小二乘法与最大似然法原理,解析算法细节如偏置参数作用及最小二乘法几何意义,并讨论模型复杂度与偏差、方差间的关系。
本文深入探讨线性回归算法,涵盖最小二乘法与最大似然法原理,解析算法细节如偏置参数作用及最小二乘法几何意义,并讨论模型复杂度与偏差、方差间的关系。
前言
线性回归算法是公众号介绍的第一个机器学习算法,原理比较简单,相信大部分人对线性回归算法的理解多于其他算法。本文介绍的线性回归算法包括最小二乘法和最大似然法,进而讨论这两种算法蕴含的一些小知识,然后分析算法的偏差和方差问题,最后总结全文。
目录
1、最小二乘法和最大似然法
2、算法若干细节的分析
3、偏差和方差
4、总结
最小二乘法和最大似然函数
最小二乘法


最大似然函数
假设训练数据的目标变量t是由确定性方程y(x,w)和高斯噪声叠加产生的,即:
![]()
其中![]() 是期望为0,精度为β(方差的倒数)的高斯噪声的随机抽样。
是期望为0,精度为β(方差的倒数)的高斯噪声的随机抽样。
目标变量t的分布推导如下:

因此,目标变量t的分布:
![]()
即观测数据集的似然函数:
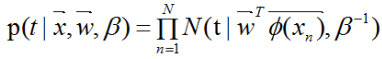
为了书写方便,求最大似然函数对应的参数![]() :
:
似然函数取对数并不影响结果:

因此,对于输入变量x,即可求得输出变量t的期望。
![]()
期望值就是模型的预测输出变量,与最小二乘法的预测结果相同。
算法若干细节的分析
偏置参数w0
线性回归表达式的偏置参数w0有什么意义,我们最小化![]() 来求解w0,根据w0结果来说明其意义。
来求解w0,根据w0结果来说明其意义。
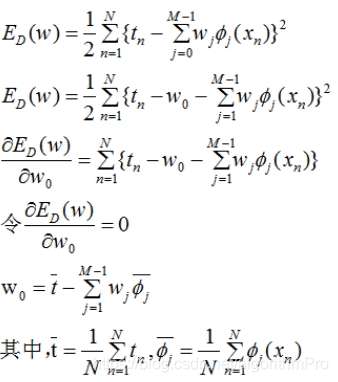
由w0结果可知,偏置参数w0补偿了目标值的平均值(在训练集)与基函数的值的加权求和之间的差。
图形表示为:
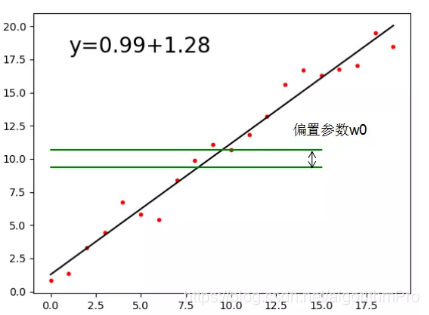
最小二乘法的几何意义
根据最小二乘法的结果可以作如下推导:

图形表示如下:
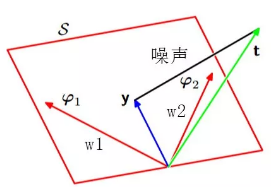
黑色线表示噪声。
备注:推导公式是假设![]() 是非奇异矩阵(
是非奇异矩阵(![]() 的行列式不等于0),若
的行列式不等于0),若![]() 是奇异矩阵,则
是奇异矩阵,则![]() 需要通过奇异值分解(SVD)成新的基向量,后续文章会讲到。
需要通过奇异值分解(SVD)成新的基向量,后续文章会讲到。
噪声模型分析
线性回归模型叠加的噪声是假设均值为0方差为![]() 的高斯分布,下面是笔者分析这一假设的原因。
的高斯分布,下面是笔者分析这一假设的原因。
假设噪声是高斯分布的原因:高斯分布是实际生活中最常见的高斯分布,采用高斯分布的模型更贴近实际情况。
假设噪声是均值为0的原因:这个比较好理解,就是为了方便计算,偏置参数w0包含了噪声均值。
偏差和方差
最小二乘法和最大似然法构建的模型是一样的,本文的线性回归表达式的复杂度用模型参数的个数来表示,模型参数个数越多,则模型复杂度越大;反之模型复杂度越小(只针对无正则化的线性回归方程)。本节讨论模型复杂度与偏差和方差的关系。
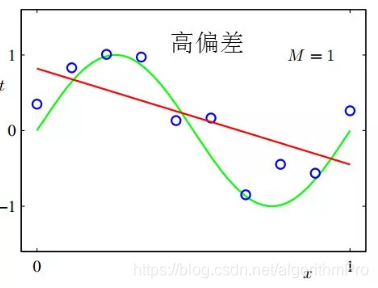
高偏差
若模型参数个数比较少,即模型复杂度很低,模型处于高偏差状态。
如下图用直线去拟合正弦曲线。
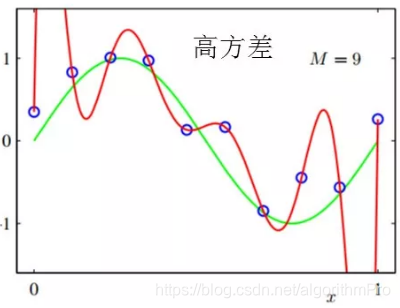
高方差
若模型参数个数较大,即复杂度较高,则模型处于高方差(过拟合)状态。
如下图M=9拟合正弦曲线,模型训练误差为0。
总结
本文介绍了最小二乘法和最大似然法来求线性回归的最优参数,分析了算法中容易忽视的某些细节,由于本文的线性回归表达式没有正则化项,因此模型的复杂度等同于模型参数的个数,参数个数过多模型容易产生高方差(过拟合),参数个数过低模型容易产生高偏差,下节将要介绍贝叶斯线性回归算法,该算法很好的解决了复杂度的问题。
参考:
Christopher M.Bishop <<Pattern Reconition and Machine Learning>>


















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









