




❝本文转自 Ryo's blog,原文:https://fanlv.fun/2022/06/02/golang-pprof-mem/,版权归原作者所有。欢迎投稿,投稿请添加微信好友:cloud-native-yang
背景
朋友的一个服务,某个集群内存的RSS使用率一直在80%左右,他用的是8核16G, 双机房一共206个实例。

但是在pprof里面查的堆内存才使用了6.3G左右,程序里面主要用了6G的LocalCache所以heap用了6.3G是符合预期的。
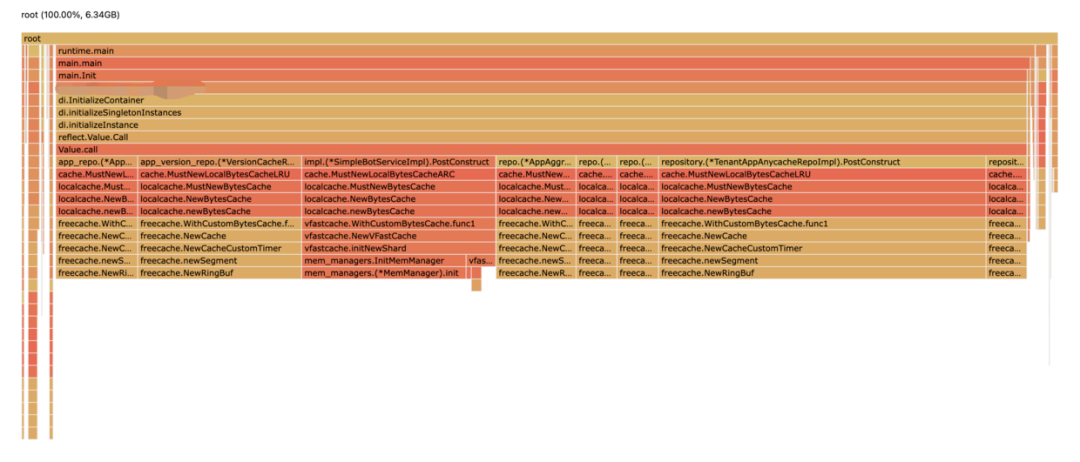
朋友让我帮忙看下,额外的内存到底是被啥占用了。
基础知识
TCMalloc 算法
Thread-Caching Malloc[1] 是Google开发的内存分配算法库,最开始它是作为Google的一个性能工具库perftools的一部分。
TCMalloc是用来替代传统的malloc内存分配函数。它有减少内存碎片,适用于多核,更好的并行性支持等特性。
mmap 函数
mmap它的主要功能是将一个虚拟内存区域与一个磁盘上的文件关联起来,以初始化这个虚拟内存区域的内容,这个过程成为内存映射(memory mapping)。
直白一点说,就是可以将一个文件,映射到一段虚拟内存,写内存的时候操作系统会自动同步内存的内容到文件。内存同步到磁盘,还涉及到一个PageCache的概念,这里不去过度发散,感兴趣朋友可以自己搜下。
文件可以是磁盘上的一个实体文件,比如kafka写日志文件的时候,就用了mmap。
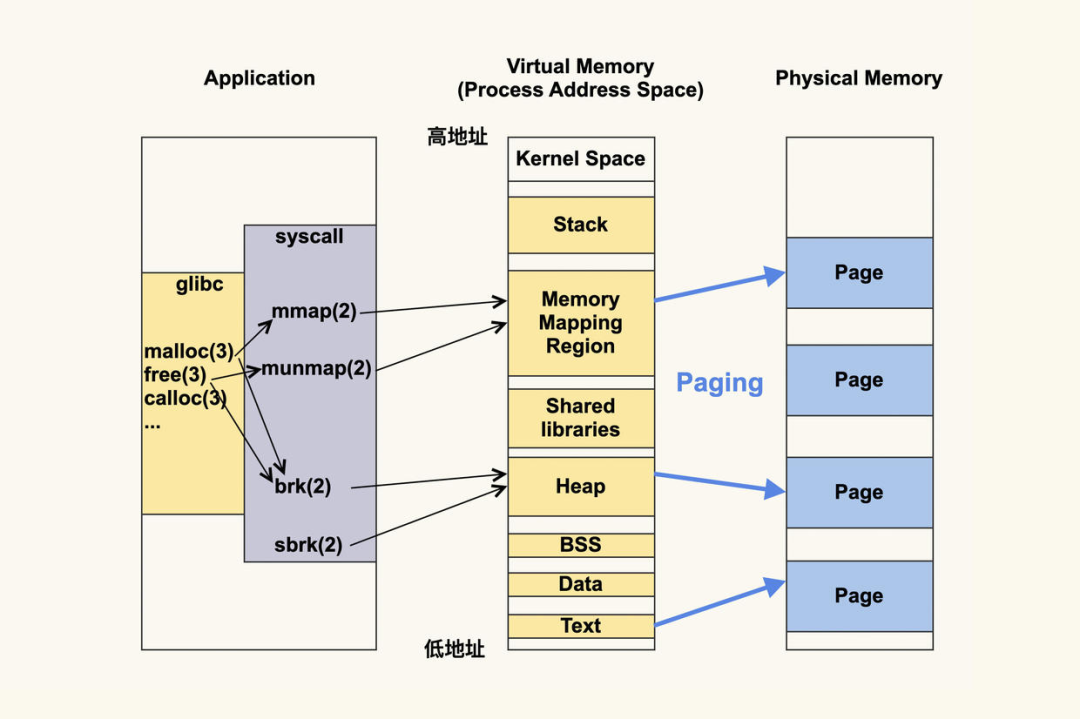
文件也可以是一个匿名文件,这种场景mmap不会去写磁盘,主要用于内存申请的场景。比如调用malloc函数申请内存,当申请的大小超过MMAP_THRESHOLD(默认是128K)大小,内核就会用mmap去申请内存。再比如TCMalloc也是通过mmap来申请一大块内存(匿名文件),然后切割内存,分配给程序使用。
网上很多资料一介绍mmap,就会说到zero copy,就是相对于标准IO来说少了一次内存Copy的开销。让大多数人忽略了mmap本质的功能,认为mmap=zero copy。
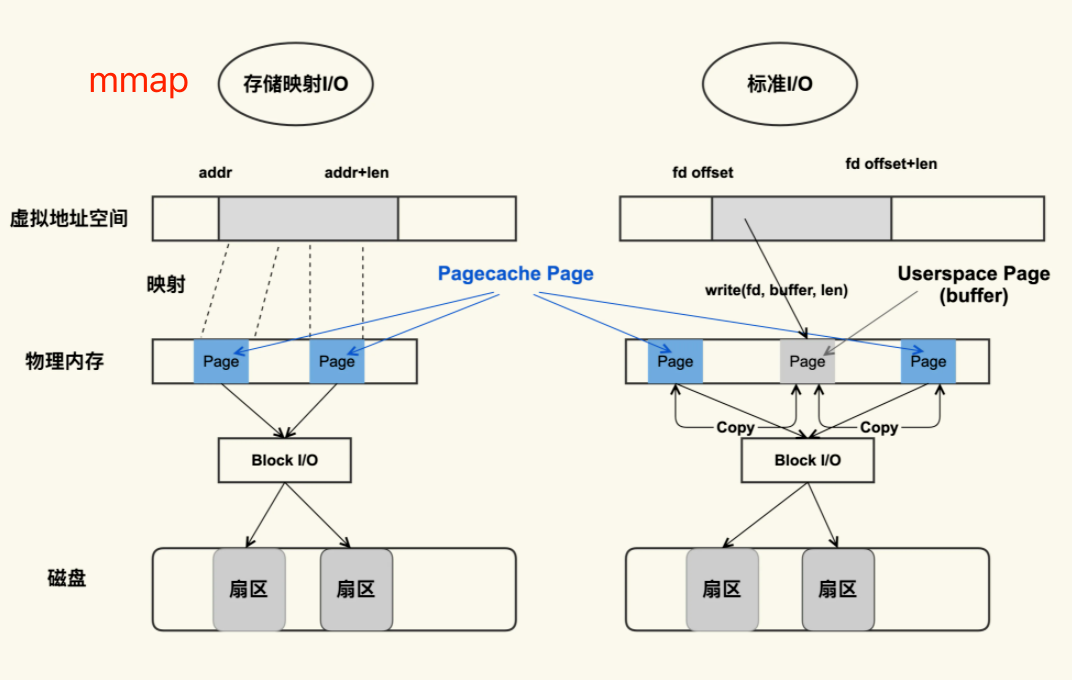
还有一个值得一说的mmap申请的内存不在虚拟地址空间的堆区,在内存映射段(Memory Mapping Region)。
Golang 内存分配
Golang的内存分配[2] 是用的 TCMalloc(Thread-Caching Malloc)算法, 简单点说就是Golang是使用 mmap[3] 函数去操作系统申请一大块内存,然后把内存按照 0~32KB``68个 size 类型的mspan,每个mspan按照它自身的属性 Size Class[4] 的大小分割成若干个object(每个span默认是8K)[5],因为分需要gc的mspan和不需要gc的mspan,所以一共有136种类型。
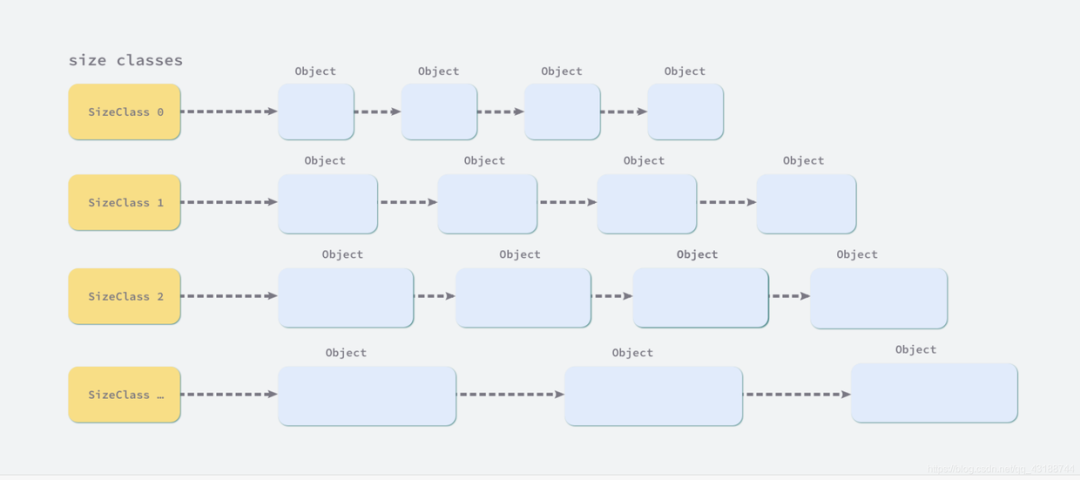
mspan:Go中内存管理的基本单元,是由一片连续的8KB的页组成的大块内存,每个mspan按照它自身的属性Size Class的大小分割成若干个object,mspan的Size Class共有68种(算上0)[6] , numSpanClasses = _NumSizeClasses << 1[7] (因为需要区分需要GC和不需要GC的)
mcache:每个工作线程都会绑定一个mcache,本地缓存可用的mspan资源。
mcentral:为所有 mcache提供切分好的 mspan资源。需要加锁
mheap:代表Go程序持有的所有堆空间,Go程序使用一个mheap的全局对象_mheap[8]来管理堆内存。
Go的内存分配器在分配对象时,根据对象的大小,分成三类:小对象(小于等于16B)、一般对象(大于16B,小于等于32KB)、大对象(大于32KB)。
大体上的分配流程:
>32KB的对象,直接从mheap上分配;(16B,32KB]的对象,首先计算对象的规格大小,然后使用mcache中相应规格大小的mspan分配;<=16B的对象使用mcache的tiny分配器分配;
如果mcache没有相应规格大小的mspan,则向mcentral申请 如果mcentral没有相应规格大小的mspan,则向mheap申请 如果mheap中也没有合适大小的mspan,则向操作系统申请
TCMalloc 的内存浪费
Golang的 sizeclasses.go[9] 源码里面已经给我们已经计算了出每个size的tail waste和max waste比例
// class bytes/obj bytes/span objects tail waste max waste min align
// 1 8 8192 1024 0 87.50% 8
// 2 16 8192 512 0 43.75% 16
// 3 24 8192 341 8 29.24% 8
// 4 32 8192 256 0 21.88% 32
// 5 48 8192 170 32 31.52% 16
// 6 64 8192 128 0 23.44% 64
// 7 80 8192 102 32 19.07% 16
// 8 96 8192 85 32 15.95% 32
// 9 112 8192 73 16 13.56% 16
// 10 128 8192 64 0 11.72% 128
.... 略
// 58 14336 57344 4 0 5.35% 2048
// 59 16384 16384 1 0 12.49% 8192
// 60 18432 73728 4 0 11.11% 2048
// 61 19072 57344 3 128 3.57% 128
// 62 20480 40960 2 0 6.87% 4096
// 63 21760 65536 3 256 6.25% 256
// 64 24576 24576 1 0 11.45% 8192
// 65 27264 81920 3 128 10.00% 128
// 66 28672 57344 2 0 4.91% 4096
// 67 32768 32768 1 0 12.50% 8192我们看下tail waste和max waste的计算方式,源码如下[10]:
spanSize := c.npages * pageSize
objects := spanSize / c.size
tailWaste := spanSize - c.size*(spanSize/c.size)
maxWaste := float64((c.size-prevSize-1)*objects+tailWaste) / float64(spanSize)
alignBits := bits.TrailingZeros(uint(c.size))
if alignBits > pageShift {
// object alignment is capped at page alignment
alignBits = pageShift
}
for i := range minAligns {
if i > alignBits {
minAligns[i] = 0
} else if minAligns[i] == 0 {
minAligns[i] = c.size
}
}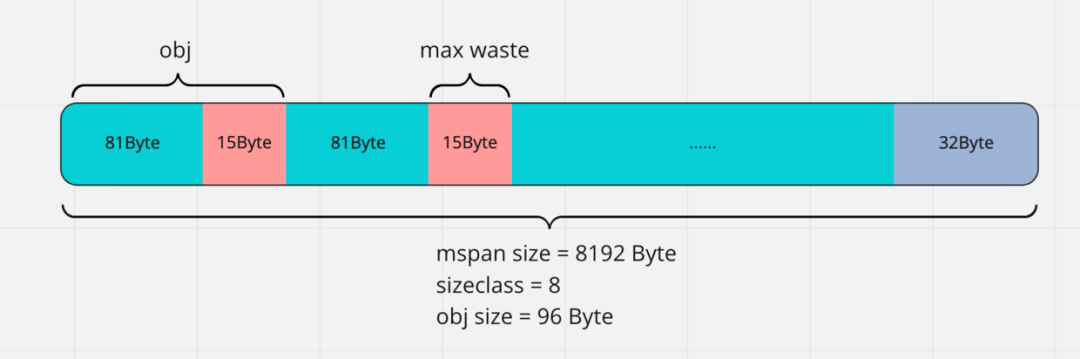
sizeclase=8的时候obj= 96,所以tailWaste = 8192%96 = 32,maxWaste = ((96-80-1)* 85 + 32)/ 8192 = 0.1595。
Go 查看内存使用情况几种方式
1️⃣ 执行前添加系统环境变量GODEBUG='gctrace=1'来跟踪打印垃圾回收器信息,具体打印的内容含义可以参考官方文档[11]。
gctrace: 设置gctrace=1会使得垃圾回收器在每次回收时汇总所回收内存的大小以及耗时,
并将这些内容汇总成单行内容打印到标准错误输出中。
这个单行内容的格式以后可能会发生变化。
目前它的格式:
gc ## @#s #%: #+#+## ms clock, #+#/#/#+## ms cpu, #->#->## MB, ## MB goal, ## P
各字段的含义:
gc ## GC次数的编号,每次GC时递增
@#s 距离程序开始执行时的时间
#% GC占用的执行时间百分比
#+...+## GC使用的时间
#->#->## MB GC开始,结束,以及当前活跃堆内存的大小,单位M
## MB goal 全局堆内存大小
## P 使用processor的数量
如果信息以"(forced)"结尾,那么这次GC是被runtime.GC()调用所触发。
如果gctrace设置了任何大于0的值,还会在垃圾回收器将内存归还给系统时打印一条汇总信息。
这个将内存归还给系统的操作叫做scavenging。
这个汇总信息的格式以后可能会发生变化。
目前它的格式:
scvg#: ## MB released printed only if non-zero
scvg#: inuse: ## idle: ## sys: ## released: ## consumed: ## (MB)
各字段的含义:
scvg## scavenge次数的变化,每次scavenge时递增
inuse: ## MB 垃圾回收器中使用的大小
idle: ## MB 垃圾回收器中空闲等待归还的大小
sys: ## MB 垃圾回收器中系统映射内存的大小
released: ## MB 归还给系统的大小
consumed: ## MB 从系统申请的大小2️⃣ 代码中使用runtime.ReadMemStats来获取程序当前内存的使用情况
var m runtime.MemStats
runtime.ReadMemStats(&m)3️⃣ 通过pprof获取
http://127.0.0.1:10000/debug/pprof/heap?debug=1
在输出的最下面有MemStats的信息
## runtime.MemStats
## Alloc = 105465520
## TotalAlloc = 334874848
## Sys = 351958088
## Lookups = 0
## Mallocs = 199954
## Frees = 197005
## HeapAlloc = 105465520
## HeapSys = 334954496
## HeapIdle = 228737024
## HeapInuse = 106217472
## HeapReleased = 218243072
## HeapObjects = 2949
## Stack = 589824 / 589824
## MSpan = 111656 / 212992
## MCache = 9600 / 16384
## BuckHashSys = 1447688
## GCSys = 13504096
## OtherSys = 1232608
## NextGC = 210258400
## LastGC = 1653972448553983197Sysmon 监控线程
Go Runtime在启动程序的时候,会创建一个独立的M作为监控线程,称为sysmon,它是一个系统级的daemon线程。这个sysmon独立于GPM之外,也就是说不需要P就可以运行,因此官方工具go tool trace是无法追踪分析到此线程。
sysmon执行一个无限循环,一开始每次循环休眠20us,之后(1ms后)每次休眠时间倍增,最终每一轮都会休眠 10ms。
sysmon主要如下几件事
释放闲置超过
5分钟的span物理内存,scavenging。(Go 1.12之前)如果超过两分钟没有执行垃圾回收,则强制执行
GC。将长时间未处理的
netpoll结果添加到任务队列向长时间运行的
g进行抢占收回因为
syscall而长时间阻塞的p
问题排查过程
内存泄露?
服务内存不正常,本能反应是不是内存泄露了?朋友说他们服务内存一周内一直都是在80%~85%左右波动,然后pprof看的heap的使用也是符合预期的。看了下程序的Runtime监控,容器的内存监控,都是正常的。基本可以排除内存泄露的可能性。
madvise
排除了内存泄露的可能性,再一个让人容易想到的坑就是madvise,这个感觉是GO 1.12 ~ Go 1.15 版本,被提到很多次的问题。
什么是 madvise ?
madvise()[12] 函数建议内核,在从addr指定的地址开始,长度等于len参数值的范围内,该区域的用户虚拟内存应遵循特定的使用模式。内核使用这些信息优化与指定范围关联的资源的处理和维护过程。如果使用madvise()[13]函数的程序明确了解其内存访问模式,则使用此函数可以提高系统性能。”
MADV_FREE:(Linux 4.5以后开始支持这个特性),内核在当出现内存压力时才会主动释放这块内存。MADV_DONTNEED:预计未来长时间不会被访问,可以认为应用程序完成了对这部分内容的访问,因此内核可以立即释放与之相关的资源。
Go Runtime 对 madvise 的使用
在Go 1.12版本的时候,为了提高内存的使用效率,把madvise的参数从MADV_DONTNEED改成MADV_FREE,具体可以看这个CR[14],然后又加个debug参数来可以控制分配规则改回为MADV_DONTNEED,具体可以看这个CR[15]
runtime中调用madvise的代码如下[16]:
var adviseUnused = uint32(_MADV_FREE)
func sysUnused(v unsafe.Pointer, n uintptr) {
// ... 略
var advise uint32
if debug.madvdontneed != 0 {
advise = _MADV_DONTNEED
} else {
advise = atomic.Load(&adviseUnused)
}
if errno := madvise(v, n, int32(advise)); advise == _MADV_FREE && errno != 0 {
// MADV_FREE was added in Linux 4.5. Fall back to MADV_DONTNEED if it is
// not supported.
atomic.Store(&adviseUnused, _MADV_DONTNEED)
madvise(v, n, _MADV_DONTNEED)
}
}使用MADV_FREE的问题是,Golang程序释放的内存,操作系统并不会立即回收,只有操作系统内存紧张的时候,才会主动去回收,而我们的程序,都是跑在容器中的,所以造成了,我们容器内存使用快满了,但是物理机的内存还有很多内存,导致的现象就是用pprof看的内存不一样跟看的RES相差巨大。
由于MADV_FREE导致的pprof和top内存监控不一致的问题,导致很多开发者在GO的GitHub上提issue,最后Austin Clements(Go开源大佬)拍板,把MADV_FREE改回了MADV_DONTNEED,具体可以看这个CR[17]
大佬也在代码里面做了个简单解释如下:
// On Linux, MADV_FREE is faster than MADV_DONTNEED,
// but doesn't affect many of the statistics that
// MADV_DONTNEED does until the memory is actually
// reclaimed. This generally leads to poor user
// experience, like confusing stats in top and other
// monitoring tools; and bad integration with
// management systems that respond to memory usage.
// Hence, default to MADV_DONTNEED.该改动已经在 Go 1.16[18] 合入了。我看了下朋友服务的GO版本是1.17,所以是MADV_FREE的问题基本也可以排除了。
memory scavenging
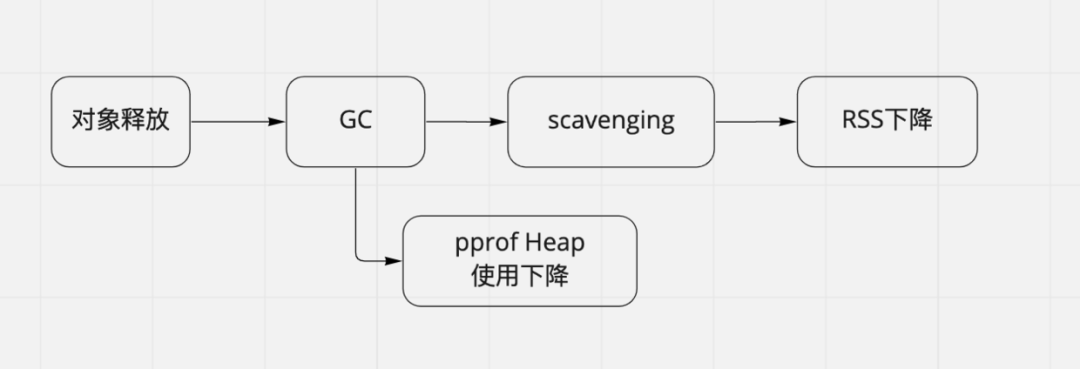
既然排除了内存泄露,然后也不是madvise()的问题,只能猜想是不是内存是不是还没有归还给操作系统。
Go把内存归还给系统的操作叫做scavenging。在Go程序执行过程中,当对象释放的时候,对象占用的内存并没有立即返还给操作系统(为了提高内存分配效率,方式归还以后又理解需要申请),而是需要等待GC(定时或者条件触发)和scavenging(定时或者条件触发)才会把空闲的内存归还给操作系统。
当然我们也可以在代码里面调用debug.FreeOSMemory()来主动释放内存。debug.FreeOSMemory()的功能是强制进行垃圾收集,然后尝试将尽可能多的内存返回给操作系统。具体代码实现如下[19]:
//go:linkname runtime_debug_freeOSMemory runtime/debug.freeOSMemory
func runtime_debug_freeOSMemory() {
GC() // 第一步强制 GC
systemstack(func() { mheap_.scavengeAll() }) // 第二步 scavenging
}GC 触发机制
GO的GC触发可以分为主动触发和被动触发,主动触发就是在代码里面主动执行runtime.GC(),线上环境我们一般很少主动触发。这里我们主要讲下被动触发,被动触发有两种情况:
1️⃣ 当前内存分配达到一定比例则触发,可以通过环境变量GOGC或者代码中调用runtime.SetGCPercent来设置,默认是100,表示内存增长1倍触发一次GC。比如一次回收完毕后,内存的使用量为5M,那么下次回收的时机则是内存分配达到10M的时候。
2️⃣ 定时触发GC,这个是sysmon线程里面干的时区,一般是2分钟(runtime中写死的)内没有触发GC,会强制执行一次GC。具体代码如下[20]:
// forcegcperiod is the maximum time in nanoseconds between garbage
// collections. If we go this long without a garbage collection, one
// is forced to run.
//
// This is a variable for testing purposes. It normally doesn't change.
var forcegcperiod int64 = 2 * 60 * 1e9// gcTriggerTime indicates that a cycle should be started when
// it's been more than forcegcperiod nanoseconds since the
// previous GC cycle.
gcTriggerTime
// check if we need to force a GC
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 {
lock(&forcegc.lock)
forcegc.idle = 0
var list gList
list.push(forcegc.g)
injectglist(&list)
unlock(&forcegc.lock)
}scavenging 触发机制
GO 1.12之前是通过定时触发,2.5min会执行一次scavenge,然后会回收超过5分钟内没有使用过的mspan,具体源码如下[21]:
// If a heap span goes unused for 5 minutes after a garbage collection,
// we hand it back to the operating system.
scavengelimit := int64(5 * 60 * 1e9)
// scavenge heap once in a while
if lastscavenge+scavengelimit/2 < now {
mheap_.scavenge(int32(nscavenge), uint64(now), uint64(scavengelimit))
lastscavenge = now
nscavenge++
}这样会有个问题是,如果不停的有大量内存申请和释放,会导致mspan内存一直不会释放给操作系统(因为不停被使用然后释放),导致堆内存监控和RSS监控不一致。具体可以看 runtime: reclaim memory used by huge array that is no longer referenced[22] 这个Issue,还有一个问题因为内存释放不及时,容易在低内存的设备上OOM,具体可以看 Running Go on Low Memory Devices [23] 这个文章。
基于以上这些问题,Austin Clements大佬提交了一个Issue:runtime: make the scavenger more prompt[24],Austin Clements提出如果我们只考虑在scavenge阶段需要释放多少个mspan,这个是比较难的。我们应该分离关注点,通过关注释放和重新获得内存的成本,下次GC的堆大小,我们愿意承担的CPU和内存开销来计算出应该释放多少mspan,提议保留的内存大小应该是过去一段时间内,堆内存回收大小的峰值乘以一个常数,计算回收方式如下:
retain = C * max(current heap goal, max({heap goals of GCs over the past T seconds}))
C = 1 + ε = 1.1
T = 10 seconds这个提议2016.08.31提出以后,但是一直没有人去实现。
直到2019.02.21的时候Michael Knyszek重新提了一个Proposal:runtime: smarter scavenging[25]。
这个Proposal目标是:
降低
Go应用程序的RSS平均值和峰值。使用尽可能少
CPU来持续降低RSS。
runtime做内存回收策略,有三个关键问题
内存回收的速率是多少?
我们应该保留多少内存?
什么内存我们应该归还给操作系统?
实现方法
Scavenge速度应该与程序Alloc内存的速度保持一致。保留的内存大小应该是一个常量乘以过去
N次GC的峰值。runtime: make the scavenger more prompt[26]在
unscavenged spans中,优先清除基地址高的。
上面的Proposal主要提交如下:
runtime: add background scavenger[27]
runtime: remove periodic scavenging[28]
结论
上面,我们知道了pprof抓的堆内存的大小和RSS不一致,有几种可能:
是程序申请的内存还没有被
GC。内存虽然被
GO执行了GC,但是可能并没有归还给操作系统(scavenging)。
为了验证一下上面的结论,我上机器抓了下heap的统计:
nx-x-x(lark.arch.dts@stock:prod):dts## curl http://ip:port/debug/pprof/heap?debug=1 | grep Heap
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0## 0xa47ba9 runtime/pprof.writeHeapInternal+0xc9 /usr/local/go/src/runtime/pprof/pprof.go:566
## 0xa47a46 runtime/pprof.writeHeap+0x26 /usr/local/go/src/runtime/pprof/pprof.go:536
100 913M 0 913M 0 0 86.8M 0 --:--:-- 0:00:10 --:--:-- 90.6M## 0xa47ba9 runtime/pprof.writeHeapInternal+0xc9 /usr/local/go/src/runtime/pprof/pprof.go:566
## 0xa47a46 runtime/pprof.writeHeap+0x26 /usr/local/go/src/runtime/pprof/pprof.go:536
## HeapAlloc = 11406775960
## HeapSys = 13709377536
## HeapIdle = 2032746496
## HeapInuse = 11676631040
## HeapReleased = 167829504
## HeapObjects = 49932438这里我主要关注几个参数:
HeapInuse[29]: 堆上使用中的mspan大小。
HeapReleased[30]:归还了多少内存给操作系统。
HeapIdle[31]:空闲的mspan大小。HeapIdle - HeapReleased 等于runtime持有了多少个空闲的mspan,这部分还没有释放给操作系统,在pprof的heap火焰图里面是看不到这部分内存的。
stats.HeapIdle = gcController.heapFree.load() + gcController.heapReleased.load()上面我们获取机器的内存信息如下
HeapInuse = 11676631040 ≈ 10.88G // 堆上使用内存的大小
HeapIdle - HeapReleased = 2032746496 - 167829504 ≈ 1.73G // 可以归还但是没有归还的内存两个加起来,也差不多12~13G左右,所以容器的内存使用率是80%也是符合预期的。
还有个问题,为什么我们程序的localcache大小设置的只有了6G,实际heap使用了10.88G,因为HeapInuse除了程序真正使用的内存,还包括:
程序释放的内存,但是还没有被
GC。这部分内存还是算在HeapInuse中(这个应该是大头)。上面说的
mspan的max waste和tail waste这部分也在HeapInuse(这个应该很少)。假设一个
8k的mspan上只使用了一个大小为8Byte的obj,这个在HeapInuse会算8K。
总结
golang堆内存大小不一定跟RSS一致,它跟GC、scavenging时机有关。如果有大量lcoalcache申请释放,很可能导致RSS远远大于heap使用的大小。
引用链接
[1]
Thread-Caching Malloc: http://goog-perftools.sourceforge.net/doc/tcmalloc.html
[2]Golang的内存分配: https://github.com/golang/go/blob/master/src/runtime/malloc.go
[3]mmap: https://github.com/golang/go/blob/master/src/runtime/mem_linux.go#L185
[4]Size Class: https://github.com/golang/go/blob/master/src/runtime/sizeclasses.go#L93
[5](每个span默认是8K): https://github.com/golang/go/blob/go1.16.6/src/runtime/sizeclasses.go
[6]68种(算上0): https://github.com/golang/go/blob/master/src/runtime/sizeclasses.go#L89
[7]numSpanClasses = _NumSizeClasses << 1: https://github.com/golang/go/blob/master/src/runtime/mheap.go#L528
[8]_mheap: https://github.com/golang/go/blob/master/src/runtime/mheap.go#L216
[9]sizeclasses.go: https://github.com/golang/go/blob/master/src/runtime/sizeclasses.go#L6
[10]源码如下: https://github.com/golang/go/blob/master/src/runtime/mksizeclasses.go#L238
[11]官方文档: https://pkg.go.dev/runtime
[12]madvise(): https://man7.org/linux/man-pages/man2/madvise.2.html
[13]madvise(): https://man7.org/linux/man-pages/man2/madvise.2.html
[14]具体可以看这个CR: https://go-review.googlesource.com/c/go/+/135395/
[15]具体可以看这个CR: https://go-review.googlesource.com/c/go/+/155931/
[16]代码如下: https://github.com/golang/go/blob/master/src/runtime/mem_linux.go#L106
[17]具体可以看这个CR: https://go-review.googlesource.com/c/go/+/267100
[18]Go 1.16: https://go.dev/doc/go1.16
[19]具体代码实现如下: https://github.com/golang/go/blob/master/src/runtime/mheap.go#L1573
[20]具体代码如下: https://github.com/golang/go/blob/master/src/runtime/proc.go#L5250
[21]具体源码如下: https://github.com/golang/go/blob/release-branch.go1.12/src/runtime/proc.go#L4357
[22]runtime: reclaim memory used by huge array that is no longer referenced: https://github.com/golang/go/issues/14045
[23]Running Go on Low Memory Devices : https://medium.com/samsara-engineering/running-go-on-low-memory-devices-536e1ca2fe8f
[24]runtime: make the scavenger more prompt: https://github.com/golang/go/issues/16930
[25]runtime: smarter scavenging: https://github.com/golang/go/issues/30333
[26]runtime: make the scavenger more prompt: https://github.com/golang/go/issues/16930
[27]runtime: add background scavenger: https://go-review.googlesource.com/c/go/+/142960/
[28]runtime: remove periodic scavenging: https://go-review.googlesource.com/c/go/+/143157/
[29]HeapInuse: https://github.com/golang/go/blob/master/src/runtime/mstats.go#L160
[30]HeapReleased: https://github.com/golang/go/blob/master/src/runtime/mstats.go#L173
[31]HeapIdle: https://github.com/golang/go/blob/master/src/runtime/mstats.go#L145


你可能还喜欢
点击下方图片即可阅读
如何优雅的让 Pod 通过 ServiceAccount 访问 K8s api-server



云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?


















 2792
2792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









