




《Prompt报告:Prompt技术的系统综述》
The Prompt Report: A Systematic Survey of Prompting Techniques The Prompt Report
The Prompt Report- A Systematic Survey of Prompting Techniques
原文下载地址: https://download.youkuaiyun.com/download/ajian005/90168011
随着生成人工智能(GenAI)系统在工业和研究设置中的日益部署,开发人员和最终用户可以通过使用提示或提示工程与这些系统互动。
尽管提示是一个广泛研究且使用频繁的概念,但由于在该领域的新颖性,存在关于提示构成的冲突术语和糟糕的本体论理解。本文通过建立提示技术的分类,分析其使用,建立了关于提示的结构化理解。
论文呈现了33个词汇术语的全面词汇表,58种仅文本提示技术的分类,以及40种其他模态的技术。进一步对自然语言前缀提示的整个文献进行了元分析。
在本文中,我们对所有生成式人工智能(GenAI)提示技术(仅限前缀)的文献进行了系统性回顾。
我们结合人工和机器的努力,处理了来自arXiv、Semantic Scholar和ACL的4,797篇记录,并通过PRISMA回顾流程提取了1,565篇相关论文。从这一数据集中,我们展示了58种基于文本的Prompt Techniques,并补充了大量的多模态和多语言技术。我们的目标是提供一个易于理解和实施的Prompt Techniques完整目录。我们还回顾了代理(Agent)作为提示(Prompt)的扩展,包括输出评估方法和设计有助于安全性和保障的提示方法。最后,我们将提示技术应用于两个案例研究。
摘要
生成式人工智能(GenAI)系统正日益广泛地应用于各行各业和研究领域。开发人员和最终用户通过提示或提示工程与这些系统进行交互。尽管提示是一个广泛应用且研究深入的概念,但由于这一领域的较新性,存在着术语上的冲突和对提示本质的本体论理解不足。本文通过建立提示的结构化理解,提出了提示技术的分类法并分析其应用。我们提供了一个全面的词汇表,包含33个术语,一个包含58种仅文本提示技术的分类法,以及40种适用于其他模态的技术。此外,我们还对关于自然语言前缀提示的所有文献进行了元分析。
1 介绍(Introduction)
Transformer-based LLMs are widely deployed in consumer-facing, internal, and research settings (Bommasani et al., 2021). Typically, these models rely on the user providing an input “prompt” to which the model produces an output in response. Such prompts may be textual—“Write a poem about trees.”—or take other forms: images, audio, videos, or a combination thereof. The ability to prompt models, particularly prompting with natu- ral language, makes them easy to interact with and use flexibly across a wide range of use cases.
基于Transformer的大型语言模型(LLMs)广泛应用于面向消费者、内部和研究环境中(Bommasani等,2021)。通常,这些模型依赖于用户提供一个输入“提示”,模型根据该提示生成输出。这些提示可能是文本形式的——例如:“写一首关于树的诗。”——也可以采用其他形式:图像、音频、视频或它们的组合。能够对模型进行提示,特别是使用自然语言进行提示,使得这些模型易于交互,并且能够在广泛的应用场景中灵活使用。
Knowing how to effectively structure, evaluate, and perform other tasks with prompts is essential to using these models. Empirically, better prompts lead to improved results across a wide range of tasks (Wei et al., 2022; Liu et al., 2023b; Schul- hoff, 2022). A large body of literature has grown around the use of prompting to improve results and the number of prompting techniques is rapidly increasing.
了解如何有效地构造、评估以及使用提示(prompts)执行其他任务,对于使用这些模型(models)至关重要。经验上,较好的提示能够在广泛的任务中提高结果(Wei等,2022;Liu等,2023b;Schulhoff,2022)。围绕提示使用以改善结果的研究文献已大量增加,且提示技术的数量也在迅速增长。
However, as prompting is an emerging field, the use of prompts continues to be poorly understood, with only a fraction of existing terminologies and techniques being well-known among practitioners. We perform a large-scale review of prompting tech- niques to create a robust resource of terminology and techniques in the field. We expect this to be the first iteration of terminologies that will develop over time.
然而,由于提示技术仍然是一个新兴领域,提示的使用仍然不被充分理解,现有术语和技术中只有一小部分在实践者中广为人知。我们进行了一次大规模的提示技术回顾,旨在创建该领域术语和技术的一个稳固资源。我们期望这将是术语发展的第一版,未来随着时间的推移会不断完善。
Scope of Study We create a broad directory of prompting techniques, which can be quickly un- derstood and easily implemented for rapid experi- mentation by developers and researchers. To this end, we limit our study to focus on discrete pre- fix prompts (Shin et al., 2020a) rather than cloze prompts (Petroni et al., 2019; Cui et al., 2021), because modern LLM architectures (especially decoder-only models), which use prefix prompts, are widely used and have robust support for both consumers and researchers. Additionally, we re- fined our focus to hard (discrete) prompts rather than soft (continuous) prompts and leave out papers that make use of techniques using gradient-based updates (i.e. fine-tuning). Finally, we only study task-agnostic techniques. These decisions keep the work approachable to less technical readers and maintain a manageable scope.
研究范围 我们创建了一个广泛的提示技术目录,旨在让开发人员和研究人员能够快速理解并轻松实施,以便进行快速实验。为此,我们将研究范围限制在离散的前缀提示(Shin等,2020a)上,而不是填空提示(Cloze提示)(Petroni等,2019;Cui等,2021),因为现代的大型语言模型架构(特别是仅解码器模型)广泛使用前缀提示,并且对于消费者和研究人员都有强大的支持。此外,我们将焦点集中在硬(离散)提示上,而非软(连续)提示,并排除了使用基于梯度更新的技术(如微调)的论文。最后,我们只研究任务无关的提示技术。这些决策使得本研究对技术水平较低的读者更具可接近性,并且保持了一个可管理的研究范围。
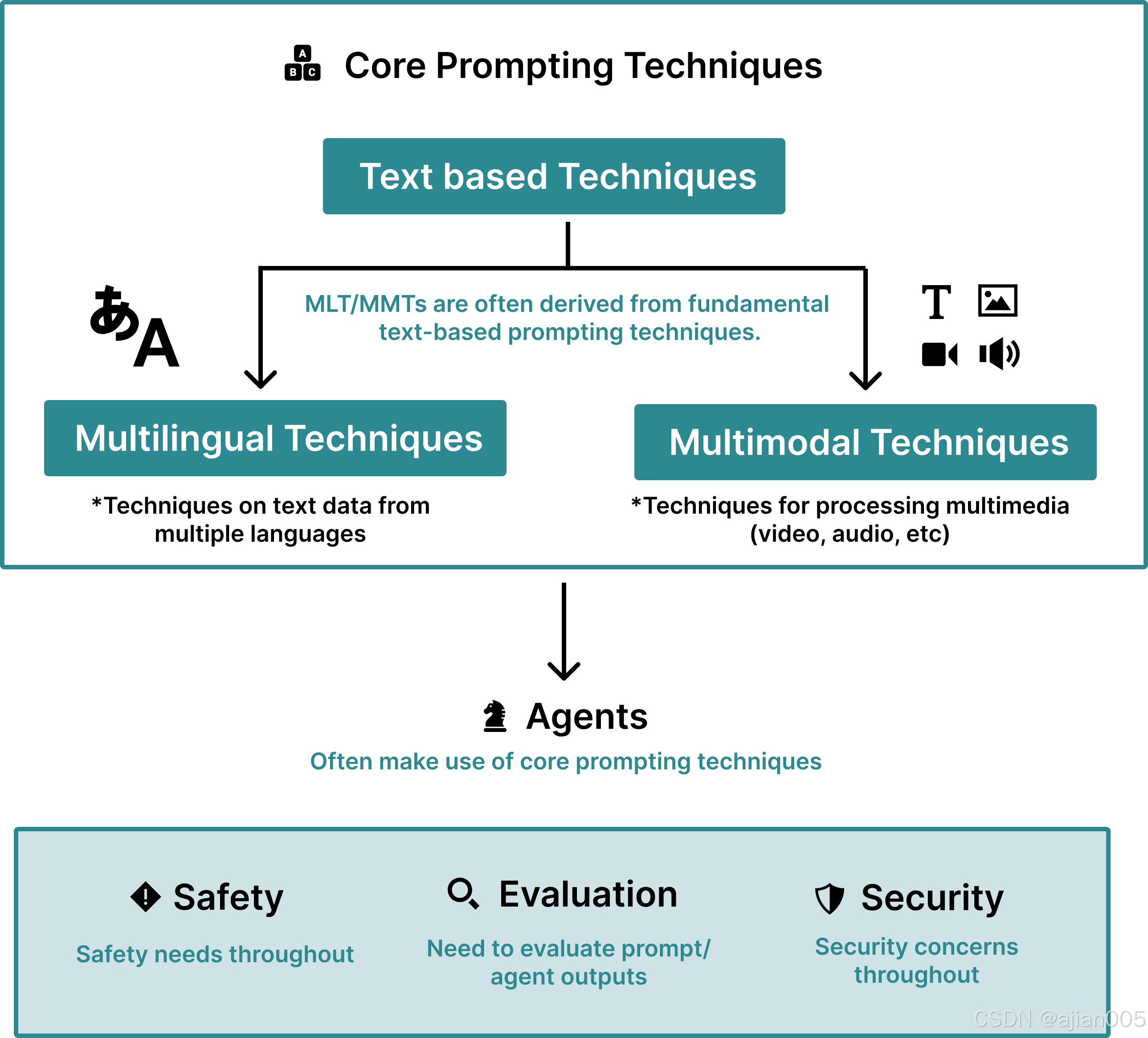
Sections Overview We conducted a machine- assisted systematic review grounded in the PRISMA process (Page et al., 2021) (Section 2.1) to identify 58 different text-based prompting tech- niques, from which we create a taxonomy with a robust terminology of prompting terms (Section 1.2).
章节概述 我们进行了一项基于PRISMA流程(Page等人,2021)的机器辅助系统性综述(第2.1节),以识别58种不同的基于文本的提示技术,并由此创建了一个包含健全的提示术语的分类法(第1.2节)。
While much literature on prompting focuses on English-only settings, we also discuss multilingual techniques (Section 3.1). Given the rapid growth in multimodal prompting, where prompts may include media such as images, we also expand our scope to multimodal techniques (Section 3.2). Many mul- tilingual and multimodal prompting techniques are direct extensions of English text-only prompting techniques.
虽然许多关于提示的文献都集中在仅使用英语的环境中,但我们也讨论了多语言技术(第3.1节)。鉴于多模态提示的快速发展(其中提示可能包括图像等媒体),我们还将研究范围扩展到多模态技术(第3.2节)。许多多语言和多模态提示技术都是仅使用英语的文本提示技术的直接扩展。
As prompting techniques grow more complex, they have begun to incorporate external tools, such as Internet browsing and calculators. We use the term ‘agents‘ to describe these types of prompting techniques (Section 4.1).
随着提示技术变得越来越复杂,它们已经开始整合外部工具,例如互联网浏览和计算器。我们使用术语“代理(agents)”来描述这些类型的提示技术(第4.1节)。
It is important to understand how to evaluate the outputs of agents and prompting techniques to ensure accuracy and avoid hallucinations. Thus, we discuss ways of evaluating these outputs (Sec-
tion 4.2). We also discuss security (Section 5.1) and safety measures (Section 5.2) for designing prompts that reduce the risk of harm to companies and users.
理解如何评估代理和提示技术的输出以确保准确性并避免幻觉非常重要。因此,我们讨论了评估这些输出的方法(第4.2节)。我们还讨论了为设计能够降低对公司和用户造成损害的风险的提示而采取的安全措施(第5.1节)和保障措施(第5.2节)。
Finally, we apply prompting techniques in two case studies (Section 6.1). In the first, we test a range of prompting techniques against the commonly used benchmark MMLU (Hendrycks et al., 2021). In the second, we explore in detail an example of manual prompt engineering on a significant, real-world use case, identifying signals of frantic hopelessness a top indicator of suicidal crisis–in the text of individuals seeking support (Schuck et al., 2019a). We conclude with a discussion of the nature of prompting and its recent development (Section 8).
最后,我们在两个案例研究中应用了提示技术(第6.1节)。在第一个案例中,我们使用常用的基准MMLU(Hendrycks等人,2021)测试了一系列提示技术。在第二个案例中,我们详细探讨了一个在重要的真实世界用例中进行人工提示工程的例子,即在寻求支持的个人的文本中识别出极度绝望的信号——这是自杀危机的主要指标(Schuck等人,2019a)。我们最后讨论了提示的本质及其最新发展(第8节)。
1.1 什么是提示词?(What is a Prompt? )
A prompt is an input to a Generative AI model, that is used to guide its output (Meskó, 2023; White et al., 2023; Heston and Khun, 2023; Hadi et al., 2023; Brown et al., 2020). Prompts may consist of text, image, sound, or other media. Some examples of prompts include: “write a three paragraph email for a marketing campaign for an accounting firm”, a photograph of a table accompanied by the text “describe everything on the table”, or a recording of an online meeting, with the instructions “summarize this”.
提示是对生成式人工智能模型的输入,用于指导其输出(Meskó, 2023;White等,2023;Heston和Khun,2023;Hadi等,2023;Brown等,2020)。提示可以由文本、图像、声音或其他媒体组成。一些提示的示例包括:“写一封三段的营销邮件,用于会计事务所的市场营销活动”、一张桌子的照片,附带文本“描述桌子上的所有物品”或一段在线会议的录音,附带指令“总结一下”。
Prompt Template Prompts are often constructed via a prompt template (Shin et al., 2020b). A prompt template is a function that contains one or more variables which will be replaced by some media (usually text) to create a prompt. This prompt can then be considered to be an instance of the template.
提示模板 提示通常通过提示模板构造(Shin等,2020b)。提示模板是一个包含一个或多个变量的函数,这些变量将被某些媒体(通常是文本)替换,以创建一个提示。这个提示可以被视为模板的一个实例。
Classify the tweet as positive or negative: {TWEET}Each tweet in the dataset would be inserted into a separate instance of the template and the resulting prompt would be given to a LLM for inference.
数据集中的每条推文都将被插入到模板的一个单独实例中,并且生成的提示将被提供给LLM进行推断。
Write a poem about trees. Write a poem about the following topic: {USER_INPUT}Figure 1.2: Prompts and prompt templates are distinct concepts; a prompt template becomes a prompt when input is inserted into it.
Figure 1.2:提示和提示模板是不同的概念;当输入被插入到提示模板中时,提示模板就变成了提示。
Paper外扩展部分:
这句话的核心意思是:提示模板是“模具”,提示是“成品”。
- 提示模板(Prompt Template): 这是一个预先定义好的结构,其中包含一些“占位符”或“变量”,等待被具体的内容填充。它就像一个填空题的模板,或者一个信件的草稿,其中一些地方需要你填写具体的信息。
-
- 例子: “请用 {主题} 写一篇 {字数} 的文章。”
在这个例子中,“{主题}”和“{字数}”就是占位符(变量),它们等待被具体的主题和字数填充。
- 提示(Prompt): 这是最终发送给大型语言模型(LLM)的完整指令。它是通过将具体的内容填充到提示模板的占位符中生成的。它就像填空题的答案,或者写好的信件。
-
- 例子: 如果我们用“人工智能”填充“{主题}”,用“500字”填充“{字数}”,那么我们就得到了一个具体的提示:“请用人工智能写一篇500字的文章。”
这个完整的句子就是一个提示,可以直接发送给LLM。
用一个更形象的比喻:
- 提示模板: 就像一个做饼干的模具。模具本身并不能直接吃,它只是一个形状。
- 提示: 就像用模具做出来的饼干。饼干才是可以直接食用的“成品”。
总结:
| 特征 |
提示模板 (Prompt Template) |
提示 (Prompt) |
| 本质 |
一个通用的结构、模式或配方,包含变量或占位符。 |
一个具体的指令,可以直接发送给LLM。 |
| 作用 |
用于生成多个类似的提示,提高效率和一致性。 |
用于指导LLM生成特定的输出。 |
| 例子 |
“请将以下文本翻译成 {语言}:{文本内容}” |
“请将以下文本翻译成英语:你好,世界!” |
| 关系 |
提示模板是“模具”,提示是“成品”。提示是通过将具体内容插入到提示模板中生成的。 |
提示是提示模板的一个实例。 |
Export to Sheets
理解这个区别对于进行有效的提示词工程至关重要。使用提示模板可以让你更方便地管理和修改提示,尤其是在需要处理大量数据或进行多次实验时。希望以上解释对你有所帮助!
1.2 名词术语(Terminology)
1.2.1 提示词的构成要素(Components of a Prompt)
Components of a Prompt = Directive + Examples(shots)+Output Formatting
+Style Instruction+Role+Additional Information /Context

There are a variety of common components included in a prompt. We summarize the most commonly used components and discuss how they fit into prompts.
提示中包含了多种常见的组件。我们总结了最常用的组件,并讨论它们如何融入提示中。
Directive
Directive Many prompts issue a directive in the form of an instruction or question.1 This is the core intent of the prompt, sometimes simply called the "intent". For example, here is an example of a prompt with a single instruction:
指令
指令 许多提示以指令或问题的形式发布指令。这是提示的核心意图,有时简单地称为“意图”。例如,以下是一个包含单一指令的提示示例:
Tell me five good books to read.Directives can also be implicit, as in this one- shot case, where the directive is to perform English to Spanish translation:
指令也可以是隐式的,比如在这个单次示例中,指令是晚上:黑天,早晨:? :
Night: Noche
Morning:1“Directives”, from Searle (1969), are a type of speech act intended to encourage an action, and have been invoked in models of human-computer dialogue Morelli et al. (1991).
“指令”(Directives)来自Searle(1969),是一种旨在鼓励某种行为的言语行为,并在计算机与人类对话的模型中被引用(Morelli等,1991)。
Examples
Examples, also known as exemplars or shots, act as demonstrations that guide the GenAI to accomplish a task. The above prompt is a One- Shot (i.e. one example) prompt.
示例
示例(也称为典型示例或“shots”)作为演示,帮助生成式人工智能(GenAI)完成任务。上述提示是一个单次示例(One-Shot)提示,即提供一个示例。
Output Formatting It is often desirable for the GenAI to output information in certain formats, for example, CSVs or markdown formats (Xia et al., 2024). To facilitate this, you can simply add in- structions to do so as seen below:
{PARAGRAPH} Summarize this into a CSV.Style Instructions Style instructions are a type of output formatting used to modify the output stylistically rather than structurally (Section 2.2.2). For example:
输出格式
通常希望生成式人工智能(GenAI)以特定格式输出信息,例如CSV格式或Markdown格式(Xia等,2024)。为了实现这一点,可以在提示中直接添加相应的指令,如下所示:
Write a clear and curt paragraph about lla- mas. Role A Role, also known as a persona (Schmidt et al., 2023; Wang et al., 2023l), is a frequently discussed component that can improve writing and style text (Section 2.2.2). For example:
角色
角色(也称为个性,Schmidt等,2023;Wang等,2023)是一个经常讨论的组件,可以改善写作和文本风格(第2.2.2节)。例如:
Pretend you are a shepherd and write a lim- erick about llamas.Additional Information
It is often necessary to include additional information in the prompt. For example, if the directive is to write an email, you might include information such as your name and position so the GenAI can properly sign the email. Additional Information is sometimes called ‘con- text‘, though we discourage the use of this term as it is overloaded with other meanings in the prompt- ing space2.
2 e.g. the context is the tokens processed by the LLM in a forward pass
附加信息
在提示中通常需要包含附加信息。例如,如果指令是写一封电子邮件,你可能需要提供诸如姓名和职位等信息,以便生成式人工智能(GenAI)能够正确地签署邮件。附加信息有时也被称为“上下文”,但我们不建议使用这个术语,因为它在提示领域中有许多其他含义。
2 例如,“上下文”指的是LLM在前向传递过程中处理的标记(tokens)。
1.2.2 提示词术语(Prompting Terms)
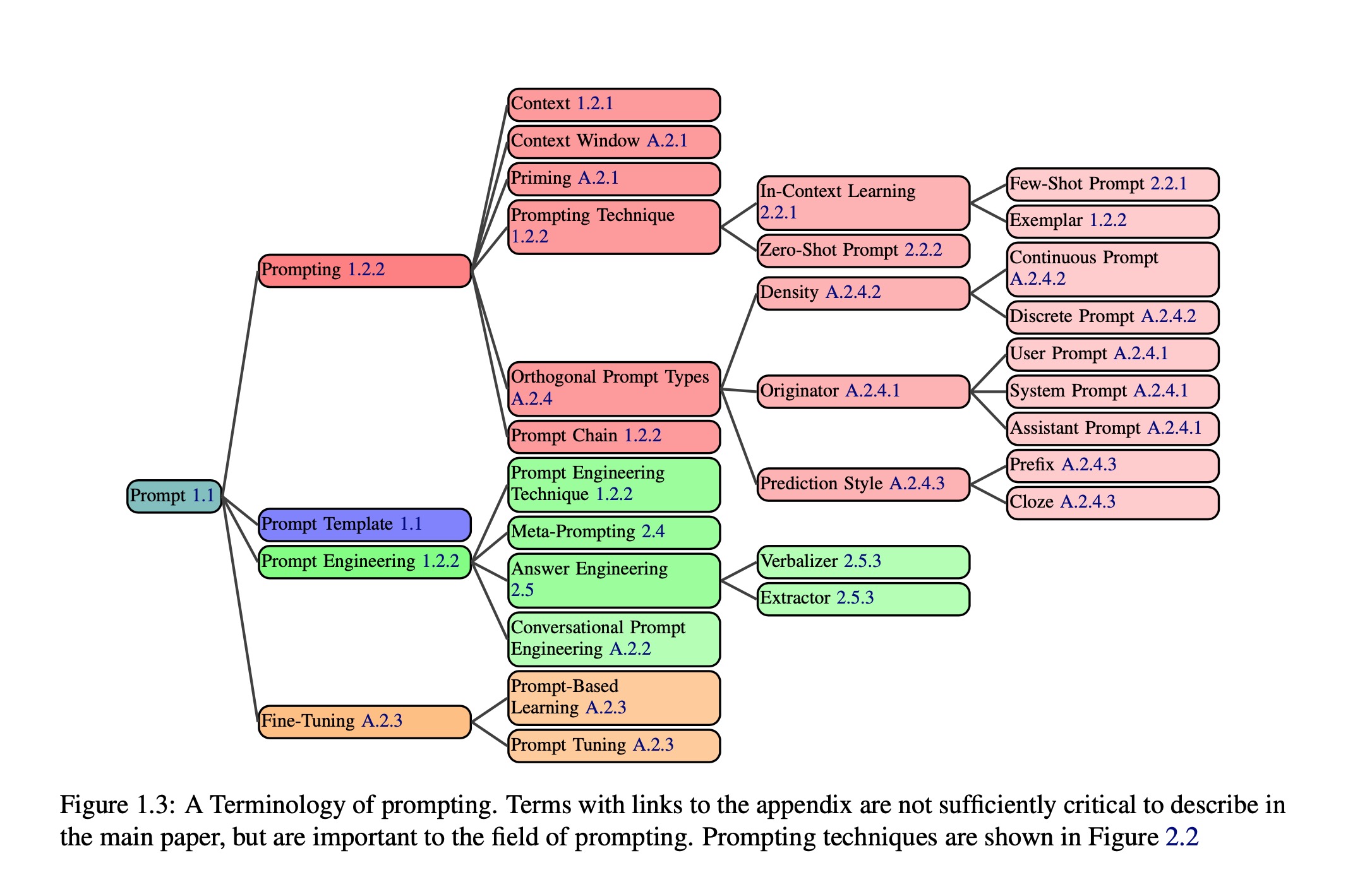
Terminology within the prompting literature is rapidly developing. As it stands, there are many poorly understood definitions (e.g. prompt, prompt engineering) and conflicting ones (e.g. role prompt vs persona prompt). The lack of a consistent vocab- ulary hampers the community’s ability to clearly describe the various prompting techniques in use. We provide a robust vocabulary of terms used in the prompting community (Figure 1.3).3 Less frequent terms are left to Appendix A.2. In order to accu- rately define frequently-used terms like prompt and prompt engineering, we integrate many definitions (Appendix A.1) to derive representative definitions.
提示文献中的术语正在迅速发展。目前,存在许多定义不清楚的术语(例如:提示、提示工程)和相互冲突的定义(例如:角色提示与个性提示)。缺乏一致的词汇体系阻碍了社区清晰地描述当前使用的各种提示技术。我们提供了一个稳固的提示社区术语词汇表(见图1.3)。不常见的术语则留在附录A.2中。为了准确地定义常用术语,如“提示”和“提示工程”,我们整合了多个定义(见附录A.1)来得出具有代表性的定义。
Prompting
Prompting is the process of providing a prompt to a GenAI, which then generates a response. For example, the action of sending a chunk of text or uploading an image constitutes prompting.
提示
提示是向生成式人工智能(GenAI)提供一个提示的过程,模型随后生成响应。例如,发送一段文本或上传一张图片都构成了提示。
Prompt Chain A prompt chain (activity: prompt chaining) consists of two or more prompt templates used in succession. The output of the prompt generated by the first prompt template is used to parameterize the second template, continuing until all templates are exhausted (Wu et al., 2022).
提示链
提示链(活动:提示链式)由两个或更多提示模板按顺序使用组成。第一个提示模板生成的输出用于参数化第二个模板,依此类推,直到所有模板都被用尽(Wu等,2022)。
Prompting Technique A prompting technique is a blueprint that describes how to structure a prompt, prompts, or dynamic sequencing of multiple prompts. A prompting technique may incorpo- rate conditional or branching logic, parallelism, or other architectural considerations spanning multiple prompts.
提示技术
提示技术是一个蓝图,描述了如何构造一个提示、多个提示,或多个提示的动态排序。提示技术可能包含条件逻辑或分支逻辑、并行处理或其他涉及多个提示的架构考虑因素。
Prompt Engineering Prompt engineering is the iterative process of developing a prompt by modify- ing or changing the prompting technique that you are using (Figure 1.4).
提示工程
提示工程是通过修改或更改使用的提示技术来反复开发一个提示的过程(见图1.4)。
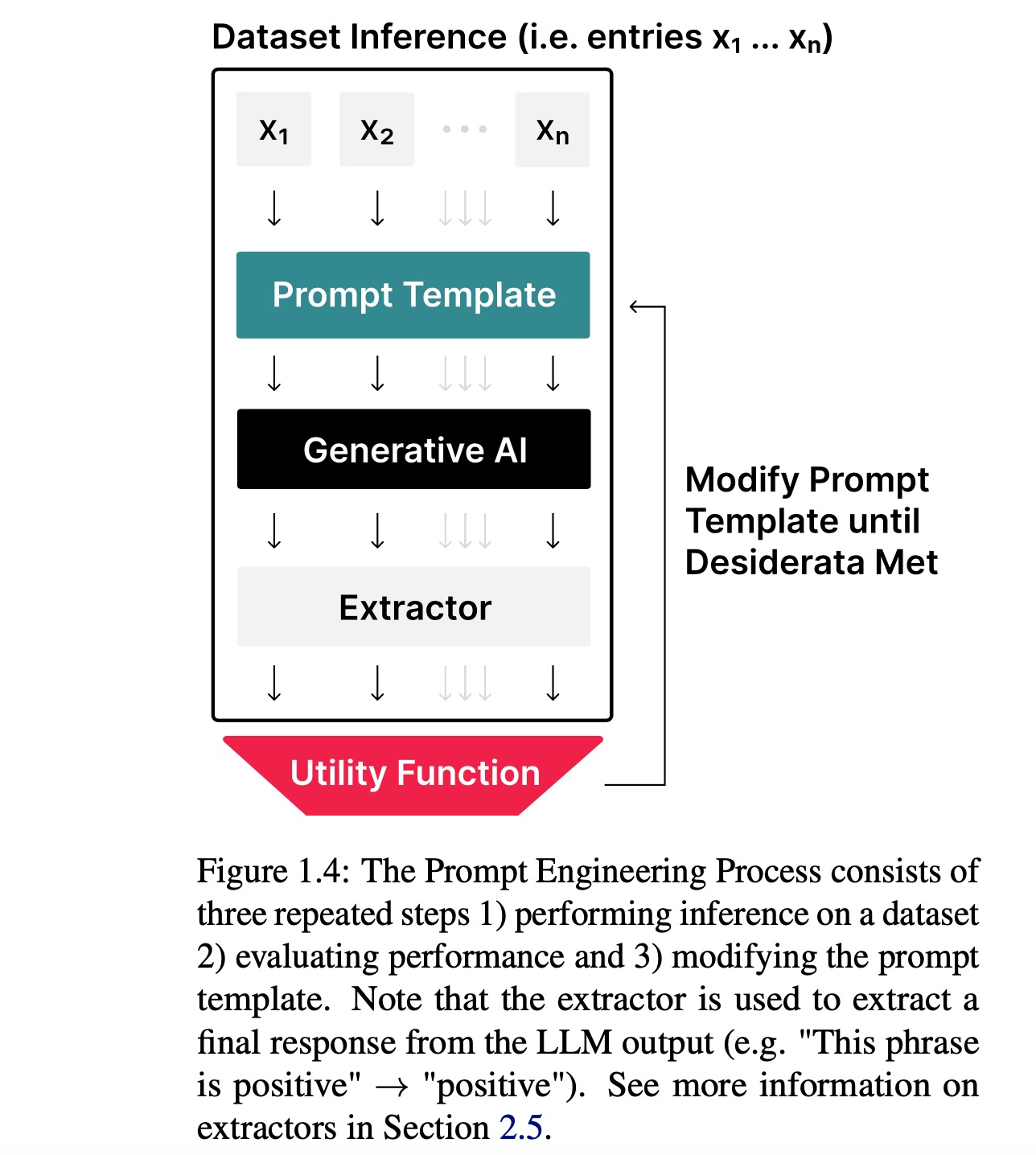
Prompt Engineering Technique A prompt engineering technique is a strategy for iterating on a prompt to improve it. In literature, this will often be automated techniques (Deng et al., 2022), but in consumer settings, users often perform prompt engineering manually.
提示工程技术
提示工程技术是改进提示的策略。在文献中,这通常是指自动化技术(Deng等,2022),但在消费者场景中,用户通常手动进行提示工程。
Exemplar Exemplars are examples of a task being completed that are shown to a model in a prompt (Brown et al., 2020).
典型示例
典型示例是任务完成的示例,这些示例在提示中展示给模型(Brown等,2020)。
1.3 提示词较短的历史(A Short History of Prompts)
The idea of using natural language prefixes, or prompts, to elicit language model behaviors and
responses originated before the GPT-3 and Chat- GPT era. GPT-2 (Radford et al., 2019a) makes use of prompts and they appear to be first used in the context of Generative AI by Fan et al. (2018). However, the concept of prompts was preceded by related concepts such as control codes (Pfaff, 1979; Poplack, 1980; Keskar et al., 2019) and writing prompts.
The term Prompt Engineering appears to have come into existence more recently from Radford et al. (2021) then slightly later from Reynolds and McDonell (2021).
However, various papers perform prompt engi- neering without naming the term (Wallace et al., 2019; Shin et al., 2020a), including Schick and Schütze (2020a,b); Gao et al. (2021) for non- autoregressive language models.
Some of the first works on prompting define a prompt slightly differently to how it is currently used. For example, consider the following prompt from Brown et al. (2020):
Translate English to French: llamaBrown et al. (2020) consider the word "llama" to be the prompt, while "Translate English to French:" is the "task description". More recent papers, in- cluding this one, refer to the entire string passed to the LLM as the prompt.
使用自然语言前缀或提示来引导语言模型的行为和响应的想法,早在GPT-3和ChatGPT时代之前就已出现。GPT-2(Radford等,2019a)使用了提示,并且看起来首次在生成式人工智能(Generative AI)领域被Fan等(2018)采用。然而,提示的概念之前已经有相关的概念,如控制代码(Pfaff,1979;Poplack,1980;Keskar等,2019)和写作提示。
“提示工程”(Prompt Engineering)一词似乎是近期才出现的,最早由Radford等(2021)提出,稍后由Reynolds和McDonell(2021)进一步发展。然而,一些论文在没有明确使用“提示工程”这一术语的情况下,仍然进行了提示工程(Wallace等,2019;Shin等,2020a),包括Schick和Schütze(2020a,b);Gao等(2021)针对非自回归语言模型的研究。
一些关于提示的早期研究对提示的定义与当前的使用方式略有不同。例如,考虑Brown等(2020)中的以下提示:
翻译英语到法语: llama
Brown等(2020)将单词“llama”视为提示,而将“Translate English to French:”视为“任务描述”。然而,更近期的论文(包括本文)将传递给LLM的整个字符串都视为提示。
2 A Meta-Analysis of Prompting(提示词元分析)
2.1 Systematic Review Process
In order to robustly collect a dataset of sources for this paper, we ran a systematic literature re- view grounded in the PRISMA process (Page et al., 2021) (Figure 2.1). We host this dataset on Hug- gingFace and present a datasheet (Gebru et al., 2021) for the dataset in Appendix A.3. Our main data sources were arXiv, Semantic Scholar, and ACL. We query these databases with a list of 44 keywords narrowly related to prompting and prompt engineering (Appendix A.4).
2.1.1 The Pipeline
In this section, we introduce our data scraping pipeline, which includes both human and LLM-assisted review.4 As an initial sample to establish filtering critera, we retrieve papers from arXiv based on a simple set of keywords and boolean rules (A.4). Then, human annotators label a sample of 1,661 articles from the arXiv set for the following criteria:
- Does the paper propose a novel prompting technique? (include)
- Does the paper strictly cover hard prefix prompts? (include)
- Does the paper focus on training by backpropagating gradients? (exclude)
- For non-text modalities, does it use a masked frame and/or window? (include)
A set of 300 articles are reviewed independently by two annotators, with 92% agreement (Krippendorff’s α = Cohen’s κ = 81%). Next, we develop a prompt using GPT-4-1106-preview to classify the remaining articles. We validate the prompt against 100 ground-truth annotations, achieving 89% precision and 75% recall (for an F1 of 81%). The combined human and LLM annotations generate a final set of 1,565 papers.
A set of 300 articles are reviewed independently by two annotators, with 92% agreement (Krippen- dorff’s α = Cohen’s κ = 81%). Next, we develop a prompt using GPT-4-1106-preview to classify the remaining articles. We validate the prompt against 100 ground-truth annotations, achieving 89% pre- cision and 75% recall (for an F1 of 81%). The combined human and LLM annotations generate a final set of 1,565 papers.
2 提示的元分析
2.1 系统性综述流程 为了严谨地收集本文的文献来源数据集,我们进行了一项基于PRISMA流程(Page等人,2021)(图2.1)的系统性文献综述。我们将此数据集托管在HuggingFace上,并在附录A.3中提供了该数据集的数据表(Gebru等人,2021)。我们的主要数据来源是arXiv、Semantic Scholar和ACL。我们使用一份包含44个与提示和提示工程密切相关的关键词列表(附录A.4)在这些数据库中进行检索。
2.1.1 流程 在本节中,我们将介绍我们的数据抓取流程,其中包括人工和大型语言模型(LLM)辅助的审阅。⁴ 为了建立筛选标准,我们首先基于一组简单的关键词和布尔规则(A.4)从arXiv检索论文作为初始样本。然后,人工标注员根据以下标准对来自arXiv的1661篇文章的样本进行标注:
- 该论文是否提出了一种新颖的提示技术?(包含)
- 该论文是否严格涵盖了硬前缀提示?(包含)
- 该论文是否侧重于通过反向传播梯度进行训练?(排除)
- 对于非文本类型的数据,它是否使用了掩码框架和/或窗口?(包含)
我们请两位标注员独立审阅了其中的300篇文章,他们的标注结果一致性很高,达到了92%(使用克里彭多夫α系数和科恩κ系数计算,均为81%)。然后,我们使用GPT-4-1106-preview开发了一个提示词,用于对剩余的文章进行分类。我们使用100条人工标注的“标准答案”来验证这个提示词的效果,结果表明,其精确率为89%,召回率为75%(F1值为81%)。结合人工标注和大型语言模型(LLM)的标注结果,我们最终得到了包含1565篇论文的完整数据集。
(重复部分省略,与上文相同)
解释:
- 2 A Meta-Analysis of Prompting / 2 提示的元分析: “元分析”是对已有的研究进行综合分析的研究方法。
- 2.1 Systematic Review Process / 2.1 系统性综述流程: “系统性综述”是一种严谨的文献研究方法,旨在全面、系统地回顾和评价某一特定主题的所有相关研究。
- PRISMA process / PRISMA流程: PRISMA是“系统评价和Meta分析的首选报告条目”的缩写,是一套用于规范系统评价报告的指南。
- HuggingFace: 一个流行的用于共享和使用机器学习模型、数据集和应用的平台。
- datasheet / 数据表: 描述数据集的元数据和特征的文档。
- arXiv, Semantic Scholar, and ACL: 重要的学术论文数据库和会议。
- keywords and boolean rules / 关键词和布尔规则: 用于数据库检索的常用方法,例如使用“AND”、“OR”、“NOT”等布尔运算符连接关键词。
- data scraping pipeline / 数据抓取流程: 自动从网络或其他来源提取数据的过程。
- human and LLM-assisted review / 人工和大型语言模型(LLM)辅助的审阅: 说明数据筛选和标注过程既有人工参与,也有LLM的辅助。
- filtering criteria / 筛选标准: 用于判断哪些论文应该被纳入研究的标准。
- novel prompting technique / 新颖的提示技术: 指的是提出了新的提示方法或改进了现有方法的论文。
- hard prefix prompts / 硬前缀提示: 一种特定的提示技术,这里不做深入解释,读者可以查阅相关资料。
- training by backpropagating gradients / 通过反向传播梯度进行训练: 深度学习中常用的训练方法,这里被排除在外,说明研究的重点不是模型的训练方法,而是提示技术本身。
- non-text modalities / 非文本类型的数据: 指图像、音频、视频等非文本数据。
- masked frame and/or window / 掩码框架和/或窗口: 计算机视觉和多模态学习中常用的技术,用于处理非文本数据。
- annotators / 标注员: 负责对数据进行标注的人员。
- agreement / 一致性: 指不同标注员对同一数据的标注结果的相似程度。
- Krippendorff’s α / 克里彭多夫α系数和 Cohen’s κ / 科恩κ系数: 衡量标注一致性的统计指标。
- GPT-4-1106-preview: GPT-4的一个预览版本。
- prompt / 提示词: 用于引导LLM完成任务的输入。
- ground-truth annotations / 人工标注的“标准答案”: 人工标注的正确答案,用于评估模型的性能。
- precision / 精确率、 recall / 召回率、F1 / F1值: 评估分类模型性能的常用指标。

Figure 2.1:The PRISMA review process. We accumulate 4,247 unique records from which we extract 1,565 relevant records.
2.2Text-Based Techniques(基于文本的技术)
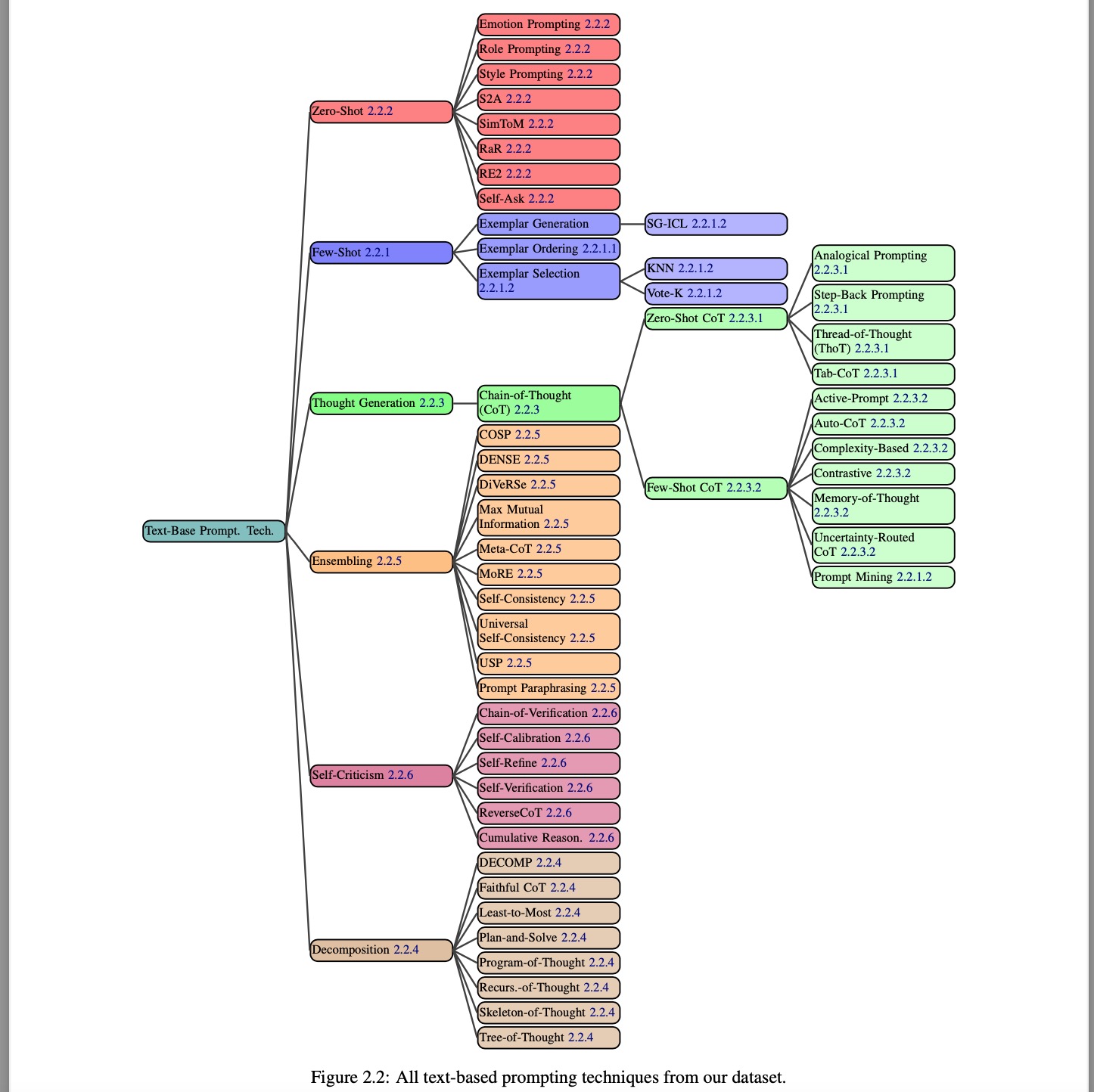
We now present a comprehensive taxonomical ontology of 58 text-based prompting techniques, broken into 6 major categories (Figure 2.2). Although some of the techniques might fit into multiple categories, we place them in a single category of most relevance.
2.2.1 In-Context Learning (ICL)
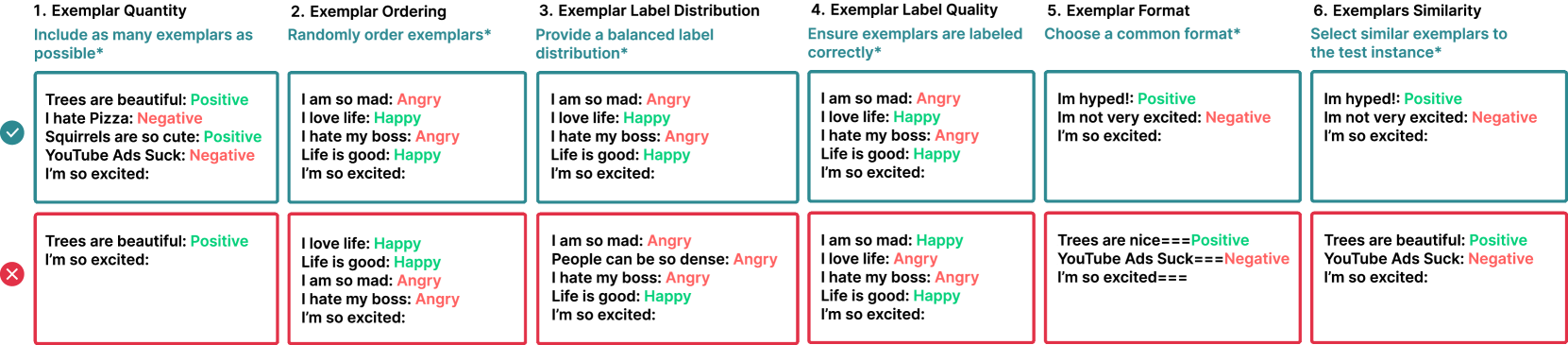
Figure 2.3:We highlight six main design decisions when crafting few-shot prompts. ∗Please note that recommendations here do not generalize to all tasks; in some cases, each of them could hurt performance.
ICL refers to the ability of GenAIs to learn skills and tasks by providing them with exemplars and or relevant instructions within the prompt, without the need for weight updates/retraining (Brown et al., 2020; Radford et al., 2019b). These skills can be learned from exemplars (Figure 2.4) and/or instruc- tions (Figure 2.5). Note that the word ’learn’ is misleading. ICL can simply be task specification– the skills are not necessarily new, and can have already been included in the training data (Figure 2.6). See Appendix A.8 for a discussion of the use of this term. Significant work is currently being done on optimizing (Bansal et al., 2023) and un- derstanding (Si et al., 2023a; Štefánik and Kadlcˇík, 2023) ICL.
Few-Shot Prompting (Brown et al., 2020) is the paradigm seen in Figure 2.4, where the GenAI learns to complete a task with only a few exam- ples (exemplars).
2+2: four
4+5: nine
8+0:Figure 2.4: ICL exemplar prompt
Extract all words that have 3 of the same letter and at least 3 other letter from the following text: {TEXT}Figure 2.5: ICL instruction prompt
Few-Shot Learning (FSL) (Fei-Fei et al., 2006; Wang et al., 2019) is often conflated with Few-Shot Prompting (Brown et al., 2020). It is important to note that FSL is a broader machine learning paradigm to adapt parameters with a few examples, while Few-Shot Prompting is specific to prompts in the GenAI settings and does not involve updating model parameters.
2.2.1.1 Few-Shot Prompting Design Decisions(少样本提示设计决策)
Selecting exemplars for a prompt is a difficult task– performance depends significantly on various fac- tors of the exemplars (Dong et al., 2023), and only a limited number of exemplars fit in the typical LLM’s context window. We highlight six separate design decisions, including the selection and or- der of exemplars that critically influence the output quality (Zhao et al., 2021a; Lu et al., 2021; Ye and Durrett, 2023) (Figure 2.3).
Exemplar Quantity Increasing the quantity of ex- emplars in the prompt generally improves model performance, particularly in larger models (Brown et al., 2020). However, in some cases, the bene- fits may diminish beyond 20 exemplars (Liu et al., 2021).
Translate the word "cheese" to French.Figure 2.6: ICL from training data prompt. In this version of ICL, the model is not learning a new skill, but rather using knowledge likely in its training set.
Exemplar Ordering The order of exemplars af- fects model behavior (Lu et al., 2021; Kumar and Talukdar, 2021; Liu et al., 2021; Rubin et al., 2022). On some tasks, exemplar order can cause accuracy to vary from sub-50% to 90%+ (Lu et al., 2021).
Exemplar Label Distribution As in traditional supervised machine learning, the distribution of exemplar labels in the prompt affects behavior. For example, if 10 exemplars from one class and 2 exemplars of another class are included, this may cause the model to be biased toward the first class.
Exemplar Label Quality Despite the general ben- efit of multiple exemplars, the necessity of strictly valid demonstrations is unclear. Some work (Min et al., 2022) suggests that the accuracy of labels is irrelevant—providing models with exemplars with incorrect labels may not negatively diminish per- formance. However, under certain settings, there is a significant impact on performance (Yoo et al., 2022). Larger models are often better at handling incorrect or unrelated labels (Wei et al., 2023c).
It is important to discuss this factor, since if you are automatically constructing prompts from large datasets that may contain inaccuracies, it may be necessary to study how label quality affects your results.
Exemplar Format The formatting of exemplars also affects performance. One of the most common formats is “Q: {input}, A: {label}”, but the optimal format may vary across tasks; it may be worth trying multiple formats to see which performs best.
There is some evidence to suggest that formats that occur commonly in the training data will lead to better performance (Jiang et al., 2020).
Exemplar Similarity Selecting exemplars that are similar to the test sample is generally bene- ficial for performance (Liu et al., 2021; Min et al., 2022). However, in some cases, selecting more diverse exemplars can improve performance (Su et al., 2022; Min et al., 2022).
2.2 基于文本的技术
我们现在介绍58种基于文本的提示技术的全面分类本体,并将其分为6个主要类别(见图2.2)。尽管有些技术可能适用于多个类别,但我们将它们放置在最相关的单一类别中。
2.2.1 上下文学习(ICL)
ICL指的是通过在提示中提供示例和/或相关指令,GenAI在不需要更新权重/重新训练的情况下学习技能和任务的能力(Brown等,2020;Radford等,2019b)。这些技能可以通过示例(见图2.4)和/或指令(见图2.5)来学习。需要注意的是,“学习”一词可能会误导人。ICL仅仅是任务规范—这些技能不一定是新的,可能已经包含在训练数据中(见图2.6)。有关该术语使用的讨论,请参见附录A.8。目前,关于优化(Bansal等,2023)和理解(Si等,2023a;Štefánik和Kadlcík,2023)ICL的工作正在进行中。
---- 少样本提示(Few-Shot Prompting)(Brown等,2020)是图2.4中看到的范式,GenAI通过仅提供少量示例(示例)来学习完成任务。
例如: 2+2:四
4+5:九
8+0:
图2.4:ICL示例提示
从以下文本中提取所有包含3个相同字母并且至少包含3个其他字母的单词:{TEXT}
图2.5:ICL指令提示
---- 少样本学习(Few-Shot Learning,FSL)(Fei-Fei等,2006;Wang等,2019)通常与少样本提示(Few-Shot Prompting)(Brown等,2020)混淆。需要注意的是,FSL是一个更广泛的机器学习范式,旨在通过少量示例来调整参数,而少样本提示则特指在GenAI设置中的提示,不涉及更新模型参数。
2.2.1.1 少样本提示设计决策
为提示选择示例是一项困难的任务——性能在很大程度上取决于示例的各种因素(Dong等,2023),而且通常只有有限数量的示例适合典型LLM的上下文窗口。我们强调六个独立的设计决策,包括示例的选择和顺序,这些都对输出质量有重要影响(Zhao等,2021a;Lu等,2021;Ye和Durrett,2023)(见图2.3)。
---- 示例数量 增加提示中的示例数量通常能提高模型性能,尤其是在更大的模型中(Brown等,2020)。然而,在某些情况下,超过20个示例后,收益可能会减少(Liu等,2021)。
翻译单词“cheese”成法语。
图2.6:来自训练数据的ICL提示 在此版本的ICL中,模型并未学习新技能,而是使用其训练集中的知识。
---- 示例顺序 示例的顺序会影响模型的行为(Lu等,2021;Kumar和Talukdar,2021;Liu等,2021;Rubin等,2022)。在某些任务中,示例顺序可以导致准确率从低于50%波动到90%以上(Lu等,2021)。
---- 示例标签分布 与传统的监督式机器学习一样,提示中示例标签的分布会影响模型行为。例如,如果提示中包含10个来自一个类别的示例和2个来自另一个类别的示例,这可能会导致模型对第一个类别产生偏向。
---- 示例标签质量 尽管多个示例的普遍好处已被证明,但严格有效的演示示例的必要性仍不明确。一些研究(Min等,2022)表明,标签的准确性可能无关紧要——提供带有错误标签的示例可能不会显著降低性能。然而,在某些设置下,标签质量对性能有显著影响(Yoo等,2022)。大型模型通常更擅长处理错误或不相关的标签(Wei等,2023c)。
讨论这一因素很重要,因为如果你正在自动构建来自大数据集的提示,而这些数据集可能包含不准确的信息,你可能需要研究标签质量如何影响结果。
---- 示例格式 示例的格式也会影响性能。最常见的格式之一是“Q: {input}, A: {label}”,但最优格式可能会根据任务有所不同;值得尝试多种格式,以查看哪种格式表现最佳。有证据表明,在训练数据中常见的格式会导致更好的性能(Jiang等,2020)。
---- 示例相似度 选择与测试样本相似的示例通常对性能有利(Liu等,2021;Min等,2022)。然而,在某些情况下,选择更多样化的示例可能会提高性能(Su等,2022;Min等,2022)。
2.2.1.2 Few-Shot Prompting Techniques
Considering all of these factors, Few-Shot Prompt- ing can be very difficult to implement effectively. We now examine techniques for Few-Shot Prompt- ing in the supervised setting. Ensembling ap- proaches can also benefit Few-Shot Prompting, but we discuss them separately (Section 2.2.5).
Assume we have a training dataset, Dtrain, which contains multiple inputs Dtrain and output
train xi
Dyi , which can be used to few-shot prompt a GenAI (rather than performing gradient-based up-
dates). Assume that this prompt can be dynamically generated with respect to Dtest at test time. Here xi is the prompt template we will use for this section, following the ‘input: output‘ format (Figure 2.4):
{Exemplars}
Dtest:
Figure 2.7: Few-Shot Prompting Template
K-Nearest Neighbor (KNN) (Liu et al., 2021) is
part of a family of algorithms that selects exemplars
similar to Dtest to boost performance. Although ef- xi
fective, employing KNN during prompt generation may be time and resource intensive.
Vote-K (Su et al., 2022) is another method to select similar exemplars to the test sample. In one stage, a model proposes useful unlabeled candidate exemplars for an annotator to label. In the sec- ond stage, the labeled pool is used for Few-Shot Prompting. Vote-K also ensures that newly added exemplars are sufficiently different than existing ones to increase diversity and representativeness.
Self-Generated In-Context Learning (SG-ICL)
(Kim et al., 2022) leverages a GenAI to automati- cally generate exemplars. While better than zero- shot scenarios when training data is unavailable,the generated samples are not as effective as actual data.
Prompt Mining (Jiang et al., 2020) is the process of discovering optimal "middle words" in prompts (effectively prompt templates) through large corpus analysis. For example, instead of using the com- mon "Q: A:" format for few-shot prompts, there may exist something similar which occurs more fre- quently in the corpus. Formats which occur more often in the corpus will likely lead to improved prompt performance.
More Complicated Techniques such as LENS (Li and Qiu, 2023a), UDR (Li et al., 2023f), and Active Example Selection (Zhang et al., 2022a) leverage iterative filtering, embedding and retrieval, and reinforcement learning, respectively.
2.2.1.2 少样本提示技术
考虑到所有这些因素,少样本提示(Few-Shot Prompting)的有效实现可能非常具有挑战性。现在我们来探讨监督设置下的少样本提示技术。集成方法也可以为少样本提示带来益处,但我们将在单独的部分讨论它们(第2.2.5节)。
假设我们有一个训练数据集 DtrainDtrain,其中包含多个输入 xixi 和对应的输出 yiyi,这些可以用于少样本提示生成式AI(而不是进行基于梯度的更新)。假设这个提示可以根据测试时的 DtestDtest 动态生成。这里 xixi 是我们将在这部分使用的提示模板,采用“输入: 输出”的格式(图2.4):
图2.7:少样本提示模板
plaintext
深色版本
{示例}
D_{\text{test}}:K-近邻 (KNN)
K-近邻(K-Nearest Neighbor, KNN)(Liu等,2021)是一类选择与 DtestDtest 相似的示例以提升性能的算法。虽然有效,但在提示生成过程中使用KNN可能会耗费大量的时间和资源。
Vote-K 方法
Vote-K(Su等,2022)是另一种选择与测试样本相似的示例的方法。该方法分为两个阶段:首先,模型提出对标注者有用的未标注候选示例;然后,在第二阶段,使用已标注的池来进行少样本提示。Vote-K还确保新添加的示例与现有的示例有足够的差异性,以增加多样性和代表性。
自动生成上下文学习 (SG-ICL)
自动生成上下文学习(Self-Generated In-Context Learning, SG-ICL)(Kim等,2022)利用生成式AI自动创建示例。当没有可用的训练数据时,这种方法比零样本场景更有效,但生成的样本效果不如真实数据那样好。
提示挖掘
提示挖掘(Prompt Mining)(Jiang等,2020)是指通过大规模语料库分析来发现提示中的“中间词”(即有效的提示模板)。例如,与其使用常见的“Q: A:”格式进行少样本提示,可能存在一种类似的、在语料库中出现频率更高的格式。那些在语料库中出现更频繁的格式可能会导致更好的提示性能。
更复杂的技巧
一些更复杂的技巧,如LENS(Li和Qiu,2023a)、UDR(Li等,2023f)和主动示例选择(Active Example Selection)(Zhang等,2022a),分别利用迭代过滤、嵌入和检索以及强化学习。这些技术能够进一步优化少样本提示的效果,提高模型的表现力和泛化能力。
2.2.2 Zero-Shot(零样本提示)
In contrast to Few-Shot Prompting, Zero-Shot Prompting uses zero exemplars. There are a num- ber of well known standalone zero-shot techniques as well as zero-shot techniques combine with an- other concept (e.g. Chain of Thought), which we discuss later (Section 2.2.3).
Role Prompting (Wang et al., 2023j; Zheng et al., 2023d) , also known as persona prompting (Schmidt et al., 2023; Wang et al., 2023l), assigns a specific role to the GenAI in the prompt. For exam- ple, the user might prompt it to act like "Madonna" or a "travel writer". This can create more desirable outputs for open-ended tasks (Reynolds and Mc- Donell, 2021) and in some cases improve accuracy on benchmarks (Zheng et al., 2023d).
Style Prompting (Lu et al., 2023a) involves spec- ifying the desired style, tone, or genre in the prompt to shape the output of a GenAI. A similar effect can be achieved using role prompting.
Emotion Prompting (Li et al., 2023a) incorpo- rates phrases of psychological relevance to humans (e.g., "This is important to my career") into the prompt, which may lead to improved LLM perfor- mance on benchmarks and open-ended text generation.
System 2 Attention (S2A) (Weston and Sukhbaatar, 2023) first asks an LLM to rewrite the prompt and remove any information unrelated to the question therein. Then, it passes this new prompt into an LLM to retrieve a final response.
SimToM (Wilf et al., 2023) deals with compli- cated questions which involve multiple people or objects. Given the question, it attempts to establish the set of facts one person knows, then answer the question based only on those facts. This is a two prompt process and can help eliminate the effect of irrelevant information in the prompt.
Rephrase and Respond (RaR) (Deng et al., 2023) instructs the LLM to rephrase and expand the ques- tion before generating the final answer. For ex- ample, it might add the following phrase to the question: "Rephrase and expand the question, and respond". This could all be done in a single pass or the new question could be passed to the LLM separately. RaR has demonstrated improvements on multiple benchmarks.
Re-reading (RE2) (Xu et al., 2023) adds the phrase "Read the question again:" to the prompt in addition to repeating the question. Although this is such a simple technique, it has shown improvement in reasoning benchmarks, especially with complex questions.
Self-Ask (Press et al., 2022) prompts LLMs to first decide if they need to ask follow up questions for a given prompt. If so, the LLM generates these questions, then answers them and finally answers the original question.
2.2.2 零样本提示(Zero-Shot Prompting)
与少样本提示(Few-Shot Prompting)不同,零样本提示(Zero-Shot Prompting)不使用任何示例。有许多著名的独立零样本技术,也有一些零样本技术与其他概念结合使用(例如思维链(Chain of Thought)),我们将在后面(第2.2.3节)讨论这些技术。
- 角色提示(Role Prompting)(Wang 等,2023j;Zheng 等,2023d),也称为人格提示(Persona Prompting)(Schmidt 等,2023;Wang 等,2023l),在提示中为 GenAI 分配一个特定角色。例如,用户可能会提示 GenAI 扮演“麦当娜”或“旅行作家”的角色。这可以为开放式任务(Reynolds 和 McDonell,2021)创造更理想的输出,并在某些情况下提高基准测试的准确性(Zheng 等,2023d)。
- 风格提示(Style Prompting)(Lu 等,2023a)涉及在提示中指定所需的风格、语气或类型,以塑造 GenAI 的输出。使用角色提示也可以达到类似的效果。
- 情感提示(Emotion Prompting)(Li 等,2023a)将与人类心理相关的短语(例如,“这对我的职业生涯很重要”)纳入提示中,这可能有助于提高 LLM 在基准测试和开放式文本生成中的表现。
- 系统 2 注意力(System 2 Attention, S2A)(Weston 和 Sukhbaatar,2023)首先要求 LLM 重写提示并去除与问题无关的信息。然后,将这个新提示传递给 LLM 以获取最终答案。
- SimToM(Wilf 等,2023)处理涉及多个参与者或对象的复杂问题。给定问题后,它会尝试建立每个参与者所知道的事实集合,然后仅基于这些事实回答问题。这是一个双提示过程,有助于消除提示中不相关信息的影响。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









