




 本文详细介绍了人脸识别的原理,包括人脸检测、对齐、特征编码和编码比对,采用MTCNN和InsightFace模型。接着,阐述了人脸搜索的整体设计,包括API开发、人脸特征向量搜索和Docker部署。最后,提供了人脸搜索的实现步骤和关键代码解析,以及GitHub项目链接。
本文详细介绍了人脸识别的原理,包括人脸检测、对齐、特征编码和编码比对,采用MTCNN和InsightFace模型。接着,阐述了人脸搜索的整体设计,包括API开发、人脸特征向量搜索和Docker部署。最后,提供了人脸搜索的实现步骤和关键代码解析,以及GitHub项目链接。
人脸识别原理简要说明
要进行人脸识别,要经过这么几个过程:人脸检测—人脸对齐—提取特征编码—编码比对。
-
人脸检测:就是定位一张图片中人脸的位置。
-
人脸对齐:就是根据人脸中五个特征点位置(两个眼睛、两个嘴角、鼻子)将人脸缩放到一定的尺寸。
-
提取特征编码:通过训练一个人脸识别模型来提取人脸特征编码。
-
编码比对:将某个人脸的编码与编码库中的编码进行对比,得出距离或相似度。
本文中人脸检测、人脸对齐使用基于 TensorFlow 的 MTCNN 模型,生成特征编码使用基于 MXNet 的 InsightFace 模型。
MTCNN 论文地址:
https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf
InsightFace 论文地址:
https://arxiv.org/abs/1801.07698
下面我介绍下 InsightFace 的主要算法:
它首先是使用一个 ResNet100 卷积网络,然后在接一个全连接层,使用一种基于 Softmax 进行改进的作者称之为 ArcFace 的损失函数进行训练。
由于 ArcFace 是基于之前其他论文提到的算法进行优化的,所以要讲清楚 ArcFace ,就必须要先讲清楚 Softmax、L-Softmax、SphereFace。
1.1 Softmax
损失函数:
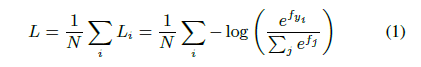
N 就是训练样本数,比如你有 100 万张人脸图片要训练,这 100 万张人脸图片归属于 10000 个人,也就是平均一个人有 100 张图片,那么分类 j 就是 1-10000 , N 就等于 100 万, i 就是在遍历这 100 万张图片。先说下 log 分子的符号, 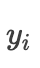 就是第 i 张图片对应的分类。log 分母的符号与分子含义相同,只不过分子是第 i 张图片所属分类的概率值,而分母是所有分类的概率值的汇总。
就是第 i 张图片对应的分类。log 分母的符号与分子含义相同,只不过分子是第 i 张图片所属分类的概率值,而分母是所有分类的概率值的汇总。
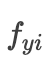 就可以理解为全连接层的输出,也就是:
就可以理解为全连接层的输出,也就是:
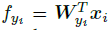
上面这个式子就是 W 和 x 的内积,因此可以写成下面这样:
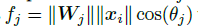
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3430
3430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









