






 本文深入探讨了PCA(主成分分析)的几何理解和数学推导,揭示了PCA如何通过最大化数据方差来实现降维,同时保持数据的主要特征。文章详细介绍了PCA的实施步骤,包括样本数据的中心化、协方差矩阵的计算、特征值与特征向量的求解,以及数据投影到主成分的过程。
本文深入探讨了PCA(主成分分析)的几何理解和数学推导,揭示了PCA如何通过最大化数据方差来实现降维,同时保持数据的主要特征。文章详细介绍了PCA的实施步骤,包括样本数据的中心化、协方差矩阵的计算、特征值与特征向量的求解,以及数据投影到主成分的过程。
1、从几何的角度去理解PCA降维
以平面坐标系为例,点的坐标是怎么来的?
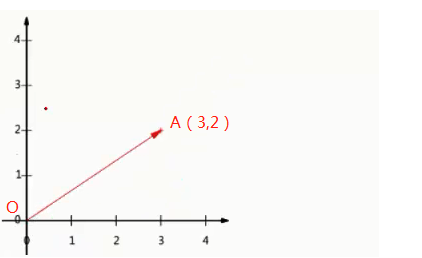
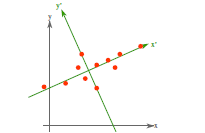
图1 图2
如上图1所示,向量OA的坐标表示为(3,2),A点的横坐标实为向量OA与单位向量(1,0)的内积得到的(也就是向量OA在单位向量(1,0)所表示的的方向上的投影的长度,正负由向量OA与投影方向的夹角决定),纵坐标同理可得。而降维的过程从几何的角度去理解,实质就可以理解为投影的过程。如上图2,二维平面上的点为例,对其降维实际就是将其投影到某一方向上,将二维数据点转换为一维数据点。显然我们可投影的方向有无数多个。并不是随意选择一个方向投影就能满足我们的要求。因为我们降维的最终目的还是为了更好更快捷的分析数据间的规律,如果我们的降维破坏掉了原数据间的规律,那这种对数据的处理是无意义的。那在处理数据时,我们就需要考虑将原始数据往哪里投影的问题?PCA已经帮我们给出了这个问题的答案。
2、PCA原理推导
2.1 最大方差理论(PCA理论基础)
在信号处理中认为信号具有较大的方差,噪声有较小的方差,信噪比就是信号与噪声的方差比,越大越好。如上述图2,样本在x'的投影方差较大,在y'的投影方差较小,那么认为纵轴上的投影是由噪声引起的。因此我们认为,最好的k维特征是将n维样本点转换为k维后,每一维上的样本方差都很大。故我们的投影方向就可以确定为样本数据方差最大的方向。对于高维度的数据,我们的投影方向要选择多个。按照我们的最大方差原理,第一个投影方向为方差最大的方向,第二个方向为方差次大的方向....,直到已经选择的投影方向的数量满足我们的要求。那如果按照这种方式去选择,会存在一个问题,即这些维度之间是近似线性相关的,如果将这些维度从集合中的坐标系去理解。显然由它们所组成的坐标系之家的夹角很小。这样显然不能完全表征数据所有特征。为了让任意两个维度能够尽可能多的表征数据的特征,我们需要选择独立的维度。举例如下:
假如我们现在要将一个具有5个维度的数据,降维到3个维度。
第一步:找到方差最大的方向,选择此方向作为第一个维度
第二步:在于第一步确定的方向正交的方向上,找到方差最大的作为第二个维度
第三步:在与第一步和第二步所选择方向正交的方向上,找到方差最大的作为第三个维度
2.2 PCA数学推导(解释了求解主成分为什么最终是求解协方差矩阵的特征值与特征向量)
如何通过数学去寻找方差最大的方向呢?
第一步:构建线性变换
问题:为什么要对样本进行线性变换?
解答:线性变化的过程应用在此处从几何的角度去理解实为(一)重新确定单位基向量与(二)原始样本集所表示的向量在新的单位基向量上投影的过程;以下述式(4)矩阵形式为例解释如下:
(一)重新确定单位基向量
如下式(4)矩阵中的每一行即为重新确定的单位基向量(p维),类比到二维平面中即就是确定如上文图2中x'和y'
(二)原始样本集所表示的向量在新的单位基向量上投影
如下式(4)中y1,y2到yp即就是数据原始样本集中的每一个样本分别在(一)中所确定的单位基向量上投影所得到的由重新确定的单位基向量所组成的坐标系下的向量每个维度的坐标值。
我们通过下述式(4)就可以表达上述(一)和(二),而(一)中重新确定的基向量要符合方差最大的要求,如何使得其满足方差最大的要求?数学原理即为如下“第二步:求解最大方差”的推导过程
设原样本数据维度为p,则可以写成![]() ,这里X表示某一样本数据,设样本集中有N个样本,则样本集的均值方差如下:
,这里X表示某一样本数据,设样本集中有N个样本,则样本集的均值方差如下:

对原样本进行如下线性变换
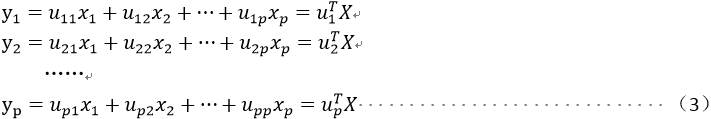
同时给出上述线性变换的矩阵形式如下

第二步:求解最大方差
新的数据![]() 的方差与协方差满足如下式子:
的方差与协方差满足如下式子:
![]()
假如我们希望y1的方差达到最大,则显然此问题是一个约束优化问题(二次优化问题)形式如下:
![]()
对式(7)的说明,注意这里的u表示的新的坐标系下的基向量(即为上述式(4)中举证的每一行元素组成),限制条件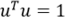 是为了使得基向量是单位向量,即长度为1 。
是为了使得基向量是单位向量,即长度为1 。
关于二次型在约束条件下的极值问题即求解上述式(7)有如下定理:
即在![]() 条件下,一般二次型
条件下,一般二次型![]() 的最大、最小值的求法:
的最大、最小值的求法:
定理1:设Λ是对称矩阵,令m = min{xTΛx:||x||=1},M = max{xTΛx:||x||=1},那么M是Λ的最大特征值λ1,m是Λ的最小特征值,如果x是对应M的单位特征向量u1,那么xTΛx的值为M,如果x是对应m的单位特征向量,xTΛx的值为m;
定理2:设Λ,λ1和u1如定理1所示。在条件xTx=1和xTu1=0限制下xTΛx最大值是第二大特征值λ2,且这个最大值,可以在对应λ2的特征向量u2处取到。
推论:设Λ是一个n*n的对称矩阵,且其正交对角化为Λ=PDP-1,将对角举证D上的元素重新排列,使得λ1 >=λ2 >=……>=λn,且P的列是其对应的单位特征向量u1,u2,……,un,那么对k-2,....n时,在条件xTx=1,xTu1=0,……xTuk=0限制下,xTΛx的最大特征值λk,且这个最大特征值在x=uk处可以取到。
上述定理1,定理2,推论的证明过程见求二次型最大最小值方法初探
由上述式(1)到式(7)的推导过程我们便将求解最大方差的问题转换为了求解协方差矩阵∑的特征值与特征向量。
设u1是∑最大特征值(设为λ1)的特征向量,此时y1为第一主成分,类似的希望y2的方差达到最大,并要求cov(y1,y2)=0,由于u1是λ1的特征向量,所以选择的u2应与u1正交,类似于前面的推导,a2是∑第二大特征值(设为λ2)的特征向量,称y2为第二主成分,依次类推得到后续主成分。
3、PCA降维步骤
由上述2、PCA原理推导,我们已经知晓,求解数据集的主成分的过程即为求解样本集协方差矩阵的特征值与特征向量的过程。
假设数据集为:

第一步:将样本数据中心化(为了简化运算,这部并不是必须的)
上述数据集已完成中心化
第二步:计算样本数据的协方差矩阵

第三步:求出协方差矩阵的特征值与正交单位特征向量
特征值:![]() ,对应的特征向量为:
,对应的特征向量为:![]()
特征值:![]() ,对应的特征向量为:
,对应的特征向量为:![]()
第四步:对上述协方差矩阵对角化
线性代数中定理:对于任意n阶实对称矩阵A,必然存在n阶正交矩阵P,使得:![]() ,其中
,其中![]() 为A的全部特征值;矩阵P为列向量组为A的n个标准正交的特征向量
为A的全部特征值;矩阵P为列向量组为A的n个标准正交的特征向量
由上述定理可知:

最大特征值为![]() ,对应的特征向量为
,对应的特征向量为![]() ,故第一主成分为:
,故第一主成分为:![]()
次大特征值为![]() ,对应的特征向量为
,对应的特征向量为![]() ,故第二主成分为:
,故第二主成分为:![]()

















 201
201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









