







一、背景
语义分割主要面临两个问题,第一是物体的多尺度问题,第二是DCNN的多次下采样会造成特征图分辨率变小,导致预测精度降低,边界信息丢失。DeepLab V3设计的ASPP模块较好的解决了第一个问题,而这里要介绍的DeepLabv3+则主要是为了解决第2个问题的。
对于DeepLabV3,如果Backbone为ResNet101,Stride=16将造成后面9层的特征图变大,后面9层的计算量变为原来的4倍大。而如果采用Stride=8,则后面78层的计算量都会变得很大。这就造成了DeepLabV3如果应用在大分辨率图像时非常耗时。所以为了改善这个缺点,deeplabv3+出现了。
二、网络架构
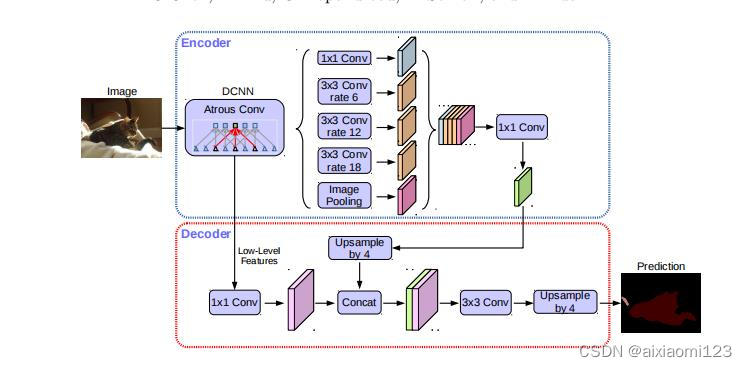
上图是deeplabv3+的网络架构。我们可以看到主要结构为encoder-decoder架构。
对于编码器部分,实际上就是DeepLabV3网络。图像进入主干网络后,获得两个特征层,浅层的特征层直接进入decoder中进行1*1卷积进行通道压缩,目的是减少低层级的比重。深层特征则在encoder编码器中进入aspp模块,论文认为编码器得到的feature具有更丰富的信息,所以编码器的feature应该有更高的比重。
在aspp模块中,包括了1个 1*1 卷积、3个 3*3 的Atrous convolution分别比率为6、12、18,以及一个图像全局的Pooling操作,这些操作过后是1个 1*1 卷积。
对于解码器部分,直接将编码器的输出上采样4倍,使其分辨率和低层级的feature一致。将两个特征层连接后,再进行一次3×3的卷积(细化作用),然后再次上采样就得到了像素级的预测。
1*1卷积的作用是升维或降维,使其与要结合的特征层保持一致。
三、创新
deeplabv3+创新主要在两个方面。
1、引入encoder-decoder结构
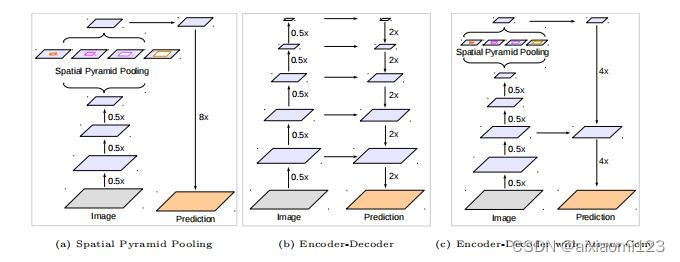
为了解决上面提到的DeepLabV3在分辨率图像的耗时过多的问题,DeepLabV3+在DeepLabV3的基础上加入了编码器。其中,(a)代表SPP结构,其中的8x是直接双线性插值操作,直接上采样得到预测结果。(b)是编解码器,融集合了高层和低层信息。(c)是DeepLabv3+采取的结构。
2、改进主干网络,使用xception作为主干网络
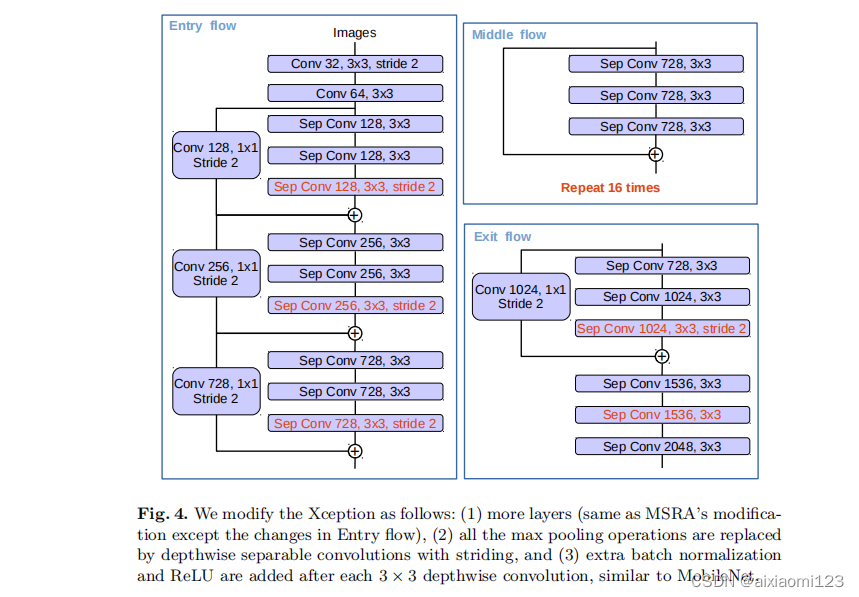
具体的改进工作如下:
- 更深的Xception结构,不同的地方在于不修改entry flow network的结构,为了快速计算和有效的使用内存
- 所有的最大池化操作替换成带下采样的深度分离卷积,这能够应用扩张分离卷积扩展feature的分辨率
- 在每个3 × 3 3×33×3的深度卷积后增加BN层和ReLU
最后将改进后的Xception作为encodet主干网络,替换原本DeepLabv3的ResNet101。
使用分离卷积改进Xception:
深度可分离卷积做的工作是:把标准卷积分解成深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。深度卷积对每个通道独立使用空间卷积,逐点卷积用于结合深度卷积的输出。深度分离卷积可以大幅度降低参数量和计算量。
将扩张卷积和深度分离卷积结合在一起,能够显著减少模型计算的复杂度并维持相似的表现。
四、实验
ResNet-101 as Network Backbone:
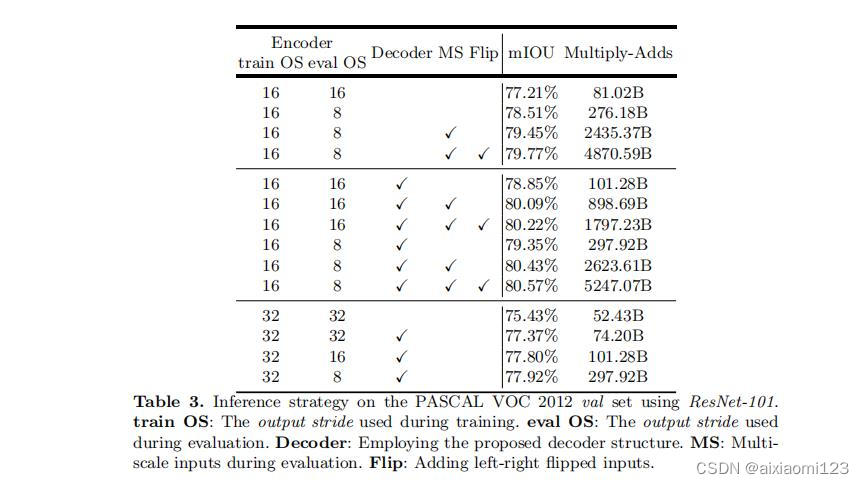
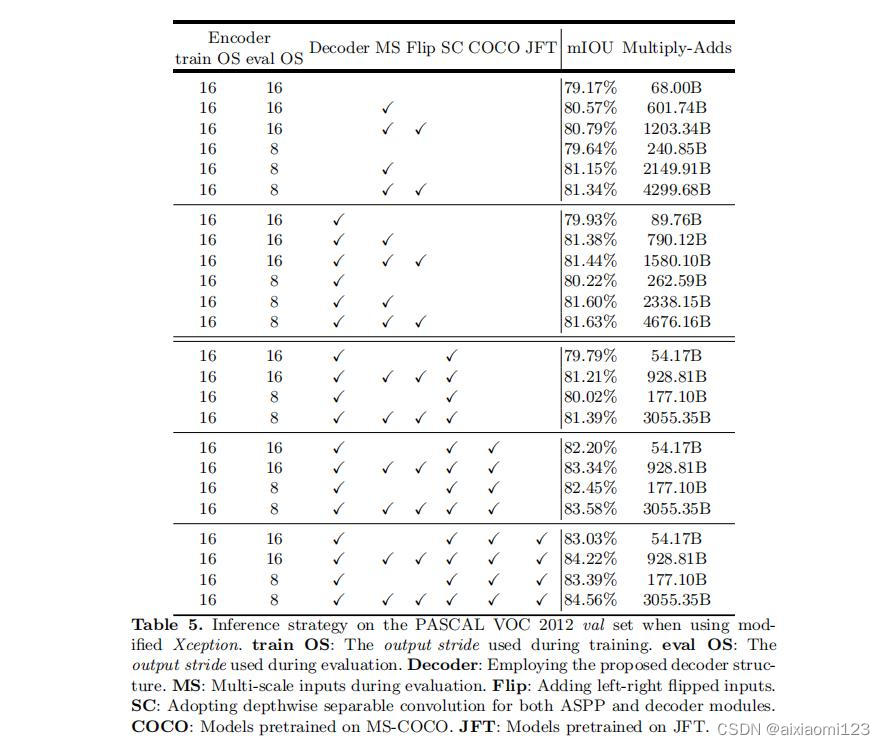

这里可以看到使用深度分离卷积可以显著降低计算消耗,同时使用Xception作为主干网络时误差也更小。
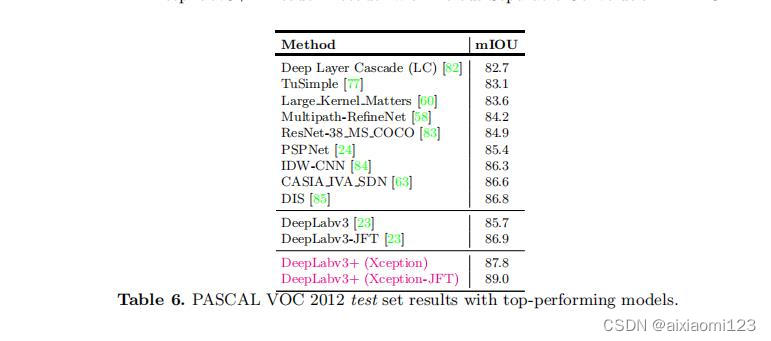
与其他先进模型在VOC12的测试集上对比:
Improvement along Object Boundaries :
使用trimap实验测量模型在分割边界的准确度。计算边界周围扩展频带(称为trimap)内的mIoU。结果如图a所示:
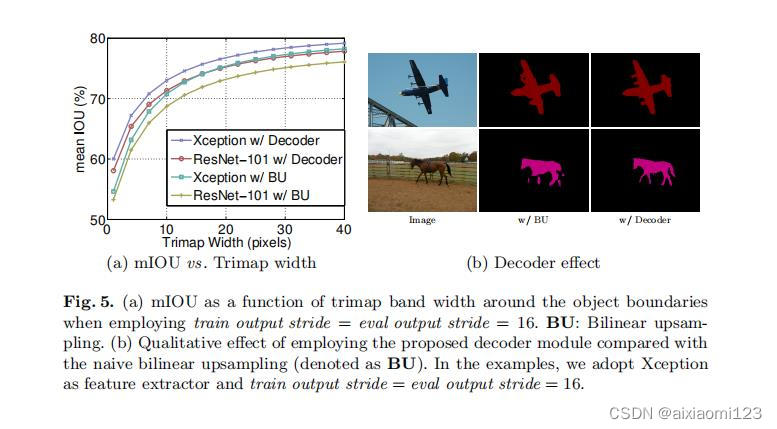
图b所示为图像经过双线上采样和加了decoder之后的结果对比,可以看出,加了decoder之后结果有明显的提升。
五、总结
论文提出的DeepLabv3+是encoder-decoder架构,其中encoder架构采用DeepLabv3,decoder采用一个简单却有效的模块用于恢复目标边界细节。并可使用扩张卷积在指定计算资源下控制feature的分辨率。论文探索了Xception和深度分离卷积在模型上的使用,进一步提高模型的速度和性能。模型在VOC2012上获得了新的state-of-the-art表现。
论文链接:原文链接

















 7264
7264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









