



 本文介绍了一个词法分析程序的设计与实现,该程序能够将源程序字符串解析为一系列的二元组,每个二元组包含词法单元的种别和单词本身。程序详细展示了词法分析的原理、流程图、主要算法和关键函数实现,以及如何处理不同类型的词法单元,如关键字、标识符、数字、运算符等。
本文介绍了一个词法分析程序的设计与实现,该程序能够将源程序字符串解析为一系列的二元组,每个二元组包含词法单元的种别和单词本身。程序详细展示了词法分析的原理、流程图、主要算法和关键函数实现,以及如何处理不同类型的词法单元,如关键字、标识符、数字、运算符等。
实验一、词法分析
一、 实验目的
编制一个词法分析程序
二、 实验内容和要求
输入:源程序字符串
输出:二元组(种别,单词本身)
待分析语言的词法规则
三、 实验方法、步骤及结果测试
1. 原理分析及流程图
主要总体设计问题。
(包括存储结构,主要算法,关键函数的实现等)
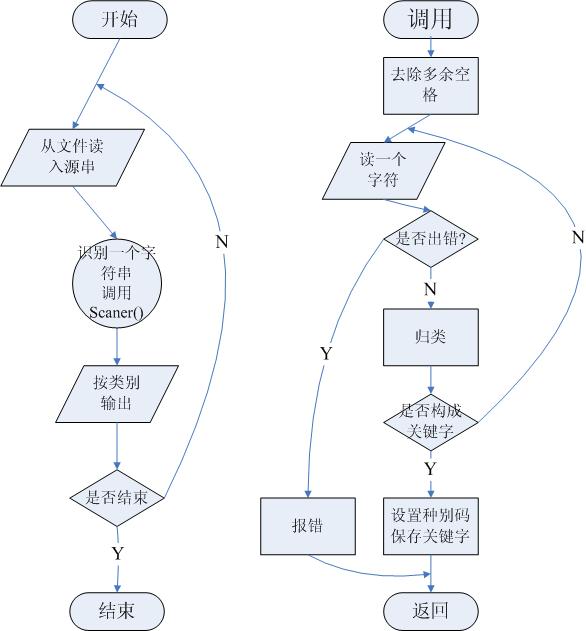
1. 主要程序段及其解释:
实现主要功能的程序段,重要的是程序的注释解释。
#include <stdio.h>
#include <string.h>
char prog[30],token[5],ch;
int syn,p,m,n,sum;
char *rwtab[6]={"begin","if","then","while","do","end"};
scaner();
main()
{p=0;
printf("请输入需要分析的字符串,以“#”结束):");
do{
scanf("%c",&ch);
prog[p++]=ch;
}while(ch!='#');
p=0;
do{ scaner();
switch(syn)
{ case 11:printf("( %-10d%5d )\n",sum,syn);
break;
case -1:printf("you have input a wrong string\n");
getch();
exit(0);
default: printf("( %-10s%5d )\n",token,syn);
break;
}
}while(syn!=0);
getch();
}
scaner()
{ sum=0;
for(m=0;m<8;m++)token[m++]=NULL;
ch=prog[p++];
m=0;
while((ch==' ')||(ch=='\n'))ch=prog[p++];
if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A')))
{
while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9')))
{
token[m++]=ch;
ch=prog[p++];
}
p--;
syn=10;
for(n=0;n<6;n++)
if(strcmp(token,rwtab[n])==0)
{ syn=n+1;
break;
}
}
else if((ch>='0')&&(ch<='9'))
{ while((ch>='0')&&(ch<='9'))
{ sum=sum*10+ch-'0';
ch=prog[p++];
}
p--;
syn=11;
}
else switch(ch)
{ case '<':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{
syn=22;
token[m++]=ch;
}
else
{
syn=20;
p--;
}
break;
case '>':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{ syn=24;
token[m++]=ch;
}
else
{ syn=23;
p--;
}
break;
case '+': token[m++]=ch;
ch=prog[p++];
if(ch=='+')
{ syn=17;
token[m++]=ch;
}
else
{ syn=13;
p--;
}
break;
case '-':token[m++]=ch;
ch=prog[p++];
if(ch=='-')
{ syn=29;
token[m++]=ch;
}
else
{ syn=14;
p--;
}
break;
case '!':ch=prog[p++];
if(ch=='=')
{ syn=21;
token[m++]=ch;
}
else
{ syn=31;
p--;
}
break;
case '=':token[m++]=ch;
ch=prog[p++];
if(ch=='=')
{ syn=25;
token[m++]=ch;
}
else
{ syn=18;
p--; }
break;
case '*': syn=15;
token[m++]=ch;
break;
case '/': syn=16;
token[m++]=ch;
break;
case '(': syn=27;
token[m++]=ch;
break;
case ')': syn=28;
token[m++]=ch;
break;
case '{': syn=5;
token[m++]=ch;
break;
case '}': syn=6;
token[m++]=ch;
break;
case ';': syn=26;
token[m++]=ch;
break;
case '\"': syn=30;
token[m++]=ch;
break;
case '#': syn=0;
token[m++]=ch;
break;
case ':':syn=17;
token[m++]=ch;
break;
default: syn=-1;
break;
}
token[m++]='\0';
}
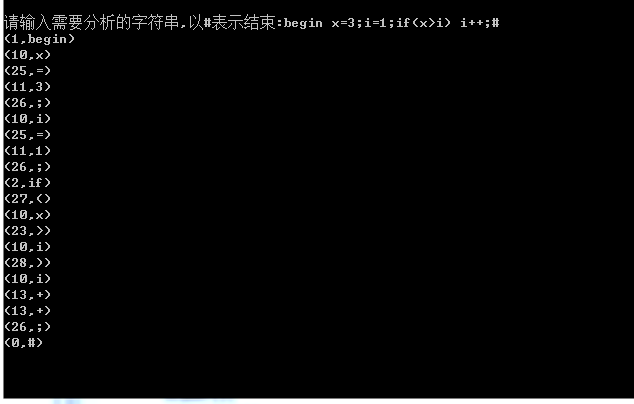
2. 运行结果及分析
一般必须配运行结果截图,结果是否符合预期及其分析。
(截图需根据实际,截取有代表性的测试例子)

















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









