









前言
很久之前就想实现一个小的搜索引擎供自己使用,一来代码量不大,二来也可以屏蔽一些广告。因此在春节期间,在同学提供前端的帮助下,一个小的搜索引擎系统就成型啦。做出来之后总体效果也符合我之前的预期,但引擎的核心部分取了巧,并不是自己去实现的权重排序,而是通过爬虫去抓取其他搜索引擎的结果,算是小小的遗憾,以后有机会自己在补上。
效果预览
先放几张效果图(需要代码的同学可以评论留下邮箱):
- 主页
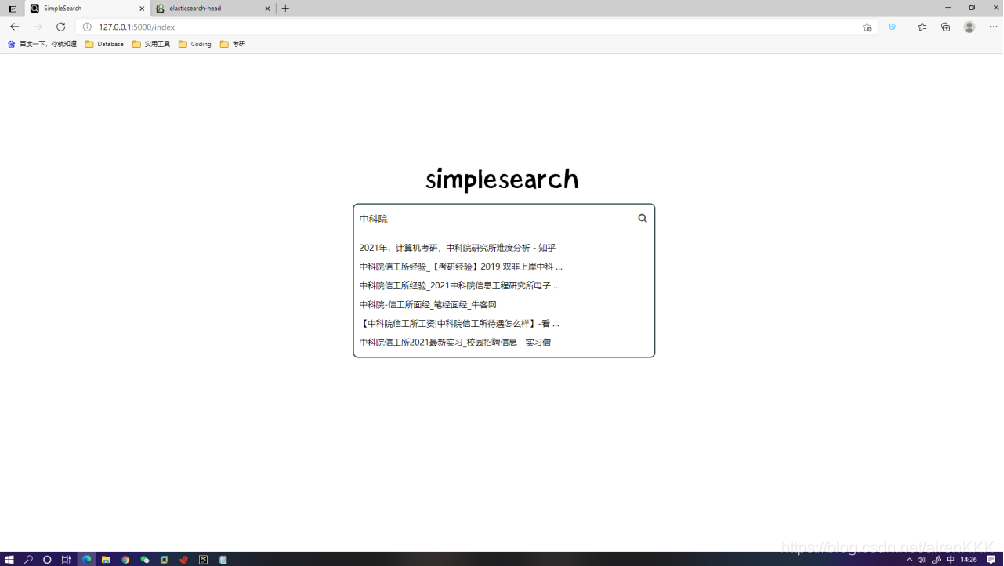
- 搜索页1
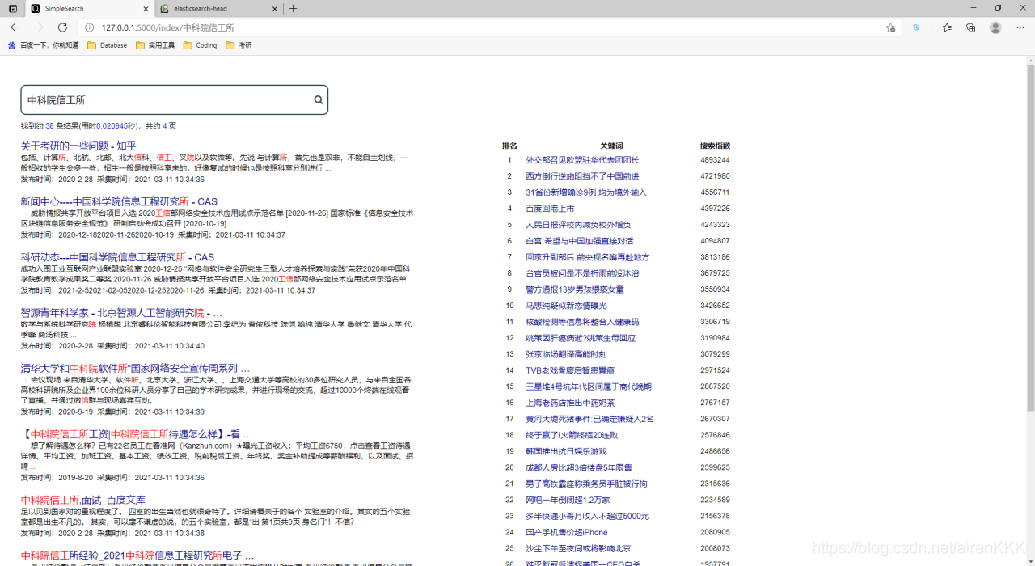
- 搜索页2
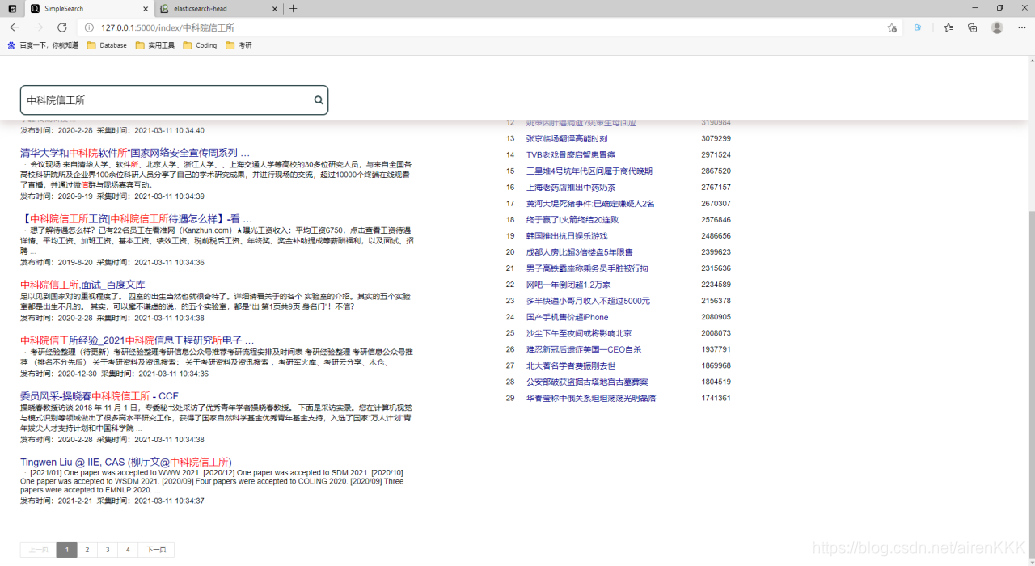
总体功能
- 共分为两个部分,主页和结果页
- 搜索框实现了搜索建议补全
- 关键词未命中es时,会启动scrapy爬虫去抓取必应的搜索结果,同时存入es(elasticsearch,下文统一用es来简写)。所以第一次的相应时间会相对长一些
- 关键词命中es时,直接从es获取结果,毫秒级响应,同时将命中的部分高亮处理。
- 前后端同时分页,跳页时前端只会向后台请求对应页的搜索结果,减少web传输内容。
- 跳页时局部渲染html,减少响应时间。
- 实时获取百度热搜榜
环境与版本号
该项目用到了 flask+es+scrapy+python+linux
- 虚拟机:vmware14.0,主要用来跑es
- linux:7.2,内核版本为 3.10.0-327.el7.x86_64,查看内核版本命令:cat /proc/version
- python:3.7.4,用于主程序的开发
- flask:1.1.1,用于整体web框架的构建
- es:7.10.2,存储数据
- scrapy:2.4.1,爬虫程序构建,用于抓取搜索结果存入es
- jquery:2.1.0,用于前端主体
- layui:2.6.4,使用了分页组件
本机环境为win10专业版,IDE为pycharm,为了项目兼容运行,复现的同学最好搭建版本号相同或者相近的环境。

















 509
509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









