




——当算力从机房回到每个人手里,架构的命运也开始改变
1. 这一切的转折,都从一次看似普通的推理部署开始
我第一次真正意识到“AI 推理与传统 CPU 世界格格不入”,是在一个并不宏大的项目里。那时我们要把一个 7B 的模型塞进边缘设备上运行,想当然地认为“推理嘛,让 x86 服务器顶着就行”。直到我们把负载打开、看着 CPU 风扇像直升机一样狂转、推理延迟飘忽、功耗像失控的水龙头,我们才察觉:问题不在模型,而在架构。
推理的节奏很奇怪,它不像数据库那样充满分支,也不像游戏逻辑那样需要大量随机执行。反而更像一条规则清晰的河,你给它矩阵,它就哗啦啦算下去;你给它 KV 缓存,它就稳稳取出来;它最怕的不是 CPU 不够强,而是访存不稳定、功耗不耐跑,以及那些 CPU 为通用计算准备的“聪明但累赘”的特性。
那一刻我意识到一个更深的现实:
AI 推理需要的不是一台强大的 CPU,而是一套能和推理节奏合拍的体系。
这也正是 ARM 悄悄走红的原因。
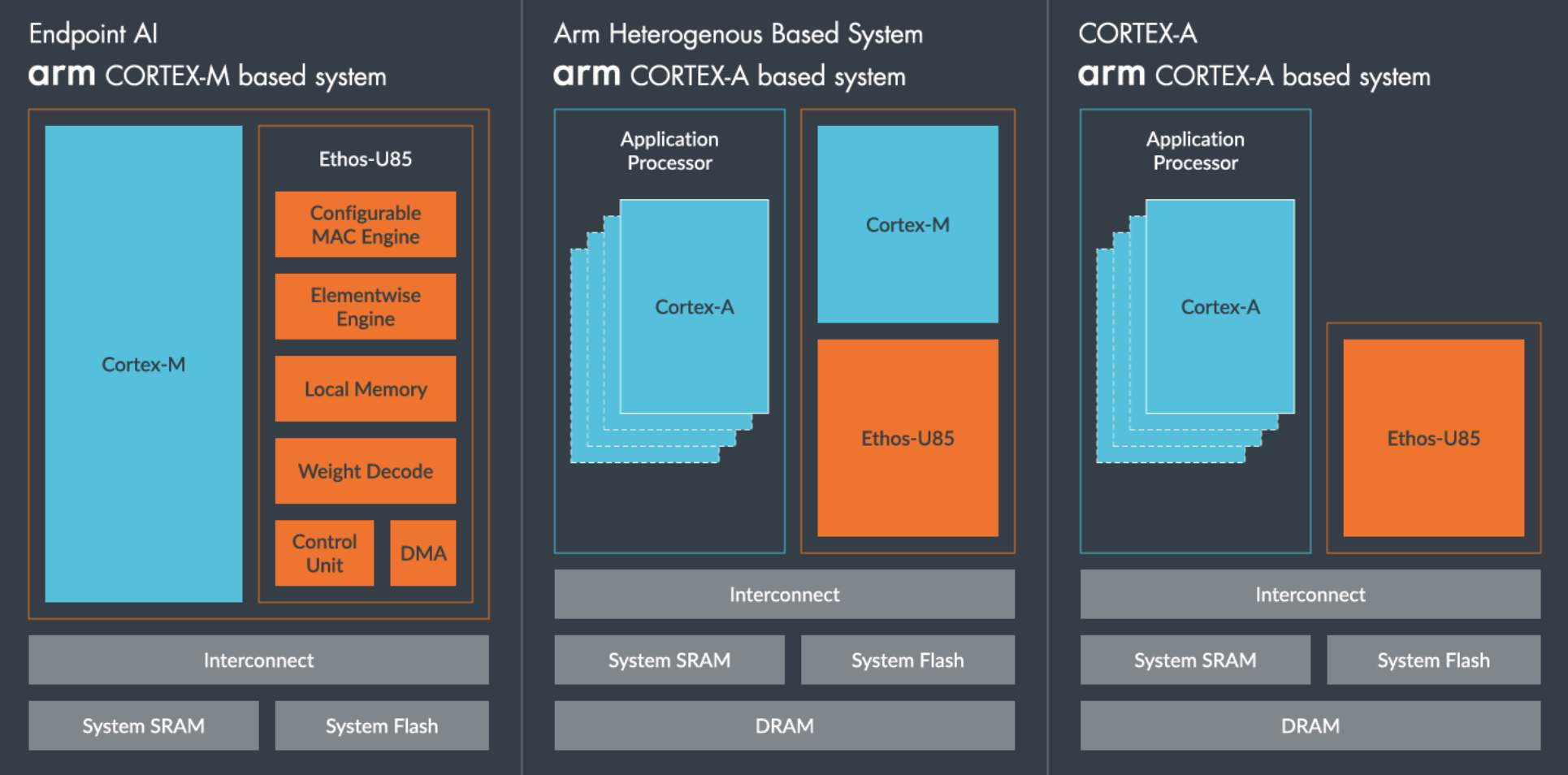
2. ARM 与推理之间的和弦:一种结构性匹配
你只要真正把推理拆开,就能看到它和 ARM 的契合是从底层结构开始的,而不是因为某个厂商的市场推广。矩阵乘法的密集性、访存的确定性、执行路径的单调性,这些特点让推理更像是“稳定长跑”,而不是“短跑 + 障碍赛”。
传统的 x86 CPU,把大量硅面积和功耗预算都压在复杂乱序执行、深度管线、分支预测和兼容性上,它像一个被训练得极端全面的钢琴家——能弹复杂曲子、能处理极端逻辑、能解决所有通用场景。但问题是:AI 推理不是钢琴曲。
它需要的是强劲的持续流量、可预测的节奏和低功耗的体质。ARM 这类轻量而规整的 RISC 架构,从来不喜欢用“聪明的硬件”压
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









