 参数量B的真相:不只是数字大小
参数量B的真相:不只是数字大小





一、首先,B 是什么?
我们在 AI 圈经常看到这样的话:
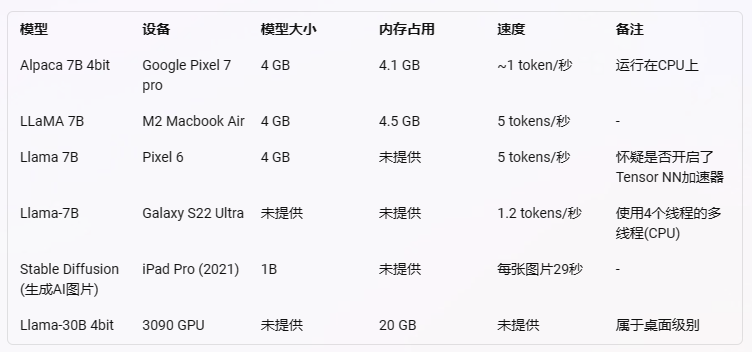
GPT-3 是 175B 模型。
LLaMA2-7B 可以本地跑。
DeepSeek-R1 有 67B 版本。
这里的 B = Billion = 十亿(10⁹)个参数。
每个参数本质上就是一个数,一个权重值(weight),通常是浮点数(float)。
如果你听到一个模型是 “7B”,那意味着它大约有 7 × 10⁹ ≈ 7,000,000,000 个这样的浮点权重。
二、参数量怎么换算成显存需求?
我们可以用一个简单的公式:
显存占用 ≈ 参数量 × 每个参数字节数 × 复制系数
一般来说:
| 精度类型 | 每参数字节 | 说明 |
|---|---|---|
| FP32 | 4 bytes | 训练时常用(高精度) |
| FP16 | 2 bytes | 半精度推理 |
| INT8 | 1 byte | 量化后推理 |
| INT4 | 0.5 byte | 极限压缩量化 |
假设我们跑一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









