







Redis Java客户端介绍
jedis、redission 、lettuce
三种客户端有啥区别?
jedis:用的比较多的一种客户端,它是直接通过socket去建立一个会话,然后通过直接发布一些命令去做数据的查询,里面用到了线程池
redission: 实现了分布式可扩展的java数据结构,这个客户端和之前讲过的zookeeper客户端curator类似,不仅提供了基础操作命令,还提供了基于redis能够去实现的功能,比如分布式锁、队列、原子递增、全局id等。
lettuce:基于netty构建的可伸缩线程安全的redis客户端,支持同步、异步和响应式
Redis分布式锁
我们不是说redis只能实现分布式锁,只是说我们可以利用redis的一些特性去实现这个功能
锁的特性:
-
获得锁和释放锁
-
具备超时时间(避免死锁)
-
判断是否重入(释放锁的线程是不是获得锁的线程)
什么是分布式锁?
在跨进程的分布式架构下,我们要保证共享资源的原子性操作
分布式锁的几种实现方式?
数据库、zookeeper(节点的唯一性和节点的有序性)、redis(setnx),利用其中的特性可以实现
synchronized、lock api 可以在单进程多线程环境下用过这两个实现多线程并行执行的情况下的线程安全问题
在分布式的架构,多进程的情况下,对一些共享资源访问的时候,需要控制,保护一些共享资源,去实现线程安全问题,最简单的应用场景就是库存扣减
Redis的管道模式
之前说过影响redis最大的因素是网络开销
管道模式
在单机连接下是有效果的
如果redis服务器是单机的,没有做分片,做主从的模式下,可以通过pipeline实现一些操作之前讲过redis影响性能的最大因素是网络开销,我们通过网络传输命令,执行结果返回过来以后,如果你的key数据很大的话,那么你对应的返回网络通信过程会比较慢,可以通过管道方式实现只交互
一次的请求,把多个请求放到一个管道里方送过去,减少网络的交互
示例代码:
public class JedisConnectionUtils {
private static JedisPool pool = null;
static {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(100);
pool = new JedisPool(jedisPoolConfig, "192.168.184.129", 6379);
}
public static Jedis getJedis(){
return pool.getResource();
}
}
public class PipelineDemo {
public static void main(String[] args) {
Jedis jedis = JedisConnectionUtils.getJedis();
Pipeline pipeline = jedis.pipelined();
pipeline.set("aa","1");
pipeline.set("bb","1");
pipeline.set("bb","1");
pipeline.set("dd","1");
pipeline.set("ee","1");
pipeline.set("ff","1");
pipeline.sync();//发送请求
}
}
Redis 的应用架构
会把redis放到应用和数据库之间,应用和数据库之间的缓存,可以是数据库中一些热点数据或者经常访问,查询比较复杂的数据,效率比较低的操作,会把这些数据放到缓存里来,那么应用层访问数据的时候,先去访问缓存,缓存中不存在,再去访问数据库
缓存命中率 = 命中缓存个数/总缓存访问个数
怎样提高缓存命中率?
- 对一些热点数据做预判,做预热,初始化加载的时候就把这些热点数据都加载到内存(缓存)里面,可以把根据数据监控的结果预热到缓存里面,命中率一定会提升
需要考虑的问题?
-
数据库的数据和缓存中的数据的一致性问题(业务问题)最终一致性
无法保证强一致性(保证同时成功,同时失败),两种不同的协议的容器
强一致性也是没有必要的,本来加缓存就是为了提升性能,现在如果加个强一致性又会导致性能下降的一个问题,所以又存在一个取舍问题,这个问题不是技术问题,而是业务问题
-
更新缓存还是让缓存失效(两个问题)
怎样取舍?如果更新缓存的代价本身很小的话,那么可以先更新缓存;更新缓存代价大的话,先操作数据库,再让缓存失效
-
先操作数据库还是先操作缓存(哪一种对业务的影响更小)
怎样取舍?不管先操作哪个都会发生一致性问题,比如先更新数据库,再更新缓存,缓存失败怎么办?先更新缓存,再更新数据库,数据库失败怎么办?
这个问题要分析,不同的业务场景它的处理方式不一样,具体问题具体分析
怎样保证最终一致性?
通过消息队列的方式,把更新失败的结果放到队列中,然后再从队列中去出失败的消息进行自身消费,拿到消息之后再次发起重试
消息队列是一个可靠的队列,因为消息发送到队列上面,如果没有被消费掉的话,会一直存在,这个就是最终一致性的体现。 -
-
redis缓存完全挂掉怎么办?
-
redis集群或者其他高可用的方案
-
多级缓存,可以基于redis+memcache,可以基于内存缓存等做这样一个处理
多级缓存的概念:
- 可以利用不同的缓存中间件去存储不同的缓存数据类型
- 其中一个缓存失效的时候可以有另外一个缓存去支撑
-
-
缓存雪崩(自身问题)
如果缓存的体量很大,而缓存里面很多key超时时间是相同的,会导致在同一个时刻,很多的缓存同时失效,这个地方的失效会造成一个问题,所有的逻辑会穿透到数据库层,如果数据库方面没有做应对方法,那么这个时候就有可能因为压力过大导致数据库层面崩溃。
缓存雪崩怎么解决?
首先,找到原因:同一时间,大面积的key失效导致所有的请求都落在数据库,导致缓存雪崩的问题
- 从缓存中取不到值的时候,加锁,加锁的目的:当访问并发量非常大,这个值又不存在,加锁排队访问,避免后续所有请求全部往后面去打,而是先给排队到应用层,加锁让第一个线程从数据库中获取到值并更新到缓存里面,后续的请求直接从缓存中读取数据,这个地方加锁会导致性能的损耗,这个地方也是一个取舍问题(业务问题)
- 过期时间做一个随机分配或缓存时间的合理分配,降低缓存过期时间一致性的问题,可以做些监控
-
缓存穿透(自身问题+有恶意的情况)
产生原因:很多个请求访问缓存的时候,key都不存在,相当于客户端这边有些恶意的请求,也可以认为它的缓存命中率很低,低到无法忍受
-
对空值做缓存,缓存的结果可以设置一个特殊字符,这个特殊字符就是,我知道下次获取到这个特殊字符值的时候就表示当前的key是一个无效的key,不做处理,特殊字符有超时时间,相当于对一段时间内的相同请求可以做一个阻挡,缓解
-
设置key的规则,判断请求过来的key是否满足规则,不满足则不请求到后台,是一种规避手段
-
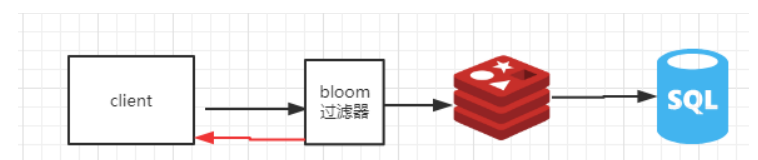
布隆过滤器,有点类似内存缓存的概念,相当于在布隆过滤器里面去缓存当前场景里面的所有key,然后所有请求先去过滤器里面去看,当前key是否在过滤器里面,如果在的话再把请求落到后端
布隆过滤器(空间效率极高的一种概率性算法):
最核心的还是一种算法,有点类似前面讲过的压缩算法,
存储40亿的数据,一个数占4个比特位,内存需要16Gbitmap(位图)
利用32个比特位去存储32个十进制数据
-
存1000000的数据,需要从这里面申请多少个数组呢?
x[1000000/32+1],映射,值在数组里面的映射关系
5/32-x[0]
5%32=5
-
-
认识布隆过滤器
实际上就是bitmap+hash的映射
有了对位图的理解以后,我们对布隆过滤器的原理理解就会更容易了,仍然以前面提到的40亿数据为案例,假设这
40亿数据为某邮件服务器的黑名单数据,邮件服务需要根据邮箱地址来判断当前邮箱是否属于垃圾邮件。原理如下
假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于
集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数
组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈
希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果
3个点都为1,则该元素可能存在集合中
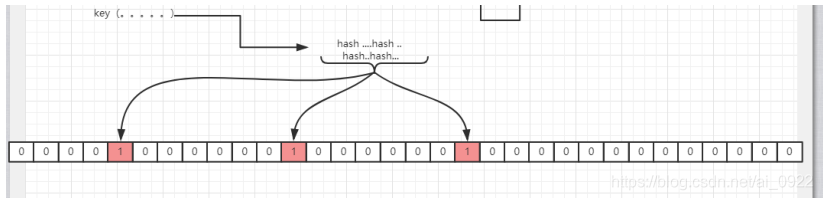
接下来按照该方法处理所有的输入对象,每个对象都可能把bitMap中一些白位置涂黑,也可能会遇到已经涂黑的
位置,遇到已经为黑的让他继续为黑即可。处理完所有的输入对象之后,在bitMap中可能已经有相当多的位置已
经被涂黑。至此,一个布隆过滤器生成完成,这个布隆过滤器代表之前所有输入对象组成的集合。
如何去判断一个元素是否存在bit array中呢? 原理是一样,根据k个哈希函数去得到的结果,如果所有的结果都是
1,表示这个元素可能(假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3
个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1)存在。 如果
一旦发现其中一个比特位的元素是0,表示这个元素一定不存在
至于k个哈希函数的取值为多少,能够最大化的降低错误率(因为哈希函数越多,映射冲突会越少),这个地方就
会涉及到最优的哈希函数个数的一个算法逻辑

















 1128
1128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









