 使用Python爬取国家数据统计局接口:时间戳与随机数策略
使用Python爬取国家数据统计局接口:时间戳与随机数策略




 本文介绍了如何通过分析接口数据,利用时间戳和随机数生成动态参数,编写Python代码爬取国家数据统计网站的数据,以避免被识别为机器人。作者详细展示了获取接口参数、生成URL和解析抓取结果的过程。
本文介绍了如何通过分析接口数据,利用时间戳和随机数生成动态参数,编写Python代码爬取国家数据统计网站的数据,以避免被识别为机器人。作者详细展示了获取接口参数、生成URL和解析抓取结果的过程。
一、分析接口数据
1、打开国家数据统计网站,并展开要抓取的数据:
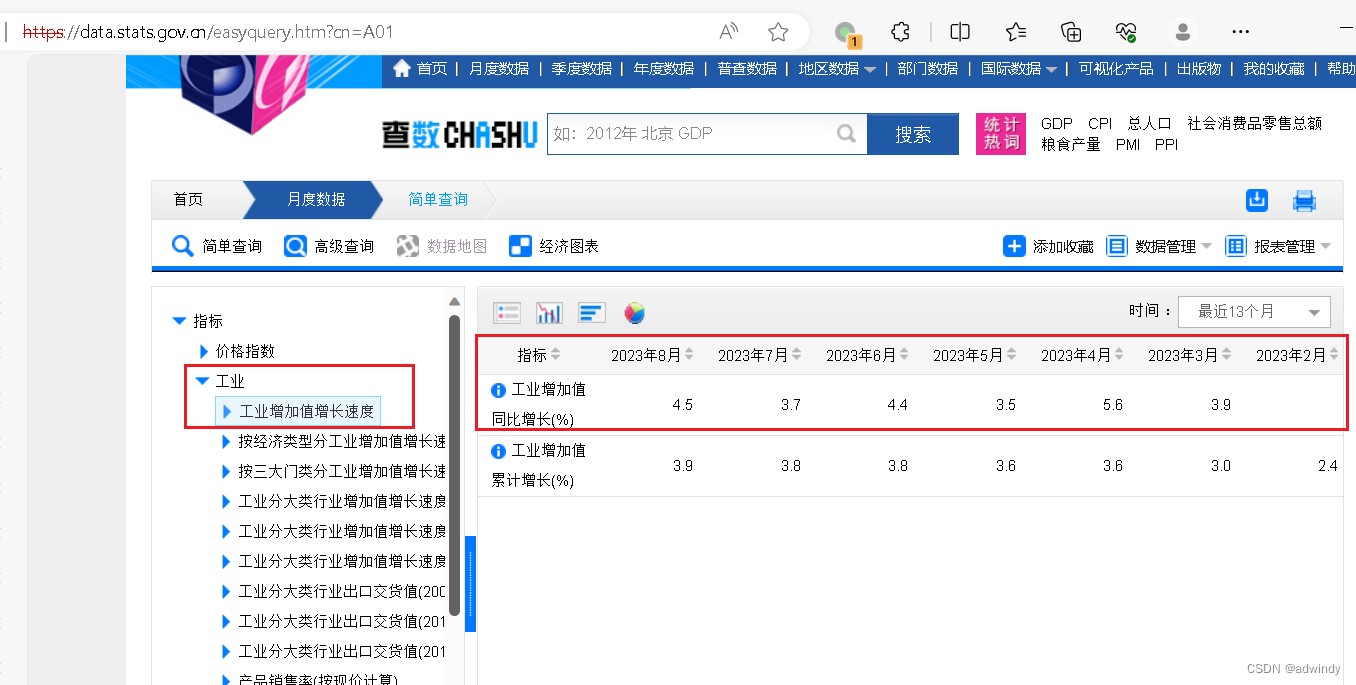 2、按F12打开开发者工具,在页面左边重新点击【工业增加值增长速度】,让页面重新获取接口,在F12中就看到抓取的接口目标:
2、按F12打开开发者工具,在页面左边重新点击【工业增加值增长速度】,让页面重新获取接口,在F12中就看到抓取的接口目标:
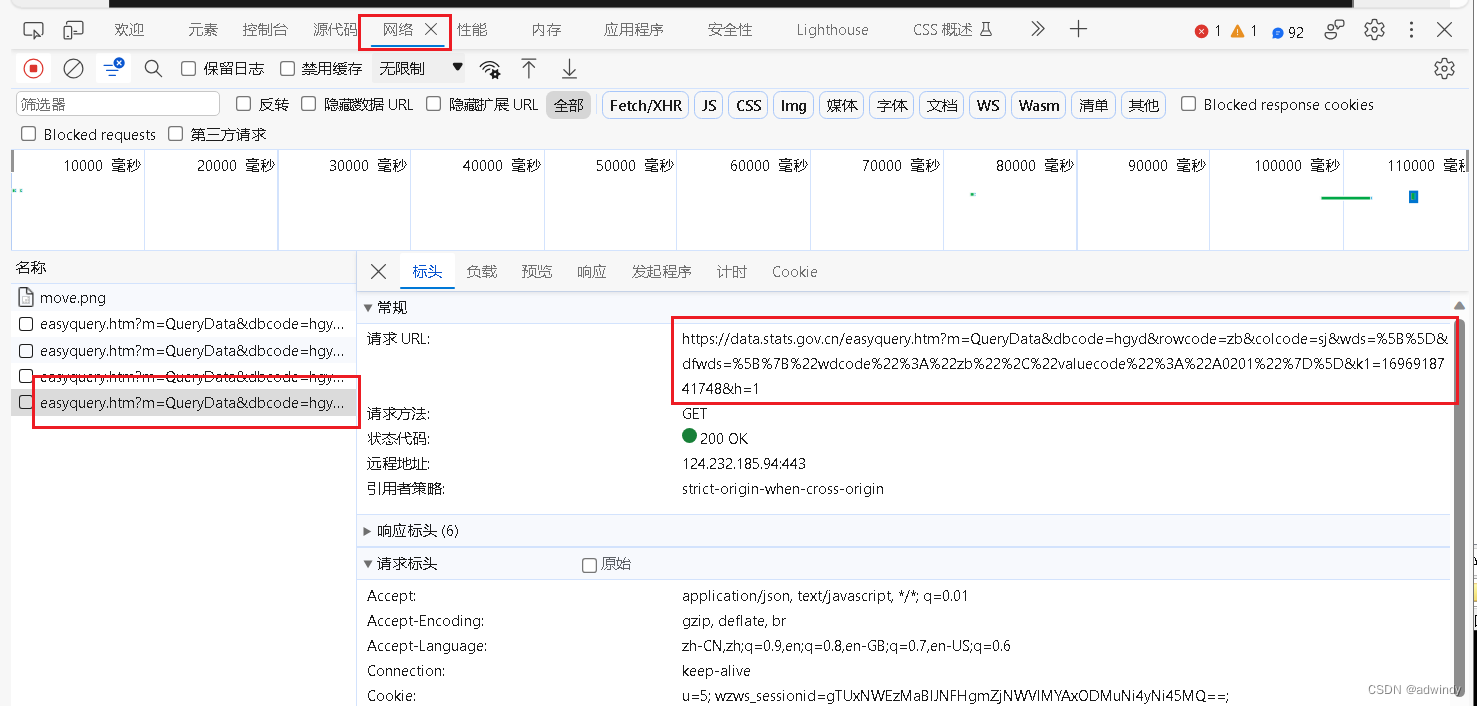
3、我们分析一下接口的参数:
https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgyd&rowcode=zb&colcode=sj&wds=%5B%5D&dfwds=%5B%7B%22wdcode%22%3A%22zb%22%2C%22valuecode%22%3A%22A0201%22%7D%5D&k1=1696918741748&h=1
我们看到这个接口url,前面的是一些获取目标数据的参数,我们不用管,看看后面的k1=1696918741748,我们分析了一下,发现每次获取,这个参数都会变,再和时间戳对比一下,原来是时间戳后面加上3位数。
二、编写爬取代码
import time
import random
import json
import requests
# 获取当前时间戳(秒级)
timestamp = int(time.time())
# 生成3位随机数(范围在000到999之间)
random_number = random.randint(0, 999)
# 将随机数格式化为3位,不足3位时在前面补0
random_number_str = f"{random_number:03d}"
# 合并时间戳和随机数
timestamp3 = f"{timestamp}{random_number_str}"
url=f'https://data.stats.gov.cn/easyquery.htm?m=QueryData&dbcode=hgyd&rowcode=zb&colcode=sj&wds=%5B%5D&dfwds=%5B%7B%22wdcode%22%3A%22zb%22%2C%22valuecode%22%3A%22A0201%22%7D%5D&k1={timestamp3}&h=1'
print(url)
json_string=myclass.mySpider.catchItem(url)
print(json_string)
data = json.loads(json_string)
# 获取datanodes数据
datanodes = data["returndata"]["datanodes"]
# 初始化一个空列表来存储处理后的数据
formatted_data = []
# 遍历datanodes数据并筛选、转换
for node in datanodes:
if node["code"].startswith("zb.A020101_sj") and node["data"]["hasdata"]:
# 从code的后6位获取月份
month = node["code"][-6:]
# 获取strdata
strdata = node["data"]["strdata"]
# 添加到格式化数据列表
formatted_data.append((month, strdata))
# 输出格式化后的数据
for item in formatted_data:
print(f"月份: {item[0]}, strdata: {item[1]}") 我们把上面的代码放到vscode里执行,如下图所示,可以正常抓取取想要的数据了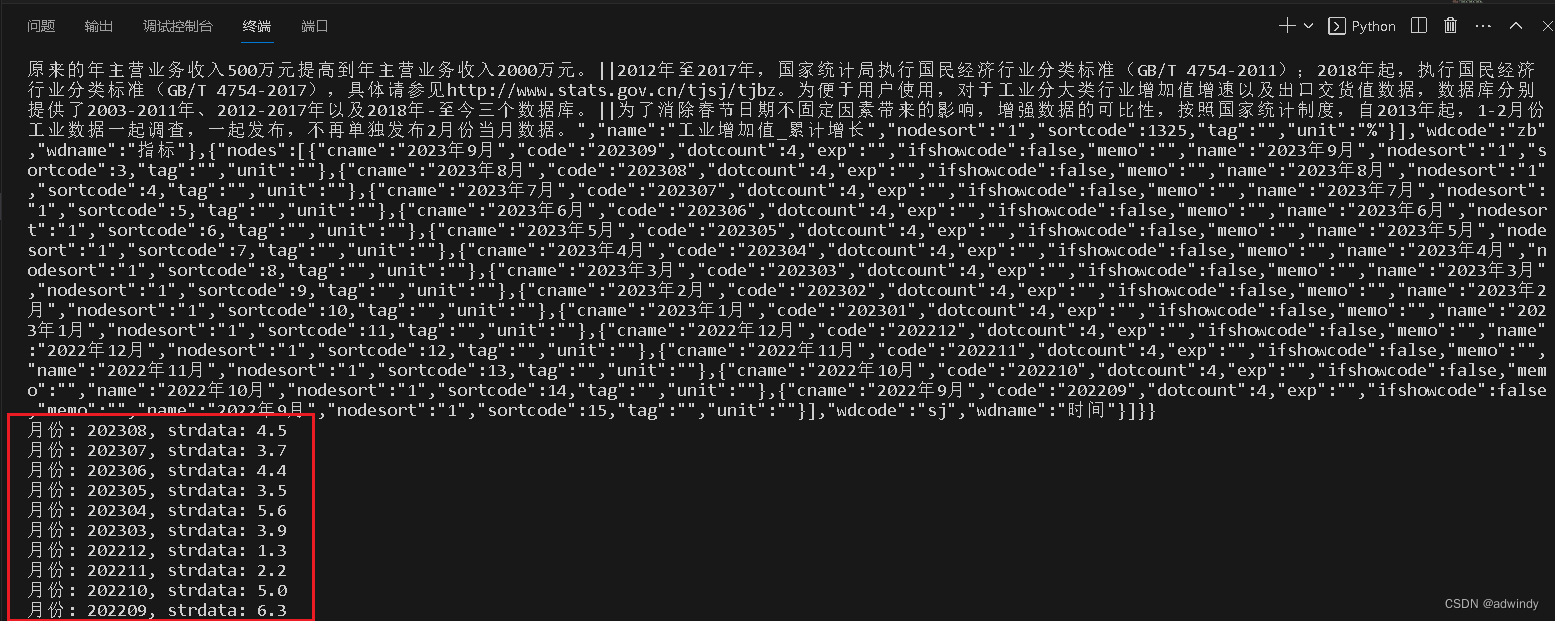



















 829
829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









